MySQL NDB Cluster实战
本文来自睿哲科技的张树杰同学分享MySQL NDB集群的基础知识和搭建,非常赞!
希望越来越多的同学一起来分享,帮助他人,也收获成长,每季度分享排名第一的同学有惊喜哦。
MySQL Cluster是MySQL官方的解决方案,其实对于MySQL集群,有很多对应的解决方案,MySQL Cluster是其中的一种。
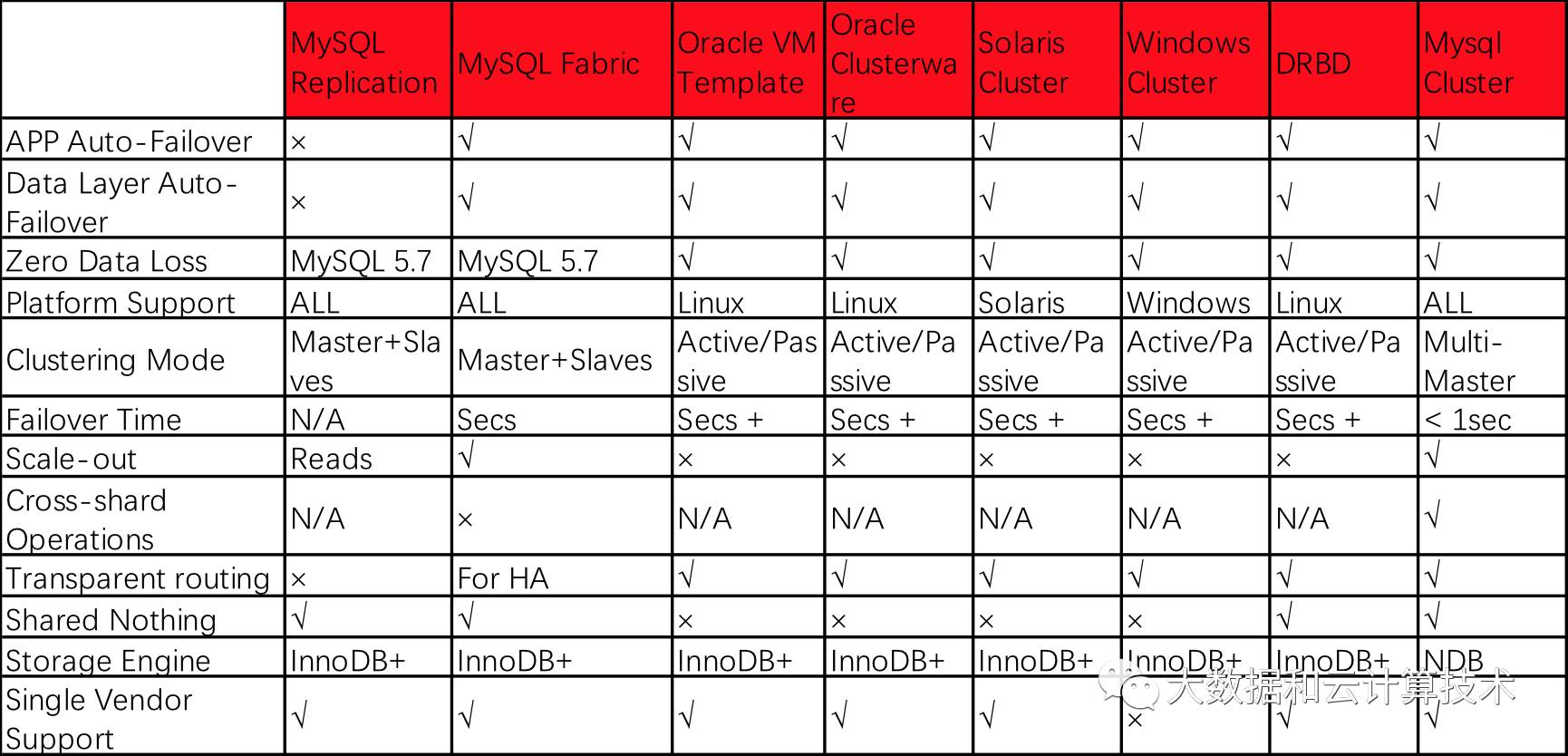
MySQL Cluster是MySQL 适合于分布式计算环境的高实用、可拓展、高性能、高冗余版本,其研发设计的初衷就是要满足许多行业里的最严酷应用要求,这些应用中经常要求数据库运行的可靠性要达到99.999%。MySQL Cluster允许在无共享的系统中部署“内存中”数据库集群,通过无共享体系结构,系统能够使用廉价的硬件,而且对软硬件无特殊要求。此外,由于每个组件有自己的内存和磁盘,不存在单点故障。
实际上,MySQL集群是把一个叫做NDB的内存集群存储引擎集成与标准的MySQL服务器集成。它包含一组计算机,每个都跑一个或者多个进程,这可能包括一个MySQL服务器,一个数据节点,一个管理服务器和一个专有的一个数据访问程序。
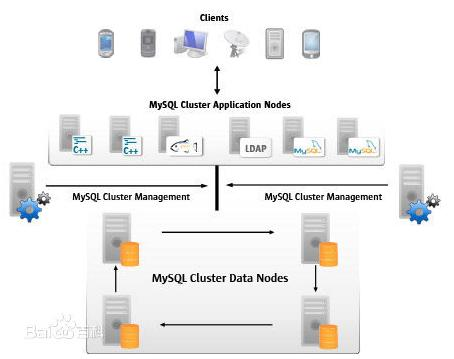
MySQL Cluster能够使用多种故障切换和负载平衡选项配置NDB存储引擎,但在Cluster 级别上的存储引擎上做这个最简单。以下为MySQL集群结构关系图,
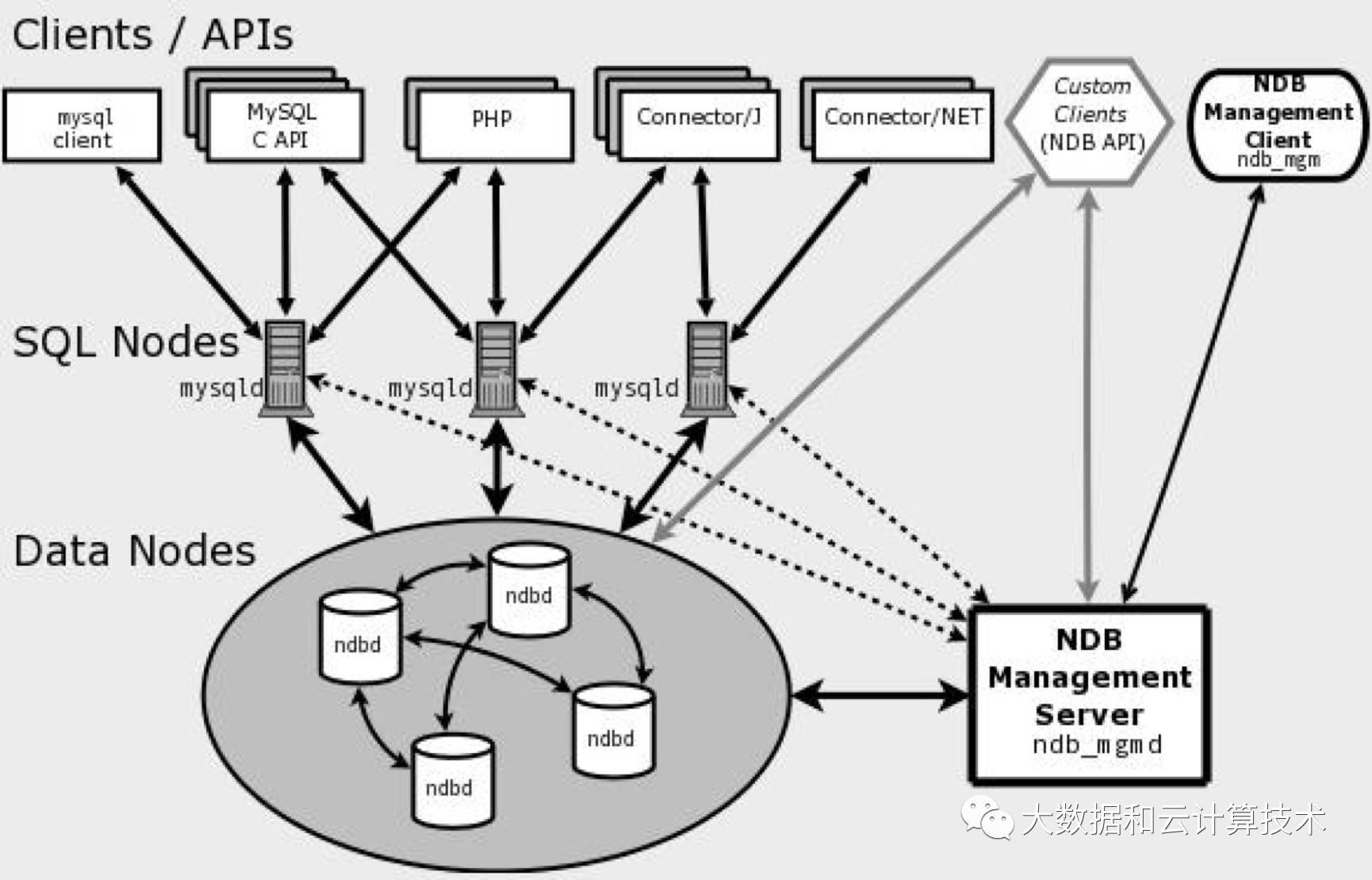
MySQL从结构看,由3类节点(计算机或进程)组成,分别是:
1. 管理节点:用于给整个集群其他节点提供配置、管理、仲裁等功能。理论上通过一台服务器提供服务就可以了。
2. 数据节点:MySQL Cluster的核心,存储数据、日志,提供数据的各种管理服务。2个以上 时就能实现集群的高可用保证,DB节点增加时,集群的处理速度会变慢。
3. SQL节点(API):用于访问MySQL Cluster数据,提供对外应用服务。增加 API 节点会提高整个集群的并发访问速度和整体的吞吐量,该节点 可以部署在Web应用服务器上,也可以部署在专用的服务器上,也开以和DB部署在同一台服务器上。
