如何像用MNIST一样来用ImageNet?这里有一份加速TensorFlow分布式训练的梯度压缩指南

作者 | 王佐
今年的 NIPS 出现 "Imagenet is the new MNIST" 口号,宣告使用 MNIST 数据集检验网络模型性能已经成为过去式。算法工程师们早就意识到训练数据集大小的重要性,并且进一步发现,针对特定的模型大小,训练数据集的大小和泛化误差之间存在以下的关系[1]:
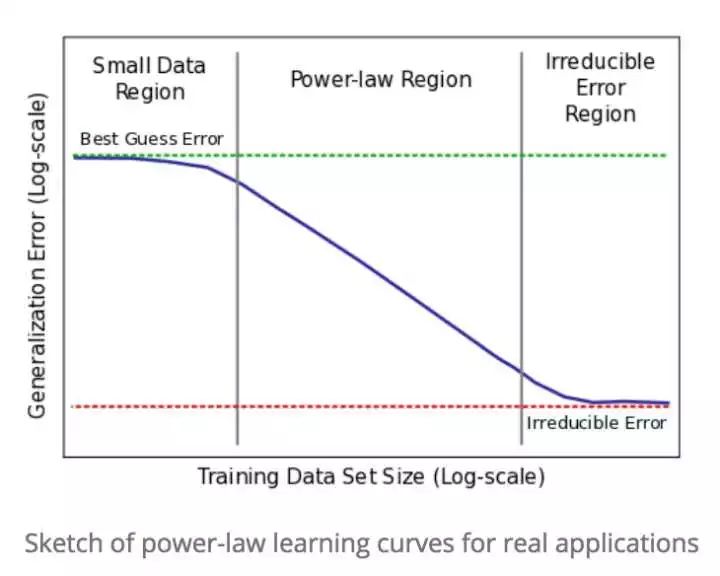
训练数据集大小必须跨越Power-law Region,才能得到网络模型的实际性能。
网络模型的大小(表现为网络模型的参数数量)越来越大,处理单个 sample 需要消耗更多的单精度运算。例如,Resnet-50 处理一张 225 x 225 的图片需要消耗 7.72 x 109次单精度运算,如果在Imagenet上训练90epochs,需要消耗 90 x 1.28 x 106 x 7.72 x 109 ≈ 1018 次单精度运算。以Tesla K80的峰值单精度浮点性能 5.6 Tflops 估计,理想情况下也要训练 50 多个小时。
虽然网络模型参数有很多冗余,可以使用模型压缩算法减少冗余,提高推理速度,但目前还没有算法能减少训练期间的网络模型参数,无法提高训练速度。使用较少模型参数的网络训练,只能得到性能差很多的模型。
目前唯一可以显著提升训练效率的方式是使用Large Batch Size进行大规模分布式训练。
许多实验表明,通讯开销是大规模分布式训练的瓶颈。以Data-Parallize训练Restnet-50为例,Resnet-50参数大小约100MB(25.6million * 4B),在Tesla K80上用TensorFlow训练,每次迭代需要181.404ms[2],这意味着必须要有550MB/s以上的带宽,才能避免带宽饱和。若考虑 VGG-16(138million * 4B),则需要 2965MB/s 以上的带宽,才能避免带宽饱和。
幸运的是,只需要训练3~4epoches,梯度的稀疏度就能达到99.9%,将梯度压缩 270x 到 600x 而不损失精度[3]。例如将 Resnet-50 梯度从 97MB 压缩到 0.35MB,即使在最普通的 1Gbps 以太网上跑大规模分布式训练,也不会出现带宽饱和。
梯度压缩减少通讯开销[3]
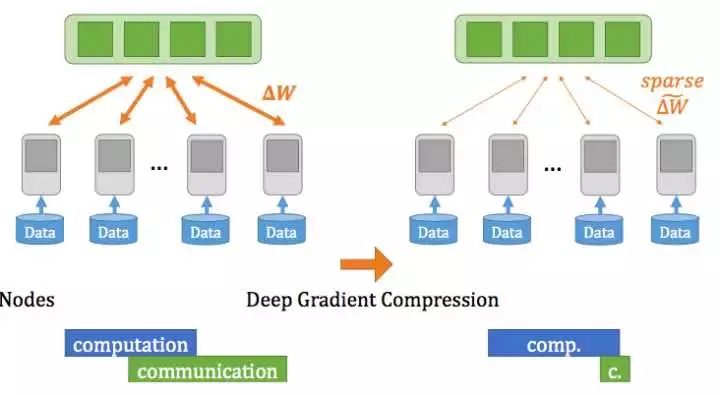
梯度压缩原理
当梯度达到99.9%稀疏度,只有绝对值最大的0.1%梯度发送到参数服务器。如何找出绝对值最大的0.1%梯度呢?可以使用 top-k selection 算法找到threshold。top-k selection 的时间复杂度是 O(N)。为了提高速度,可以先 random sample 少量梯度,再用 top-k selection 算法找一个近似的 threshold。如果大于 threshold 的梯度超过0.1%,则可在结果集中再次使用 top-k selection 算法。未超过 threshold 的梯度会累积到下次迭代的梯度中。
梯度压缩能极大减少网络开销,但会影响收敛,导致模型精度降低。
以下介绍四个可以减少此影响、达到不损失精度的方法:
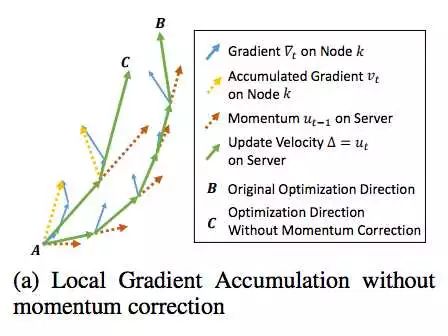
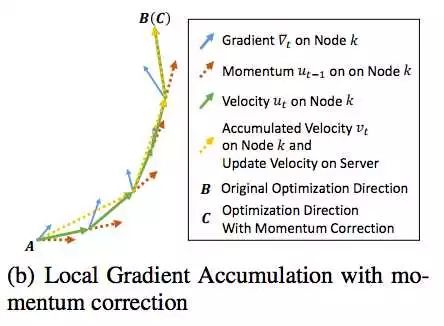
一,如图,在使用 Momentum 优化器训练中,使用梯度压缩(C)导致和原优化算法(B)路径分离。
本地梯度累积导致精度降低[3]
通过如下修改Momentum优化算法:
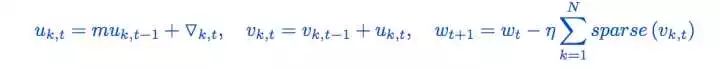
即给本地累积梯度也apply momentum,可以使梯度压缩(C)和原优化算法(B)路径一致。
这里有点难理解,推导如下:
假设第i个梯度从直到t-1次迭代才超过threshold,触发更新,此时
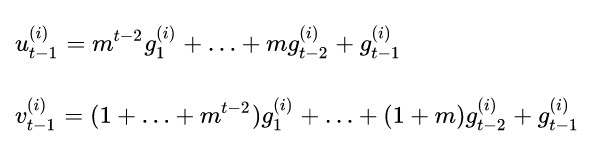
更新权重
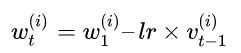
更新后需要执行
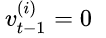
如果第t次迭代,触发更新,此时
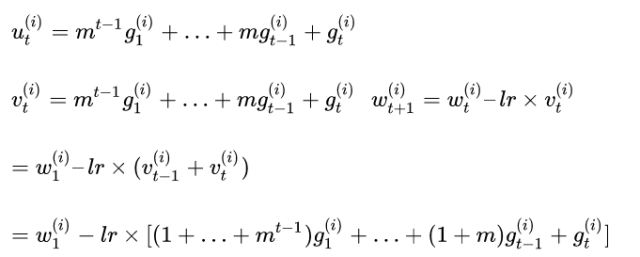
所以本地梯度累积跟原优化算法一致。
二、梯度压缩可能导致梯度爆炸问题,可以在每个节点对本地梯度使用梯度裁剪算法。
三、对大于 threshold 的梯度,将 Momentum 清零。
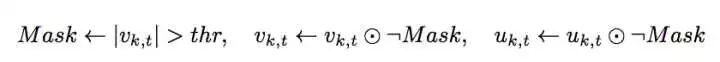
