Transformers中的Beam Search高效实现
来自:纸鱼AI
目前Github上的大部分实现均针对于单个样本的beam search,而本文主要介绍了针对单个样本和批量样本的beam search实现。
本文代码可以点击“查看原文”找到
Beam Search的原理
设输入序列为 ,输出序列为 ,我们需要建模如下概率分布:(公式向右滑动)
在执行解码时,我们有几种选词方案,第一种则是穷举所有可能序列,这种成本过大无法承受。如果每一步都选择概率最大的词,这种解码方式叫做贪心搜索。然而,这种解码算法不一定能找到全局最优的序列,因为如果第一次解码时选择的 并不是最大概率的,有可能第二次解码的条件概率 却是特别大的。
相比于穷举和贪心搜索,这里有一种折中的方案,即beam search,即每一步解码时,仅保留前 个可能的结果。例如在第一步解码时,我们选择前 个可能的 ,分别代入第二步解码中,各取前 个候选词,即得到 个候选组合,最后保留概率乘积最大的前 个候选结果。

source: http://www.wuyuanhao.com/2020/03/20/解读beam-search-1-2/
当beam size为2时,以上图为例,词表为[A,B,C,D,E]。第一步解码,我们选择概率最大的两个单词[A, C],然后分别带入第二步解码,分别得到[AA, AB, AC, AD, AE, CA, CB, CC, CD, CE] 10种情况,这里仅保留最优的两种情况[AB, CE],然后再继续带入第三步解码。
Beam Search的实现
一种暴力实现方式如下:
-
将beam search过程组织成一棵k叉树,树的结点维护当前的log_prob之和,hidden state,length等。利用层序遍历的方式进行搜索,以每个结点的topk个结点为候选结点,然后取前topk个候选结点作为下一层结点加入队列。
假设需要生成的句子的最大长度为 ,beam size为 ,则最坏情况下,我们需要执行 次前向解码。如何利用CUDA的并行计算能力更加高效地实现该过程呢?
单个样本的Beam Search
这里先讨论一种常见的实现方式,即仅针对单个样本的实现
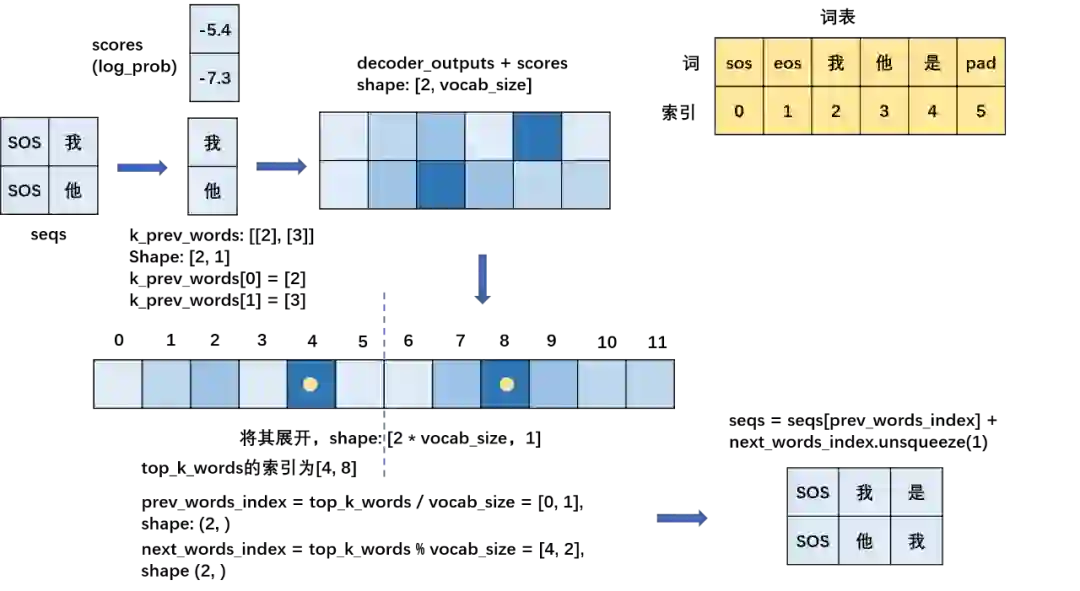
如下图所示,beam size = 2, vocab_size = 6。这里我们设置batch size为k,即在每个时间步,我们可以将k次前向计算合成一次前向计算,提高效率。
具体来说,我们先将sos token复制k次,组织成(k, 1)的形状,送入decoder,得到形如(k, vocab_size)的logit值(经过log_softmax后),与之前保存的log_prob向量相加后,将其展开为(k*vocab_size, 1)的形状(方便直接找到topk大的值的索引)。执行topk后得到的索引可以同时求出前一个时刻的单词索引向量prev_words_index (形状为(k))和当前需要输出的单词索引向量next_words_index (形状为(k)),满足下列关系:
然后将新的单词索引加入到输出序列中,同时更新log_prob向量。循环往复,直到某一个序列遇到eos token时,停止该位置的解码,同时k减一(因为已经找到一条较优序列了),再继续执行。直到k为0。
def beam_search():
k_prev_words = torch.full((k, 1), SOS_TOKEN, dtype=torch.long) # (k, 1)
# 此时输出序列中只有sos token
seqs = k_prev_words #(k, 1)
# 初始化scores向量为0
top_k_scores = torch.zeros(k, 1)
complete_seqs = list()
complete_seqs_scores = list()
step = 1
hidden = torch.zeros(1, k, hidden_size) # h_0: (1, k, hidden_size)
while True:
outputs, hidden = decoder(k_prev_words, hidden) # outputs: (k, seq_len, vocab_size)
next_token_logits = outputs[:,-1,:] # (k, vocab_size)
if step == 1:
# 因为最开始解码的时候只有一个结点<sos>,所以只需要取其中一个结点计算topk
top_k_scores, top_k_words = next_token_logits[0].topk(k, dim=0, largest=True, sorted=True)
else:
# 此时要先展开再计算topk,如上图所示。
# top_k_scores: (k) top_k_words: (k)
top_k_scores, top_k_words = next_token_logits.view(-1).topk(k, 0, True, True)
prev_word_inds = top_k_words / vocab_size # (k) 实际是beam_id
next_word_inds = top_k_words % vocab_size # (k) 实际是token_id
