圆圈在动吗?这个骗过人眼的动图火了,LeCun解释原理:和CNN对抗攻击类似
金磊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
都说「眼见为实」,但真是这样吗?
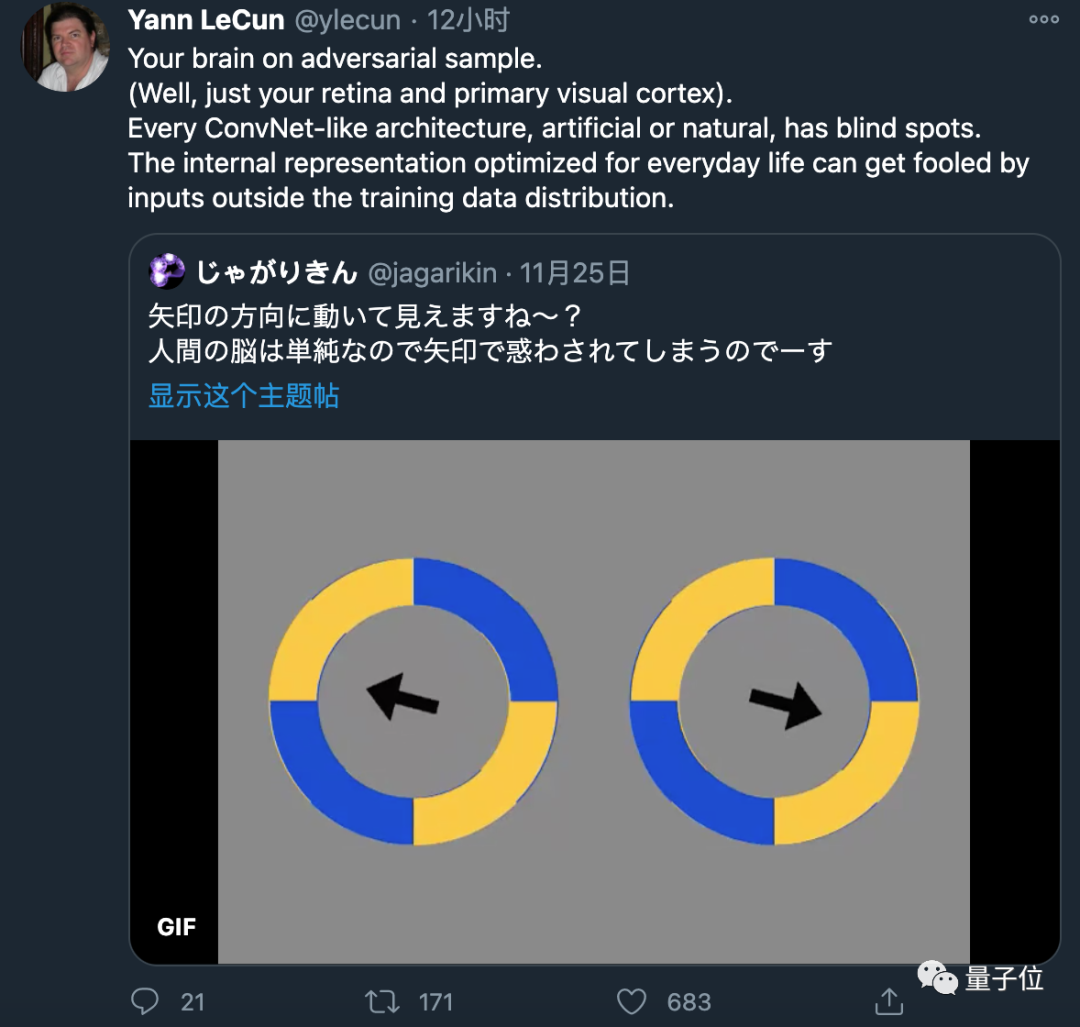
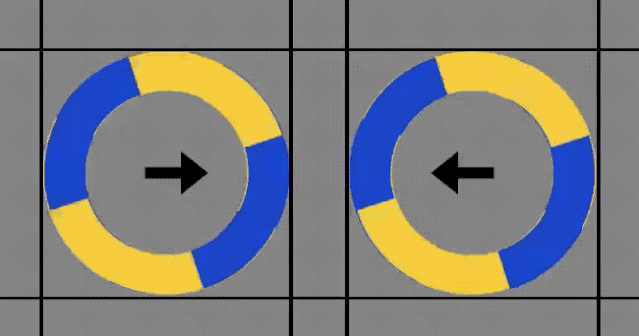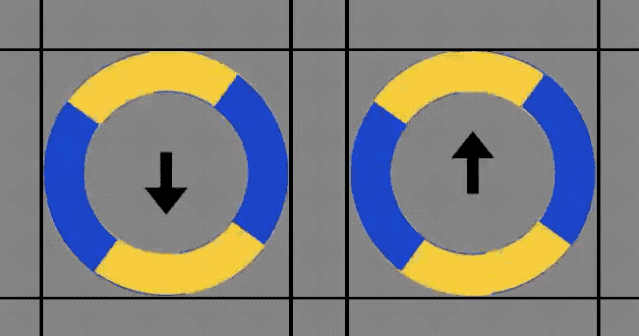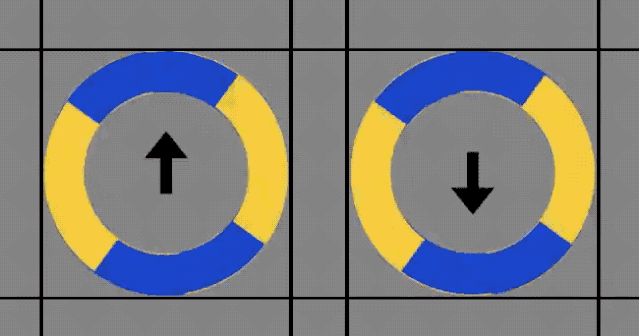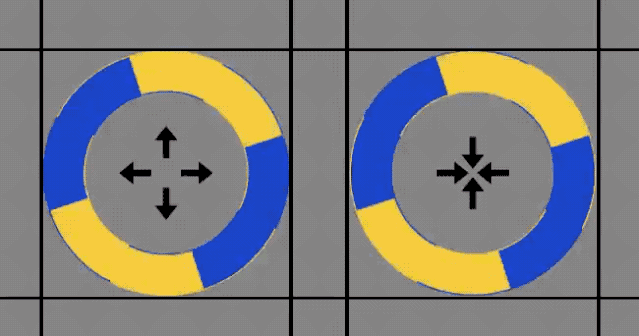
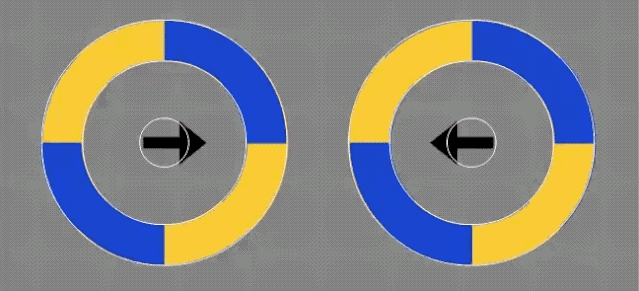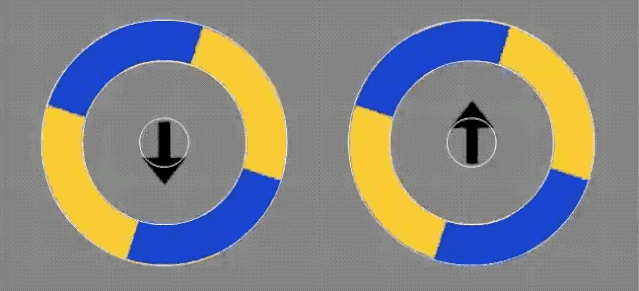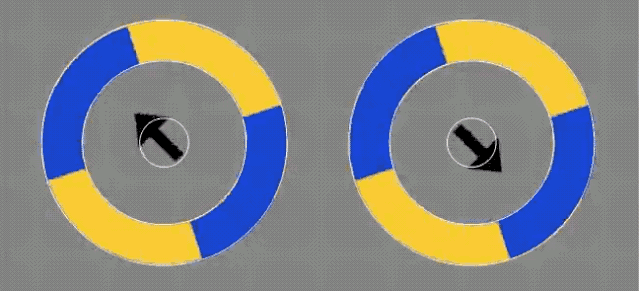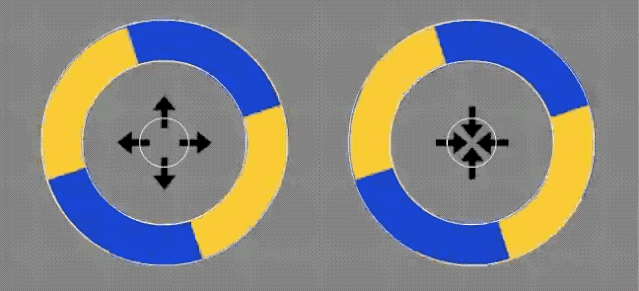
