【重磅】机器阅读理解终于超越人类水平!权威竞赛排名中国霸榜,MSRA、阿里、腾讯前二
新智元报道
编辑:刘小芹 弗朗西斯
【新智元导读】2018年1月3日,微软亚洲研究院的r-net率先第一个在SQuAD machine reading comprehension challenge 上达到82.650,这意味着在ExactMatch (精准匹配)指标上首次超越人类在2016年创下的82.304。之后两天,阿里巴巴iDST也取得佳绩,刷新F1分数至88.607, 中国AI崛起,中国的自然语言理解研究已经走在世界前列。

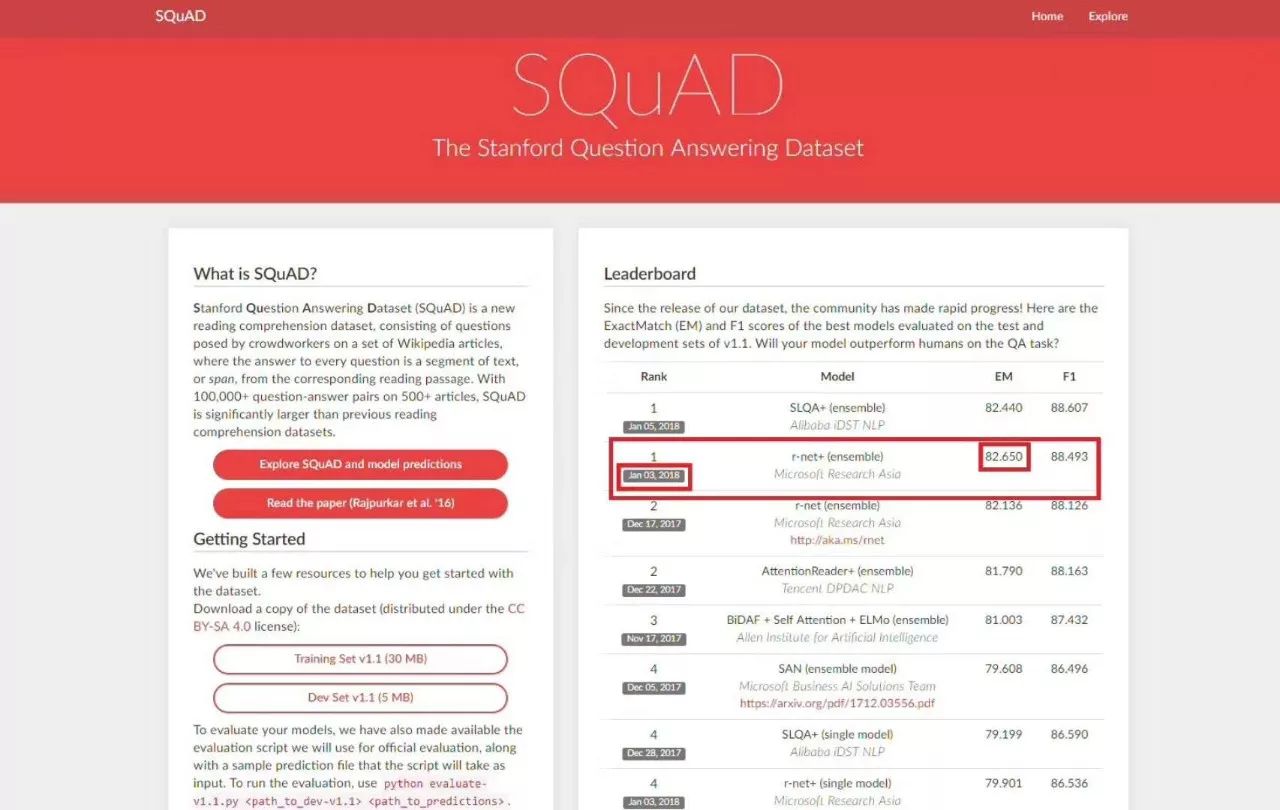
2018年1月3日,微软亚洲研究院的r-net率先在SQuAD machine reading comprehension challenge 上达到82.650,这意味着在ExactMatch (精准匹配)指标上首次超越人类在2016年创下的82.304。