# seqs: (k, step) ==> (k, step+1)
seqs = torch.cat([seqs[prev_word_inds], next_word_inds.unsqueeze(1)], dim=1)
# 当前输出的单词不是eos的有哪些(输出其在next_wod_inds中的位置, 实际是beam_id)
incomplete_inds = [ind for ind, next_word in enumerate(next_word_inds) if
next_word != vocab['<eos>']]
# 输出已经遇到eos的句子的beam id(即seqs中的句子索引)
complete_inds = list(set(range(len(next_word_inds))) - set(incomplete_inds))
if len(complete_inds) > 0:
complete_seqs.extend(seqs[complete_inds].tolist()) # 加入句子
complete_seqs_scores.extend(top_k_scores[complete_inds]) # 加入句子对应的累加log_prob
# 减掉已经完成的句子的数量,更新k, 下次就不用执行那么多topk了,因为若干句子已经被解码出来了
k -= len(complete_inds)
if k == 0: # 完成
break
# 更新下一次迭代数据, 仅专注于那些还没完成的句子
seqs = seqs[incomplete_inds]
hidden = hidden[prev_word_inds[incomplete_inds]]
top_k_scores = top_k_scores[incomplete_inds].unsqueeze(1) #(s, 1) s < k
k_prev_words = next_word_inds[incomplete_inds].unsqueeze(1) #(s, 1) s < k
if step > max_length: # decode太长后,直接break掉
break
step += 1
i = complete_seqs_scores.index(max(complete_seqs_scores)) # 寻找score最大的序列
# 有些许问题,在训练初期一直碰不到eos时,此时complete_seqs为空
seq = complete_seqs[i]
return seq
多个样本同时进行beam search
这才是真正意义上的batch beam search,相比上述版本更加高效,可以同时对多个句子执行beam search
source: http://www.wuyuanhao.com/2020/03/20/解读beam-search-1-2/
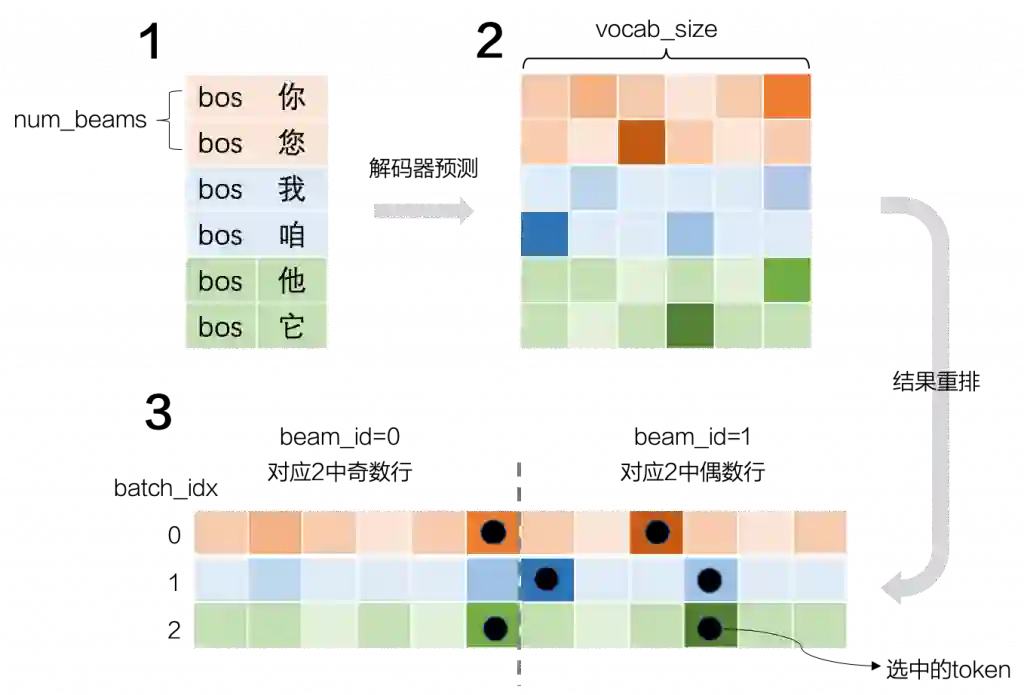
当一个batch中有m个句子需要同时执行beam search时,beam size = k, 此时每个时间步可以将 次的前向计算合成为一次并行的前向计算,更加高效地利用GPU进行beam search。
相比于单个句子执行beam search。我们只需要按照上图所示进行扩展。
设batch_size = 3, vocab_size = 6, beam_size(即num_beams) = 2,则我们需要首先复制bos(即sos) token为(batch_size * num_beams, 1),这里我们将行索引命名为beam id。解码器预测后并与之前保存的log_prob求和得到(batch_size * num_beams, vocab_size), 将其展开为(batch_size, num_beams * vocab_size)。如上图所示,我们可以通过token在当前矩阵的id(记为beam_token_id)和如下计算得到beam_id以及token_id(在未展开的矩阵中的token_id)。
从而将新的单词索引加入到输出序列中,同时更新log_prob向量。
参考Transformers我们可以得到多个句子的beam search实现方式。
在http://www.wuyuanhao.com/2020/03/20/解读beam-search-1-2/的基础上做了其他代码注解。
和之前的单个句子执行beam search不同的是,当找到一个可行序列后,并不会马上减少k的值,而是利用一个类去维护每个输入句子的当前k个最优的序列。对于一个新加入的序列,如果类中最优序列数量小于k,则直接加入,否则如果其log_prob值大于这k个中的最低值,则将其更新到这个类中,并去掉最低的那个序列。
另外,相比于之前的对step=1进行特判的实现方式,这里有另一种实现方式。在这里,我们初始化log_prob向量并不是全0,而是需要把beam_scores[:,1:]=-inf。如此一来,在最开始输入sos进行解码时,输出的k个vocab_size向量展开后,取topk时,永远只会取到第一个vocab_size向量中的值(因为后面都是无穷小了)。如果不这样做且不特判的话,那么对k个vocab_size向量展开的结果取topk的话,只会取到每个vocab_size向量中最大的那个值,共k个,造成重复。
下面是用于维护当前k个最优的序列的类的实现代码。