根据[4]中结论,async SGD会产生一个 implicit momentum,导致收敛变慢。本地梯度累计跟 async SGD 存在相似性:未能及时更新梯度产生 staleness。[4]中通过 grid search 的方法发现 negative momentum 能一定程度抵消 implicit momentum 效果,提高收敛速度。
这里 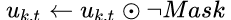
四、在梯度达到 99.9% 稀疏度前,有个 warm-up stage。
算法步骤如下[3]

梯度压缩的TensorFlow实现
在tensorflow/python/training/momentum.py中,为每个variable增加一个residual
def _create_slots(self, var_list):
for v in var_list:
self._zeros_slot(v, "momentum", self._name)
+ for v in var_list:
+ self._zeros_slot(v, "residual", self._name)
在tensorflow/core/kernels/http://training_ops.cc中,获取residual,并apply momentum
+Tensor residual;
+OP_REQUIRES_OK(ctx, GetInputTensor(ctx, 5, use_exclusive_lock_, &residual));
functor::ApplyMomentum<Device, T>()(device, var.flat<T>(), accum.flat<T>(),
lr.scalar<T>(), grad.flat<T>(),
+ momentum.scalar<T>(), residual.flat<T>(),
+ use_nesterov_,
+ ctx, steps);
在tensorflow/core/kernels/http://training_ops_gpu.cu.cc中,实现梯度压缩
if (use_nesterov) {
var.device(d) = grad * lr.reshape(single).broadcast(bcast) +
accum * momentum.reshape(single).broadcast(bcast) *
+ lr.reshape(single).broadcast(bcast) +
+ residual * lr.reshape(single).broadcast(bcast);
} else {
+ var.device(d) = lr.reshape(single).broadcast(bcast) * accum +
+ residual * lr.reshape(single).broadcast(bcast);
}
+ if (steps < WARMUP) {
+ return ctx->ps()->update(var.name(), var.data(), d.stream());
+ }
+ Tensor norm(DataTypeToEnum<T>::value, {});
+ norm.scalar<T>().device(d) = var.square().sum().sqrt();
+ Tensor threshold(DataTypeToEnum<T>::value, {});
+ threshold.scalar<T>()() = 6.0;
+ if (norm.scalar<T>()() > threshold.scalar<T>()()) {
+ var.device(d) = var * threshold.scalar<T>().reshape(single).broadcast(bcast) /
+ norm.scalar<T>().reshape(single).broadcast(bcast);
+ }
+ int size = var.size();
+ int capacity = size * 1.2 * (1.0 - 0.99);
+ Tensor sparse_buf;
+ OP_REQUIRES_OK(ctx, ctx->allocate_temp(
+ DataTypeToEnum<T>::value,
+ TensorShape({static_cast<int64>(capacity * sizeof(T))}), &sparse_buf));
+ T* buf = sparse_buf.template flat<T>().data();
+ Tensor sparse_indice;
+ OP_REQUIRES_OK(ctx, ctx->allocate_temp(
+ DataTypeToEnum<T>::value,