先来看下这张动图。
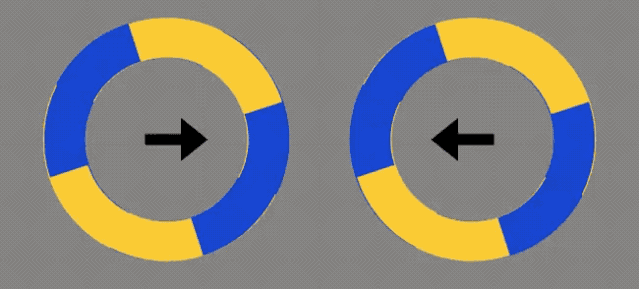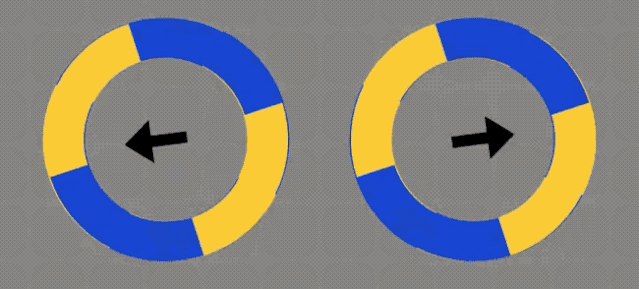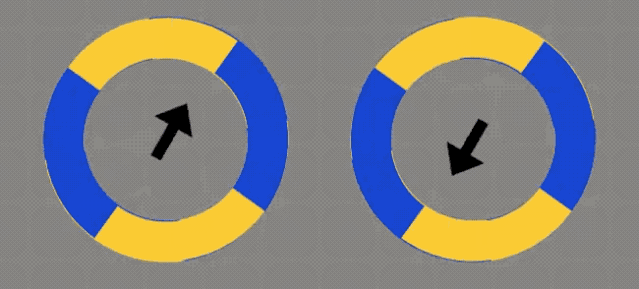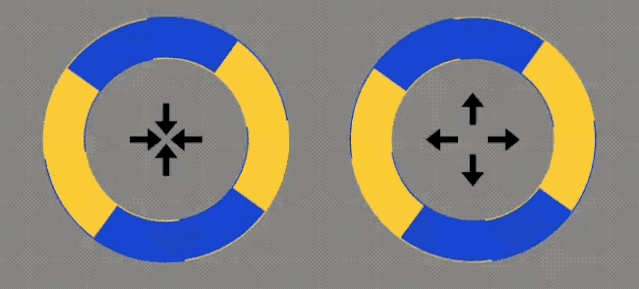
是不是感觉这2个圆圈,会随着箭头方向移动?
然而事实却是:
它们没有发生任何改变。
而就是这样一张动图,近日却在网上引发了热烈的讨论。
连深度学习三巨头之一的LeCun大神,也出面发表言论:
大脑的对抗性样本。
每个类似CNN的结构……都有盲点……会被愚弄。
那么这张动图到底暗含什么玄机?又为何让LeCun作出如此评价?
「忽悠」大脑的动图
对此,很多网友还是选择相信自己的眼睛,认为得它们就是在动;也有坚持说没动的。
于是他们找到各种办法来证明。
最简单的方法就是挡住箭头,效果是这样的。