class BeamHypotheses(object):
def __init__(self, num_beams, max_length, length_penalty):
self.max_length = max_length - 1 # ignoring bos_token
self.length_penalty = length_penalty # 长度惩罚的指数系数
self.num_beams = num_beams # beam size
self.beams = [] # 存储最优序列及其累加的log_prob score
self.worst_score = 1e9 # 将worst_score初始为无穷大。
def __len__(self):
return len(self.beams)
def add(self, hyp, sum_logprobs):
score = sum_logprobs / len(hyp) ** self.length_penalty # 计算惩罚后的score
if len(self) < self.num_beams or score > self.worst_score:
# 如果类没装满num_beams个序列
# 或者装满以后,但是待加入序列的score值大于类中的最小值
# 则将该序列更新进类中,并淘汰之前类中最差的序列
self.beams.append((score, hyp))
if len(self) > self.num_beams:
sorted_scores = sorted([(s, idx) for idx, (s, _) in enumerate(self.beams)])
del self.beams[sorted_scores[0][1]]
self.worst_score = sorted_scores[1][0]
else:
# 如果没满的话,仅更新worst_score
self.worst_score = min(score, self.worst_score)
def is_done(self, best_sum_logprobs, cur_len):
# 当解码到某一层后, 该层每个结点的分数表示从根节点到这里的log_prob之和
# 此时取最高的log_prob, 如果此时候选序列的最高分都比类中最低分还要低的话
# 那就没必要继续解码下去了。此时完成对该句子的解码,类中有num_beams个最优序列。
if len(self) < self.num_beams:
return False
else:
cur_score = best_sum_logprobs / cur_len ** self.length_penalty
ret = self.worst_score >= cur_score
return ret
接下来给出beam search的主代码
batch_size = 3
num_beams = 2
vocab_size = 8
cur_len = 1
embedding_size = 300
hidden_size = 100
max_length = 10
sos_token_id = 0
eos_token_id = 1
pad_token_id = 2
decoder = DecoderRNN(embedding_size, hidden_size, vocab_size)
def beam_search():
beam_scores = torch.zeros((batch_size, num_beams)) # 定义scores向量,保存累加的log_probs
beam_scores[:, 1:] = -1e9 # 需要初始化为-inf
beam_scores = beam_scores.view(-1) # 展开为(batch_size * num_beams)
done = [False for _ in range(batch_size)] # 标记每个输入句子的beam search是否完成
generated_hyps = [
BeamHypotheses(num_beams, max_length, length_penalty=0.7)
for _ in range(batch_size)
] # 为每个输入句子定义维护其beam search序列的类实例
# 初始输入: (batch_size * num_beams, 1)个sos token
input_ids = torch.full((batch_size * num_beams, 1), sos_token_id, dtype=torch.long)
# h0: (1, batch_size * num_beams, hidden_size)
hidden = torch.zeros((1, batch_size * num_beams, hidden_size))
while cur_len < max_length:
# outputs: (batch_size*num_beams, cur_len, vocab_size)
outputs, hidden = decoder(input_ids, hidden)
# 取最后一个timestep的输出 (batch_size*num_beams, vocab_size)
next_token_logits = outputs[:, -1, :]