+ TensorShape({static_cast<int64>(capacity * sizeof(T))}), &sparse_indice));
+ T* indices = sparse_indice.template flat<T>().data();
+ T* data = var.data();
+ T* tmp = residual.data();
+ int sortSize = std::min(100000, size);
+ CudaLaunchConfig config2 = GetCudaLaunchConfig(sortSize, d);
+ sampling<T>
+ <<<config2.block_count, config2.thread_per_block, 0, d.stream()>>>
+ (data, tmp, sortSize, size / sortSize, size);
+ thrust::device_ptr<T> dev_data_ptr(tmp);
+ thrust::sort(dev_data_ptr, dev_data_ptr + sortSize);
+ float rate = 0.99;
+ T threshold;
+ int k_index = std::max(0, (int)(sortSize * rate) - 1);
+ cudaMemcpy(&threshold, tmp + k_index, sizeof(T), cudaMemcpyDeviceToHost);
+ CudaLaunchConfig config = GetCudaLaunchConfig(size, d);
+ gen_mask<T>
+ <<<config.block_count, config.thread_per_block, 0, d.stream()>>>
+ (data, tmp, accum.data(), threshold, size);
+ thrust::device_ptr<T> mask_ptr(tmp);
+ thrust::inclusive_scan(mask_ptr, mask_ptr + size, mask_ptr);
+ T sum;
+ cudaMemcpy(&sum, tmp + size - 1, sizeof(T), cudaMemcpyDeviceToHost);
+ unsigned long sparse_size = sum;
+ sparsify<T>
+ <<<config.block_count, config.thread_per_block, 0, d.stream()>>>
+ (data, tmp, buf, indices, size);
+ assign_residual<T>
+ <<<config.block_count, config.thread_per_block, 0, d.stream()>>>
+ (data, tmp, size);
+ cudaMemcpy(&data, buf, sizeof(T) * sparse_size, cudaMemcpyDeviceToDevice);
+ cudaMemcpy(&data, indices, sizeof(T) * sparse_size, cudaMemcpyDeviceToDevice);
+ cudaStreamSynchronize(d.stream());
+ ctx->ps()->update(var.name(), data, sparse_size, d.stream());
这是最初实现代码,仅供参考。
本文作者:王佐
天数润科深度学习平台负责人,曾担任 Intel 亚太研发中心 Team Leader,万达人工智能研究院资深研究员,长期从事分布式计算系统研究,在大规模分布式机器学习系统架构、机器学习算法设计和应用方面有深厚积累。
Reference:
[1] http://research.baidu.com/deep-learning-scaling-predictable-empirically/
[2] Benchmarking State-of-the-Art Deep Learning Software Tools
[3] Deep Gradient Compression:Reducing the Communication Bandwidth for Distributed Training
[4] Asynchrony begets momentum, with an application to deep learning
精选推荐
经验 | Pytorch还是Tensorflow?英伟达工程师帮你总结了
图解TensorFlow架构与设计
视频教程| 使用TensorFlow搭建一个识别手写数字的分类器




