LaserTagger: 文本生成任务的序列标注解决方案
今天要和大家分享的是2019年Google Research的一篇关于文本生成的论文[1],已开源[2]。
论文提出了一个解决文本生成任务的新方法。新方法将文本生成任务转换为序列标注任务,并且推断速度极快可以达到目前常用的序列到序列 (seq2seq) 模型的100倍,所以被命名为LaserTagger。
值得一提的是,论文中的实验表明LaserTagger使用几千条训练数据就可以达到seq2seq模型使用几万条训练数据的性能。这对于实际项目的应用是个非常好的消息。
想解决的问题
序列到序列 (seq2seq) 模型是目前多种文本生成任务的首选,特别是结合预训练语言模型的使用,大大提升了文本生成的质量。这里推荐大家阅读并持续关注我们晴天1号的预训练语言模型系列文章。
但是seq2seq模型仍有一些重大问题。
-
“幻觉”(Hallucination)
即模型的部分输出与输入无关。主要原因是seq2seq模型的输出可能性太多,输出的内容和长度都不可控制。seq2seq很容易输出一些通顺但没有意义,或意义与输入完全不同的句子,这在一些对准确率要求比较高的场景中是非常危险的。
-
需要大量的训练数据
seq2seq模型十分复杂,参数量大。需要大量的训练数据来充分学习,保证生成的文本质量。然而,大多数场景下,很难获得足够的高质量的标注数据。
-
逐字预测,推断速度慢
seq2seq模型需要逐字地生成文本,后一个字的预测依赖前一个字的预测结果,推断速度较慢。在需要高度实时性的应用场景,很难符合要求。
LaserTagger的思路
论文作者发现,在一些文本生成任务中(如,句子融合,拆分和改述等),输出和输入的文本高度重合。对于这些任务,seq2seq模型的复杂结构似乎有一些浪费。由此想到,可以将这些文本生成任务转变成文本序列标注任务。
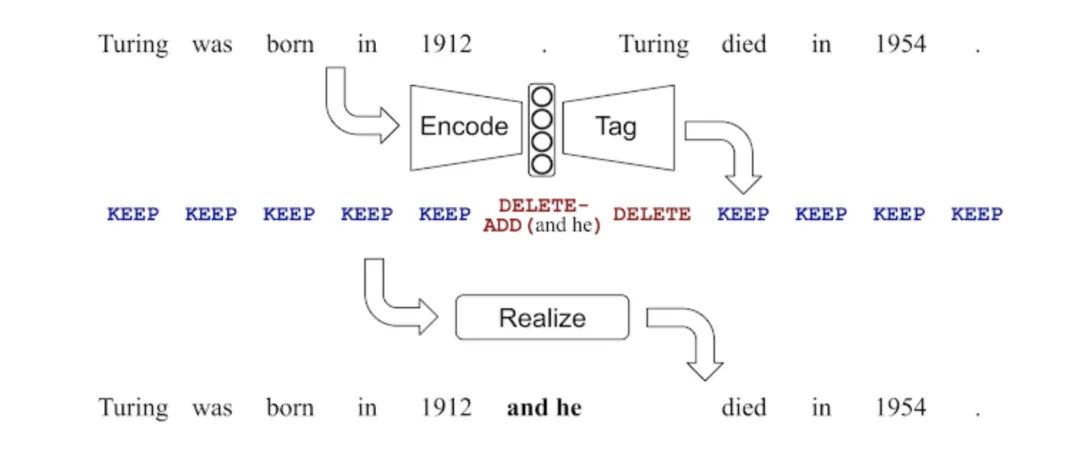
首先对输入文本进行序列标注生成每个英文单词对应的编辑标签。编辑标签包括KEEP(保留单词)和DELETE(删除单词)两个基本标签。若需要在单词前添加词组,在基本标签后加上ADD(X)(在对应单词前添加词组X,X出自一个经过严格挑选的有限词组集);再运用简单的规则,结合输入文本和编辑标签得到输出文本。
如下图所示,除了保留大部分原文本的内容外,删除第一个句号,并在句号位置前添加and he,然后将句号后的Turing删除。这样就成功地将两句句子合并成一句。