「恐怕这种幻觉与箭头无关」,这位网友评价道。
接着,其他人便采取了更加「科学」的方法——画线。
可以明显看到,圆圈的转动确实没有超过标记线。
那是不是箭头发生了移动,才产生的错觉呢?
也有人做了实验。
也不难看出,箭头位置没有发生变化,而且第一个实验也证明了与箭头无关。
那这到底是怎么一回事?LeCun给出了正解:
它们是静态的。
黄色区域的外侧,有一条蓝色的细线;蓝色区域外侧,则有一条黄色的细线。

网友将圆圈放大后,也发现了这个隐藏的「猫腻」。
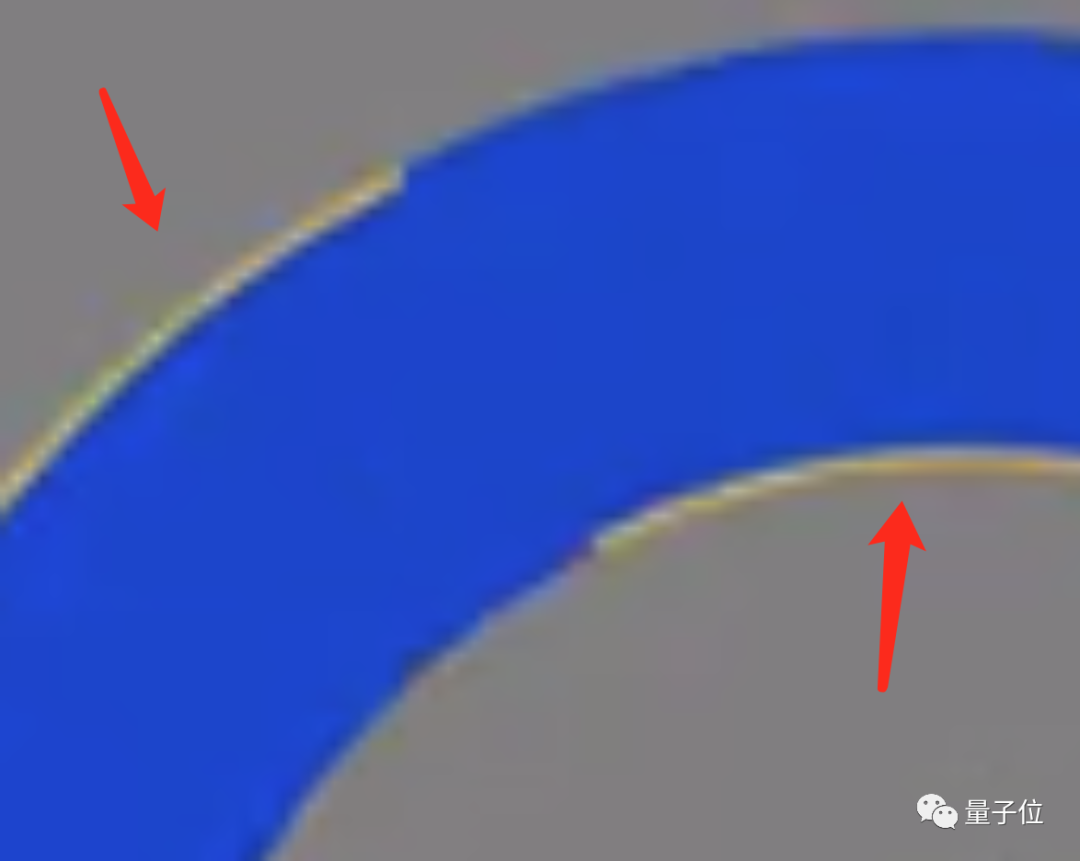
LeCun继续补充道:
你的视网膜→MT视觉通路,将圆周运动中的高对比度边缘,解释成了与边缘正交的运动。