值得注意的是,其中阿里巴巴数据科学与技术研究院IDST在1月5日刷新了F1分数至88.607。腾讯NLP团队在一个月前的数据也紧随其后,可喜可贺。

在前10名单中,我们看到了中国团队的“霸榜”:
并列第1:阿里巴巴 iDST NLP、微软亚洲研究院
并列第2:微软亚洲研究院、腾讯DPDAC NLP
并列第4:阿里巴巴 iDST NLP、微软亚洲研究院
第5:科大讯飞与哈工大联合实验室
第9:阿里巴巴 iDST NLP
第10:浙江大学
包括阿里巴巴、艾伦研究院、IBM、Salesforce、Facebook、谷歌以及CMU(卡内基·梅隆大学)、斯坦福大学等在内的全球自然语言处理领域的研究人员,共同推动着自然语言理解的进步。
微软亚洲研究院副院长周明在朋友圈评论:祝贺中国的自然语言理解研究已经走在世界前列!高兴的同时也更加意识到自然语言理解长路漫漫,更需继续努力。
做机器阅读理解研究的学者,想必对由斯坦福大学自然语言计算组发起的SQuAD(Stanford Question Answering Dataset)文本理解挑战赛并不陌生。
它也被誉为“机器阅读理解界的ImageNet”。诸多来自全球学术界和产业界的研究团队都积极地参与其中。
SQUAD是斯坦福大学2016年推出的一个阅读理解数据集,由众多维基百科文章众包工作者提出的问题组成,其中每个问题的答案都是相应阅读段落的一段文字,需要算法找到答案。
在配套的500多篇文章中,有超过10万个问题,SQuAD显着大于以前的阅读理解数据集。
那么,SQuAD机器阅读理解挑战赛是怎样进行的呢?SQuAD通过众包的方式构建了一个大规模的机器阅读理解数据集(包含10万个问题)。
即将一篇几百(平均100,最多800)词左右的短文给标注者阅读,随后让标注人员提出最多5个基于文章内容的问题并提供正确答案。
SQuAD向参赛者提供训练集用于模型训练,以及一个规模较小的数据集作为开发集,用于模型的测试和调优。
与此同时,他们提供了一个开放平台供参赛者提交自己的算法,并利用测试集对其进行评分,评分结果将实时地在SQuAD官网上进行更新。
为了研究机器阅读理解问题,微软亚洲研究院NLP团队试图去建模人做阅读理解的过程。
他们提出一个名为R-NET的端到端神经网络模型,该模型的目的是回答针对给定文本段落的问题。
在R-NET的技术报告中,他们首先将问题和文本与门控注意力循环网络(gated attention-based recurrent networks)相匹配,以获得question-aware的文本表示。
然后,他们提出一个self-matching的注意力机制,通过将文本自身进行匹配来优化表示,从而有效地对整个段落中的信息进行编码。
最后,研究人员使用提示网络( pointer network)来定位文本中答案的位置。这个模型在SQuAD和MS-MARCO数据集上进行了广泛的实验,在两个数据集上都取得了很好的结果。
人在做阅读理解的过程中,一个常见的顺序是这样的:首先阅读整篇文章,对文章有一个初步理解之后再去审题,从而对问题也有了一定认知。
第二步,可能就需要将问题和文中的部分段落和内容做一些关联。例如题干中出现的某些关键已知信息(或证据)的,找出一些候选答案,举例来说:如果问题问的信息是时间,那么文中出现的与时间相关的信息就可能是候选答案。
第三步,当我们将候选答案与问题进行对应之后,我们还需要综合全文去看待这些问题,进行证据的融合来辅证答案的正确性。
最后一步,就是针对自己挑出的答案候选进行精筛,最终写下最正确的答案。
R-NET 模型也分为类似这样的四层。
最下面的一层做表示学习,就是给问题和文本中的每一个词做一个表示,即深度学习里的向量。这里研究组使用的是多层的双向循环神经网络。
第二步,就是将问题中的向量和文本中的向量做一个比对,这样就能找出那些问题和哪些文字部分比较接近。
接下来,将这些结果放在全局中进行比对。这些都是通过注意力机制达到的。
最后一步,针对挑出的答案候选区中的每一个词汇进行预测,哪一个词是答案的开始,到哪个词是答案的结束。
这样,系统会挑出可能性最高的一段文本,最后将答案输出出来。整个过程就是一个基于以上四个层面的神经网络的端到端系统。
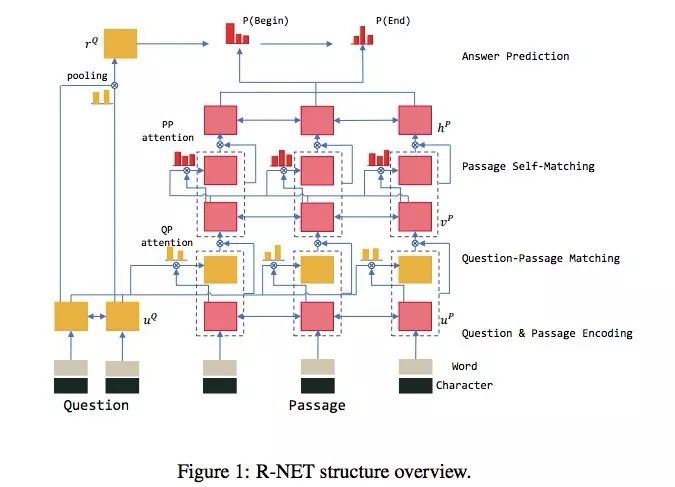
图:微软亚洲研究院提出的 R-NET 算法的网络结构图。
其中最为独特的部分是第三层文章的自匹配网络(Self-Matching Networks),更多细节参考技术报告。
R-NET:一个用于阅读理解和问题回答的端到端神经网络模型,由以下四部分组成:
1)循环神经网络编码器,用于为问题和文本建立表示
2)门控匹配层(gated matching layer),用于匹配问题和文本
3)自匹配层(self-matching layer),用于整合整个段落的信息
4)基于答案边界预测层的提示网络(pointer-network)
这项工作在SQuAD数据集取得了优异的结果。最新的r-net+集成模型(ensemble)取得了EM(完全匹配)82.650分和F1 88.493分,排名第一的成绩,r-net(集成模型)、r-net+(单模型)和r-net(单模型)也分别取得第2、第4和第14名的成绩。
参考文献:
[1]R-NET: Machine Reading Comprehension with Self-matching Networks, Natural Language Computing Group, Microsoft Research Asia
[2] 机器阅读理解界的 ImageNet:他们为什么可以长期稳坐第一名
加入社群
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号: aiera2015_1 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名-公司-职位;专业群审核较严,敬请谅解)。
此外,新智元AI技术+产业领域社群(智能汽车、机器学习、深度学习、神经网络等)正在面向正在从事相关领域的工程师及研究人员进行招募。
加入新智元技术社群,共享AI+开放平台