scores = F.log_softmax(next_token_logits, dim=-1) # log_softmax
next_scores = scores + beam_scores[:, None].expand_as(scores) # 累加上以前的scores
next_scores = next_scores.view(
batch_size, num_beams * vocab_size
) # 转成(batch_size, num_beams * vocab_size), 如上图所示
# 取topk
# next_scores: (batch_size, num_beams) next_tokens: (batch_size, num_beams)
next_scores, next_tokens = torch.topk(next_scores, num_beams, dim=1, largest=True, sorted=True)
next_batch_beam = []
for batch_idx in range(batch_size):
if done[batch_idx]:
# 当前batch的句子都解码完了,那么对应的num_beams个句子都继续pad
next_batch_beam.extend([(0, PAD_TOKEN, 0)] * num_beams) # pad the batch
continue
next_sent_beam = [] # 保存三元组(beam_token_score, token_id, effective_beam_id)
for beam_token_rank, (beam_token_id, beam_token_score) in enumerate(
zip(next_tokens[batch_idx], next_scores[batch_idx])
):
beam_id = beam_token_id // vocab_size # 1
token_id = beam_token_id % vocab_size # 1
# 上面的公式计算beam_id只能输出0和num_beams-1, 无法输出在(batch_size, num_beams)中的真实id
# 如上图, batch_idx=0时,真实beam_id = 0或1; batch_idx=1时,真实beam_id如下式计算为2或3
# batch_idx=1时,真实beam_id如下式计算为4或5
effective_beam_id = batch_idx * num_beams + beam_id
# 如果遇到了eos, 则讲当前beam的句子(不含当前的eos)存入generated_hyp
if (eos_token_id is not None) and (token_id.item() == eos_token_id):
is_beam_token_worse_than_top_num_beams = beam_token_rank >= num_beams
if is_beam_token_worse_than_top_num_beams:
continue
generated_hyps[batch_idx].add(
input_ids[effective_beam_id].clone(), beam_token_score.item(),
)
else:
# 保存第beam_id个句子累加到当前的log_prob以及当前的token_id
next_sent_beam.append((beam_token_score, token_id, effective_beam_id))
if len(next_sent_beam) == num_beams:
break
# 当前batch是否解码完所有句子
done[batch_idx] = done[batch_idx] or generated_hyps[batch_idx].is_done(
next_scores[batch_idx].max().item(), cur_len
) # 注意这里取当前batch的所有log_prob的最大值
# 每个batch_idx, next_sent_beam中有num_beams个三元组(假设都不遇到eos)
# batch_idx循环后,extend后的结果为num_beams * batch_size个三元组
next_batch_beam.extend(next_sent_beam)
# 如果batch中每个句子的beam search都完成了,则停止
if all(done):
break
# 准备下一次循环(下一层的解码)
# beam_scores: (num_beams * batch_size)
# beam_tokens: (num_beams * batch_size)
# beam_idx: (num_beams * batch_size)
# 这里beam idx shape不一定为num_beams * batch_size,一般是小于等于
# 因为有些beam id对应的句子已经解码完了 (下面假设都没解码完)
beam_scores = beam_scores.new([x[0] for x in next_batch_beam])