例如CNN在「工作过程」中,也会提取图像中的一些边缘信息/特征。
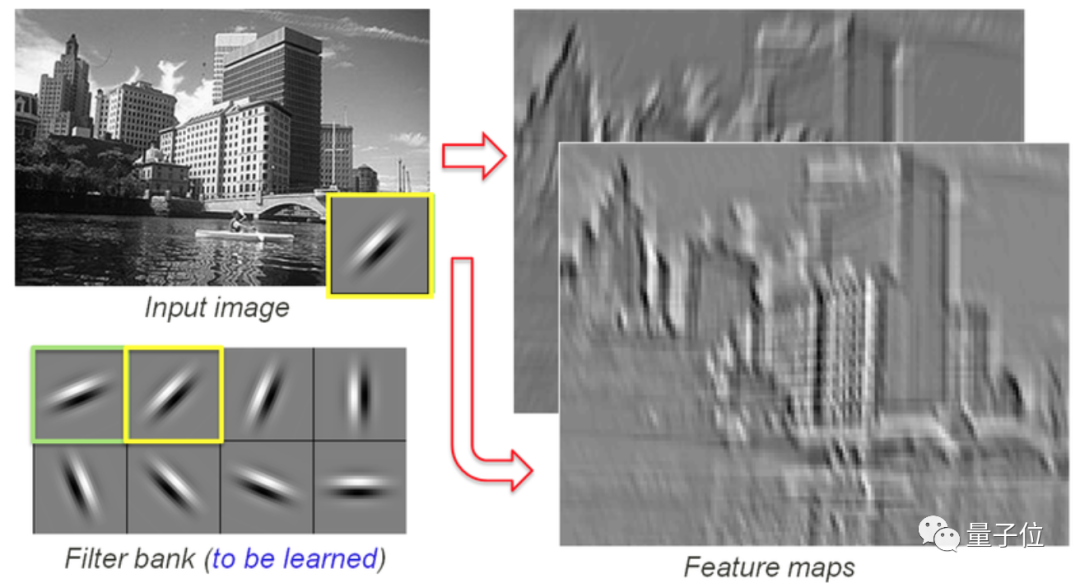
而这也正是LeCun在文章开头处评价的由来——大脑的对抗性样本。
他认为:
每一个类似CNN的架构,无论是人工的还是自然的,都有盲点。
它们会被训练数据分布之外的输入所愚弄。
LeCun说这话并不是空穴来风,而是在AI(尤其是计算机视觉)*相关的研究中,诸如此类的「忽悠」现象屡见不鲜。
「忽悠」AI的对抗性样本
对抗性样本,简单来说就是:
对输入数据样本,添加一些人无法观察到的干扰,导致模型以高置信度给出一个错误的输出。
一个非常经典的例子就是图像分类。