MySQL Cluster 使用了一个专用的基于内存的存储引擎——NDB引擎,这样做的好处是速度快, 没有磁盘I/O的瓶颈,但是由于是基于内存的,所以数据库的规模受系统总内存的限制, 如果运行NDB的MySQL服务器一定要内存够大,比如4G, 8G, 甚至16G。NDB引擎是分布式的,它可以配置在多台服务器上来实现数据的可靠性和扩展性,理论上 通过配置2台NDB的存储节点就能实现整个数据库集群的冗余性和解决单点故障问题。
1. 缺陷
基于内存,数据库的规模受集群总内存的大小限制
基于内存,断电后数据可能会有数据丢失,这点还需要通过测试验证。
多个节点通过网络实现通讯和数据同步、查询等操作,因此整体性受网络速度影响,因此速度也比较慢
2. 优点
多个节点之间可以分布在不同的地理位置,因此也是一个实现分布式数据库的方案。
扩展性很好,增加节点即可实现数据库集群的扩展。
冗余性很好,多个节点上都有完整的数据库数据,因此任何一个节点宕机都不会造成服务中断。
实现高可用性的成本比较低,不象传统的高可用方案一样需要共享的存储设备和专用的软件才能实现,NDB 只要有足够的内存就能实现。
1. IP地址规划
管理节点 |
Mgm |
10.2.1.140 |
管理节点 |
Mgm |
10.2.1.145 |
数据节点 |
Ndb |
10.2.1.145 |
数据节点 |
Ndb |
10.2.1.150 |
SQL节点 |
SQL |
10.2.1.140 |
SQL节点 |
SQL |
10.2.1.150 |
2. 公共配置
系统:Centos7,内存16G,内核版本3.10.0-693.5.2.el7.x86_64。
MySQL版本:mysql-cluster-gpl-7.4.17-linux-glibc2.12-x86_64.tar.gz。路径:/opt/
解压:
tar zxvf mysql-cluster-gpl-7.4.17-linux-glibc2.12-x86_64.tar.gz
mv mysql-cluster-gpl-7.4.17-linux-glibc2.12-x86_64 /usr/local/mysql
3. 关闭安全策略
关闭防火墙:systemctl stop firewalld.service
关闭SELinux:vim /etc/selinux/config , 将config文件中的SELINUX项改为disabled.
最后重启系统
4.1配置config.ini文件
mkdir /var/lib/mysql-cluster
cd /var/lib/mysql-cluster
vim config.ini
配置文件config.ini内容如下:
[ndbd default]