有限词组集的选择
ADD标签能够添加的所有词组组成一个有限的词组集。不同的文本生成任务和不同的数据集需要不同的词组集。由标注数据中获取词组集,有两个优化目标。
-
最小化词组集中的词组总数。
-
最大化词组集能重构的标注数据数量。
那如何达到这两个优化目标呢?第一步,找出输入和输出文本序列的最长公共子序列(longest common subsequence,LCS),将输出文本中不在LCS中的词组组成候选词组列表;第二步,根据词组在标注数据中出现的次数将候选词组排序。在训练时,取出现次数最多的n个词组组成有限词组集。
论文指出,逐一取增加覆盖标注数据数量最多的词组的贪婪方法在这里并不可取。因为有些词组之间是强绑定的(如,左括号“(”和右括号“)”),单独一个不会增加覆盖的标注数据数量,但是合并在一起就很常见。
下图是在四个文本生成任务中,排名前15的可添加词组。

文本序列标注模型结构
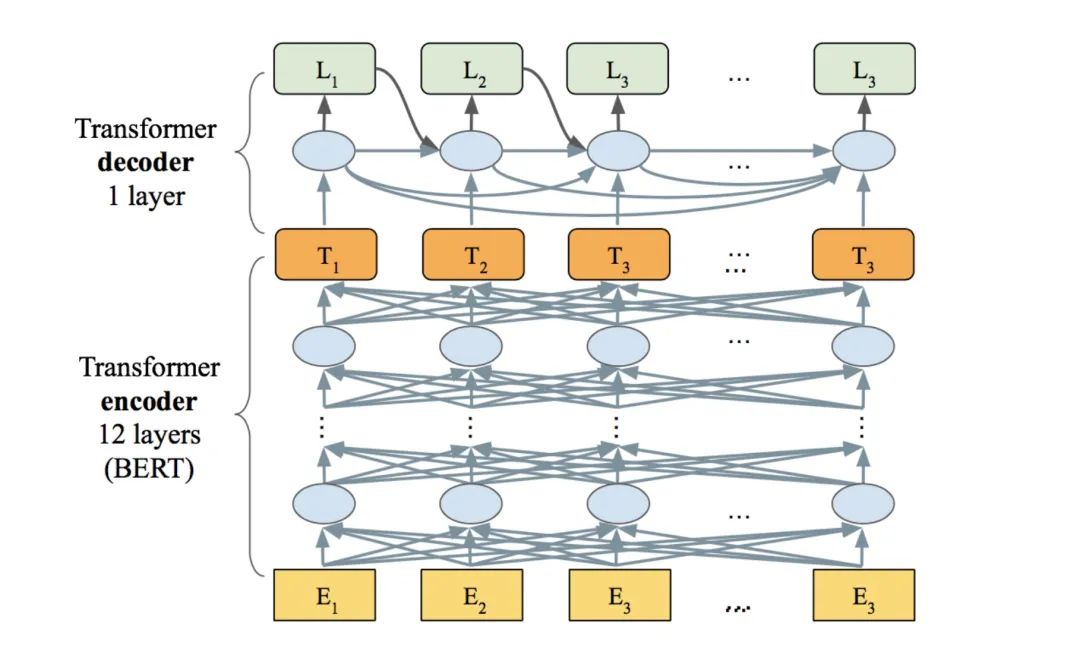
模型的encoder选用Bert Transformer[3]模型,是BERT-base结构,包括12层self-attention,并用预训练的大小写敏感的BERT-base模型进行初始化。
论文尝试了两种decoder结构:
-
LaserTagger(FF)
采用一层feed-forward作为decoder,直接取encoder logits的argmax,当前step的预测和其它step无关。因此,输出标签的预测互相独立,速度非常快。
-
LaserTagger(AR)
采用一层autoregressive Transformer作为decoder,如下图。取前一个step的预测标签embedding和当前step的encoder activation进行预测。因为LaserTagger(AR)模型decoder的结构更复杂,所以会比LaserTagger(FF)模型的预测更准确。
实验结果
论文在句子融合,拆分和改述,摘要总结,和语法纠错四个文本生成任务进行实验,将LaserTagger和每个任务各自的当前最高水平(state-of-the-art, SOTA)进行比较。LaserTagger的实验结果超过了其中三个任务的SOTA。