例如一张已经被分类为「熊猫」的图片,在加入一些干扰后,我们人类肉眼是无法察觉输出图像产生的变化。
但在AI眼里却截然不同,并以高置信度将输出图像分类为「长臂猿」。
至于其原理,可以引用Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images这篇文章中的图来示意:
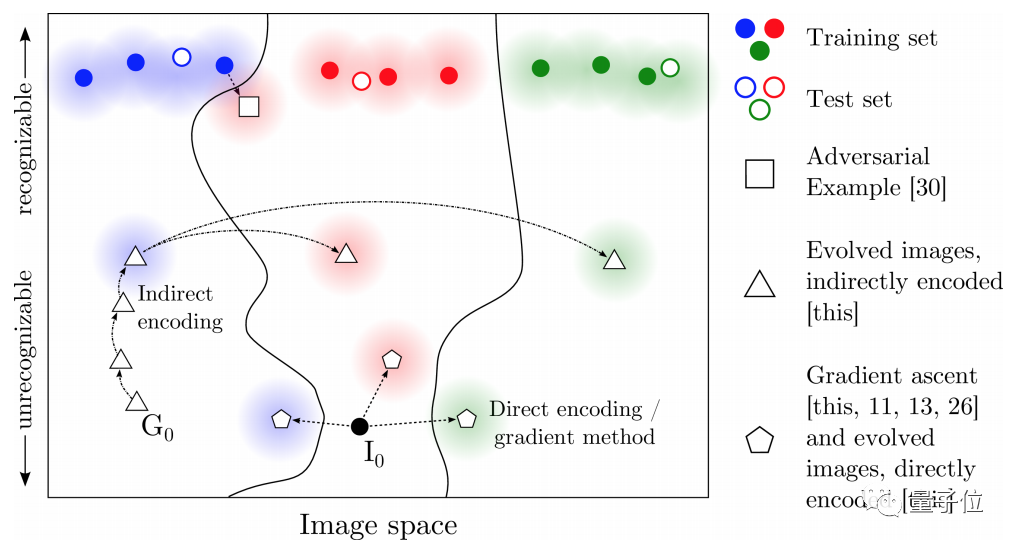
一种方法是从一个类别的样本出发,添加一些「小修改」,然后模型就会把修改后的样本,判定为另一类。
另外一种方法,就是利用分类不确定性。比如图中除了最上面部分的空间可以认为是数据存在概率极低的区域,从实际应用的角度甚至可以认为是完全不关心的区域。
而这样的对抗性样本,不仅仅是在图像分类任务中存在,在自动驾驶中也是常见的。
用一条2英寸的胶带,成功欺骗2016年版特斯拉的摄像头系统,诱使其出现了50英里/小时(80公里/小时)的异常加速。

欺骗后的效果是这样的:

而这样的问题,也成为了自动驾驶的一个安全隐患。
网友:LeCun,你说的不对
最后,对于LeCun说「大脑的对抗性样本」这句话,也成了网友们热议的一个焦点。
有网友非常直白地说:
这并不是一个很好的对抗性样本。

也有网友提出质疑:
这是人类视觉系统的一个对抗性例子,还是一个特征?
这看起来像是我们泛化能力的产物。

对此,你怎么看?
参考链接:
https://twitter.com/ylecun/status/1331590066272153600
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
量子位年度智能商业大会启幕,大咖已就位!
12月16日,李开复博士、尹浩院士、清华唐杰教授,以及来自小米、美团、爱奇艺、小冰、亚信、浪潮、容联、澎思、地平线、G7等知名AI大厂的大咖嘉宾将齐聚MEET2021大会,期待关注AI的朋友报名参会、共探新形势下智能产业发展之路。


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



