日本研究人员创建“神经搞笑机”,自制表情包文字
编者按:现在网络上经常出现各种让人捧腹的表情包,单看图片觉得没什么,上面的文字才是“点睛之笔”。
比如这样:

这样:

还有这样:

今天,机器学习大牛David Ha在推特上分享了一篇有趣的论文——Neural Joking Machine:Humorous image captioning,作者是来自东京电机大学和日本产业技术综合研究所的研究人员们。他们提出了一个有趣的项目——给图片添加搞笑注释,也可以理解为添加表情包文字。这篇论文就提出了一种名为NJM的框架,能自动生成与图片相关的有趣文字。以下是论智对文章的编译。
笑声是人类特有的表达情绪的方法。在对笑声的分析中,维基百科是这样讲的:“笑声往往由出乎意料的事情或社交联系触发”,当听者接受的信息改变时,笑声就会频繁出现。然而,听者所处的情景不同,对笑声的看法也不同。所以,想要对笑声进行量化非常困难。
最近,日本出现了一个名为“Bokete”的网站(地址:bokete.jp),用户可以自行发挥,在不同主题的图片中发布有趣的注解,然后让其他网友评分。谁得到的星星越多,谁的图片就越受欢迎。这也可以看作量化笑声的一种方法。

为了从学术角度考虑这个问题,研究人员在本篇论文中做出了三点创新:
创建了一种由计算机生成搞笑图片注释的生成框架,该系统基于计算机视觉技术提出的图像注释(Image caption),从而可以生成更有趣的注释。
更重要的是,他们还提出了Funny Score,是一个基于现有搞笑注释数据集的加权系统,它可以根据一个评估数据集灵活分配权重。Funny Score还可以高效地促成搞笑效果,优化模型。
除此之外,研究人员从Bokete网站收集了数据,创建了Bokete数据库,其中包括999571张图片和注释对。在实验中研究人员利用Bokete数据库验证所提出方法的效果,比较所提出的方法生成的结果和利用MS COCO预训练CNN和LSTM方法生成的结果,后者是目前的基准方法。他们将所提出的利用Bokete数据库进行预训练的模型称为神经搞笑机(Neural Joking Machine,NJM)。
模型详解
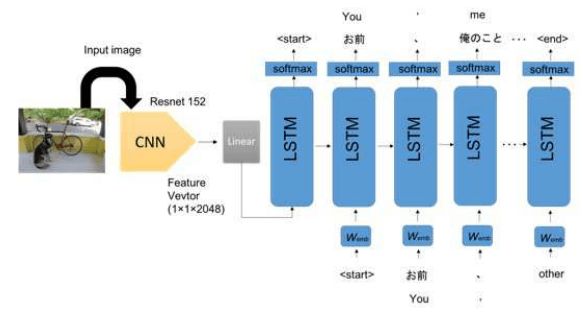
上图是所提出的方法的大致流程,研究人员基本上用的是Show and Tell中的CNN+LSTM模型结构,但是将CNN换成了ResNet-152,作为图像特征提取器。
Bokete网站用星星当做点赞方法,评价一个图片注释的搞笑程度。他们就根据每张图片星星数量,提出一种有效的训练方法,从而让Funny Score得出最搞笑的一张注释。基于之前的实验,研究人员将100分定为一个门槛,也就是说,如果#star小于100,则Funny Score生成一个损失值L,如果大于100,则返回一个L-1.0的值。这里的损失值L使用LSTM计算出的每个mini-batch的平均值。
数据集
研究人员从Bokete网站下载了许多图片和相对应的搞笑注释,在2018年3月,网站上一共有6000万条注释和340万张图片。最终下载了999571条注释和70981张图片组成了Bokete数据集。与MS COCO相比,MS COCO有160000张图片,是Bokete的两倍还多,但是注释却比Bokete少。
实验过程
为了评估所提方法的效果,研究人员进行了对比实验。在这里,试验方法被称为NJM。
将所提出的方法与人类生成的搞笑注释和用CNN+LSTM生成的注释进行对比。其中,人类生成的注释在Bokete网站上非常受欢迎。CNN+LSTM的方法在STAIR上进行预训练(注:由于STAIR是英文的,所以研究人员将英文翻译成了日语)。评估的方法以问卷调查的方式进行。下表显示了调查结果:
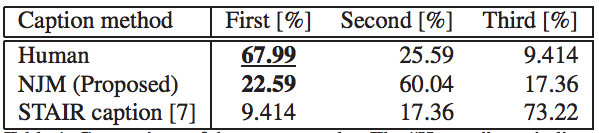
从表中可以看出,依然是人类生成的注释最搞笑,本文提出的NJM排在第二位。
之后他们又将NJM生成的搞笑注释发布在Bokete网站上,评估这种方法的效果,同时还加上了STAIR方法生成的结果,二者进行对比。经过Bokete网友的评估,STAIR方法仅收到了1.71颗星星,而NJM收的到了3.23颗星星。所以经过Funny Score的训练和自创的Bokete数据集,这种方法的表现还是不错的。
下面是NJM生成的几个例子,大家随意感受一下(原文是日语,为了方便阅读作者翻译成了英语)。


emmm……也许是将日语翻译成了英语的原因,一些文化元素在翻译过程中被丢掉了,在我们外国人看来还达不到令人笑到岔气的效果。不过,重要的是这篇论文“清奇”的研究方向嘛,配上今天的节日也让大朋友们开心一下~儿童节快乐!
原文地址:arxiv.org/pdf/1805.11850.pdf