NoOfReplicas=2
DataMemory=80M
IndexMemory=18M
[ndb_mgmd]
NodeId=1
hostname=10.2.1.140
datadir=/var/lib/mysql-cluster
[ndb_mgmd]
NodeId=2
hostname=10.2.1.145
datadir=/var/lib/mysql-cluster
[ndbd]
NodeId=3
hostname=10.2.1.145
datadir=/usr/local/mysql/data/ndbd
[ndbd]
NodeId=4
hostname=10.2.1.150
datadir=/usr/local/mysql/data/ndbd
[mysqld]
NodeId=5
hostname=10.2.1.140
[mysqld]
NodeId=6
hostname=10.2.1.150
4.2配置管理服务
安装管理节点,不需要mysqld二进制文件,只需要MySQL Cluster服务端程序(ndb_mgmd)和监听客户端程序(ndb_mgm)。
cp /usr/local/mysql/bin/ndb_mgm* /usr/local/bin
cd /usr/local/bin
chmod +x ndb_mgm*
5.1添加mysql组和用户
groupadd mysql
useradd -g mysql mysql
5.2配置my.cnf配置文件
vim /usr/local/mysql/ndb/my.cnf
my.cnf的内容如下:
[mysqld]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data/ndbd
socket=/usr/local/mysql/sock/mysql.sock
user=mysql
character-set-server=utf8
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
[mysql_cluster]
ndb-connectstring=10.2.1.140,10.2.1.145
5.3创建系统数据库
cd /usr/local/mysql
mkdir sock
scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data/ndbd
5.4设置数据目录
chown -R root .