beam_tokens = input_ids.new([x[1] for x in next_batch_beam])
beam_idx = input_ids.new([x[2] for x in next_batch_beam])
# 取出有效的input_ids, 因为有些beam_id不在beam_idx里面,
# 因为有些beam id对应的句子已经解码完了
input_ids = input_ids[beam_idx, :] # (num_beams * batch_size, seq_len)
# (num_beams * batch_size, seq_len) ==> (num_beams * batch_size, seq_len + 1)
input_ids = torch.cat([input_ids, beam_tokens.unsqueeze(1)], dim=-1)
cur_len = cur_len + 1
# 注意有可能到达最大长度后,仍然有些句子没有遇到eos token,这时done[batch_idx]是false
for batch_idx in range(batch_size):
if done[batch_idx]:
continue
for beam_id in range(num_beams):
# 对于每个batch_idx的每句beam,都执行加入add
# 注意这里已经解码到max_length长度了,但是并没有遇到eos,故这里全部要尝试加入
effective_beam_id = batch_idx * num_beams + beam_id
final_score = beam_scores[effective_beam_id].item()
final_tokens = input_ids[effective_beam_id]
generated_hyps[batch_idx].add(final_tokens, final_score)
# 经过上述步骤后,每个输入句子的类中保存着num_beams个最优序列
# 下面选择若干最好的序列输出
# 每个样本返回几个句子
output_num_return_sequences_per_batch = 1
output_batch_size = output_num_return_sequences_per_batch * batch_size
# 记录每个返回句子的长度,用于后面pad
sent_lengths = input_ids.new(output_batch_size)
best = []
# retrieve best hypotheses
for i, hypotheses in enumerate(generated_hyps):
# x: (score, hyp), x[0]: score
sorted_hyps = sorted(hypotheses.beams, key=lambda x: x[0])
for j in range(output_num_return_sequences_per_batch):
effective_batch_idx = output_num_return_sequences_per_batch * i + j
best_hyp = sorted_hyps.pop()[1]
sent_lengths[effective_batch_idx] = len(best_hyp)
best.append(best_hyp)
if sent_lengths.min().item() != sent_lengths.max().item():
sent_max_len = min(sent_lengths.max().item() + 1, max_length)
# fill pad
decoded = input_ids.new(output_batch_size, sent_max_len).fill_(pad_token_id)
# 填充内容
for i, hypo in enumerate(best):
decoded[i, : sent_lengths[i]] = hypo
if sent_lengths[i] < max_length:
decoded[i, sent_lengths[i]] = eos_token_id
else:
# 否则直接堆叠起来
decoded = torch.stack(best).type(torch.long)
# (output_batch_size, sent_max_len) ==> (batch_size, sent_max_len)
return decoded
参考链接
-
http://www.wuyuanhao.com/2020/03/20/解读beam-search-1-2/ -
https://github.com/huggingface/transformers -
https://medium.com/the-artificial-impostor/implementing-beam-search-part-1-4f53482daabe
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记

整理不易,还望给个在看!