与此同时,论文还用BERT Transformer model训练了一个性能十分优秀的seq2seq baseline (Seq2SeqBERT)。Seq2SeqBERT使用和LaserTagger一样的初始化方法和各种细节,保证LaserTagger方法和seq2seq方法的公平比较。
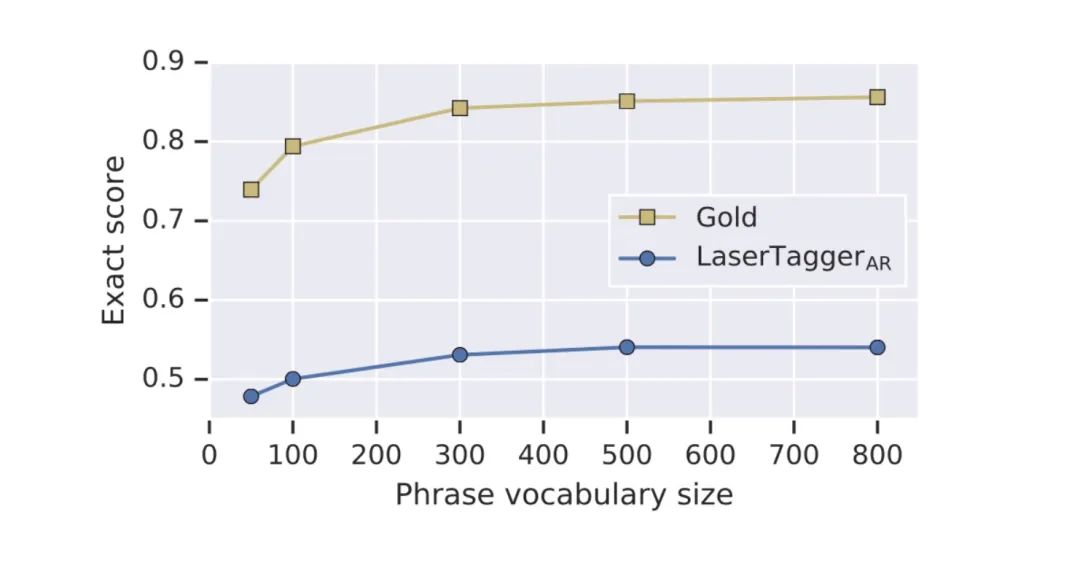
首先,在句子融合任务的DfWiki数据集上,对有限词组集大小的影响进行了实验。在下图中,Gold指当前词组集大小能够重构的样本比例。可以看出,词组数量达到500后,模型的性能和词组集能够覆盖的样本比例都趋于平稳。
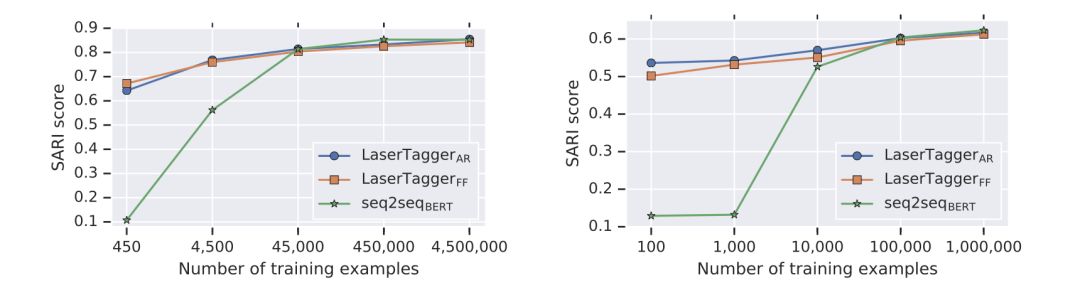
由不同训练数据数量的实验可以看出(见下图),全量数据时,Seq2SeqBERT结果和LaserTagger(AR)结果相当;当数据量减少,LaserTagger(FF&AR)会比Seq2SeqBERT结果好很多。
在推断时间方面,由下图可知,LaserTagger(FF)比LaserTagger(AR)快10倍,比Seq2SeqBERT快100倍;LaserTagger(AR)比Seq2SeqBERT快10倍以上。

读后感
由LaserTagger的思路和实验结果可以看出,开头列举的seq2seq的三大问题都有了很好的解决。有限的词组集使得模型结果可控制,可解释,缓解了“幻觉”的现象;LaserTagger使用seq2seq十分之一的训练数据就可以达到与之相当的性能;可以并行预测的模型结构也大大加快了推测速度,是seq2seq模型的100倍。
除此之外,LaserTagger也有一些局限需要注意。将文本生成转换为序列标注的思路要求输入和输出文本高度重叠,所以不是所有的文本生成任务都适用。
总的来说,这篇论文的思路很有启发性,实验设计的比较严谨,文章可读性也很好,推荐大家一读。
参考资料
Encode, Tag, Realize: High-Precision Text Editing: https://arxiv.org/pdf/1909.01187.pdf
[2]论文开源代码: https://github.com/google-research/lasertagger
[3]BERT论文: https://arxiv.org/pdf/1810.04805
推荐阅读
抛开模型,探究文本自动摘要的本质——ACL2019 论文佳作研读系列
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。