chown -R mysql.mysql /usr/local/mysql/data/ndbd
chown -R mysql.mysql /usr/local/mysql/sock
chgrp -R mysql .
5.5配置MySQL服务
cp support-files/mysql.server /etc/rc.d/init.d/
chmod +x /etc/rc.d/init.d/mysql.server
chkconfig --add mysql.server
6.1添加mysql组和用户
groupadd mysql
useradd -g mysql mysql
6.2配置my.cnf配置文件
vim /usr/local/mysql/sql/my.cnf
my.cnf的内容如下:
[client]
socket=/usr/local/mysql/sock/mysql.sock
[mysqld]
ndbcluster
datadir=/usr/local/mysql/data
socket=/usr/local/mysql/sock/mysql.sock
ndb-connectstring=10.2.1.140,10.2.1.145
character-set-server=utf8
[mysql_cluster]
ndb-connectstring=10.2.1.140,10.2.1.145
6.3创建系统数据库
cd /usr/local/mysql
mkdir sock
scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
6.4设置数据目录
chown -R root .
chown -R mysql.mysql /usr/local/mysql/data
chown -R mysql.mysql /usr/local/mysql/sock
chgrp -R mysql .
6.5配置MySQL服务
cp support-files/mysql.server /etc/rc.d/init.d/
chmod +x /etc/rc.d/init.d/mysql.server
chkconfig --add mysql.server
注意启动顺序:首先是管理节点,然后是数据节点,最后是SQL节点。
1. 启动管理结点
在shell中运行以下命令:
ndb_mgmd -f /var/lib/mysql-cluster/config.ini --ndb-nodeid=1
在第二台管理节点上使用
ndb_mgmd -f /var/lib/mysql-cluster/config.ini --ndb-nodeid=2
还可以使用ndb_mgm来监听客户端,如下:
ndb_mgm
ndb_mgm>show
2. 启动数据结点
首次启动,则需要添加--initial参数进行初始化,以便进行NDB节点的初始化工作。在以后的启动过程中,则是不能添加该参数的,否则ndbd程序会清除在之前建立的所有用于恢复的数据文件和日志文件。
/usr/local/mysql/bin/ndbd --initial
如果不是首次启动,则执行下面的命令。
/usr/local/mysql/bin/ndbd
3. 启动SQL结点
若MySQL服务没有运行,则在shell中运行以下命令:
/usr/local/mysql/bin/mysqld_safe --user=mysql &
4.启动测试
查看管理节点,启动成功。
为激励大家主动分享,经过群内同学讨论,暂定简单激励规则:
1,鼓励大家积极将自己的工作经验,技术感悟,学习总结来分享到微信公众号(方法很简单,大家写好,发给我,我会负责编辑发出来)。
2,每季度排名排名第一的同学,群主送本书,优先群主写的书。如果你已经有了,可以换本其他的。
3,前面谢总贡献最多,一共写了8篇超融合,业界影响力巨大,先送1本,算第1次。
4,年底不到两个月了,第2次送出就截止今年12.31号,统计分享排名第一的,送一本。
5,后面每季度统计一次。
6,版权归作者,授权同意我发表在公众号上。
7,不用担心文笔和水平不好,重在参与。
8,群主书比较火,每次重印编辑会寄2本给我,当前其实都已经送出去了,当前我手上实际是没有书。送出去的都是需要我自己掏钱买了再送,所以需要1~2周时间。
9,很多细节可能没有考虑到,解释权归群主。
猜你喜欢
加入技术讨论群
为了方便大家相互交流学习,创建了一个公众号同名微信群:《大数据和云计算技术交流群》,人数已经1500+,欢迎大家加下面我的微信,我拉大家进群,自由交流。