或许是迄今为止第一篇讲解 fps 计算原理的文章吧 | 开发者说·DTalk
前言
计算方法
adb shell dumpsys SurfaceFlinger --latency "SurfaceView - com.tencent.tmgp.sgame/com.tencent.tmgp.sgame.SGameActivity#0"1666666659069638658663 59069678041684 5906965415829859069653090955 59069695022100 5906967089423659069671034444 59069711403455 5906968794986159069688421840 59069728057361 5906970441512159069705420850 59069744773350 5906972076783059069719818975 59069761378975 5906973741600759069736702673 59069778060955 5906975456866359069753361528 59069794716007 5906977076163259069768766371 59069811380486 59069787649600......
fence 简析
fence 是什么
首先得先说明一下 App 绘制的内容是怎么显示到屏幕的:
fence in Code
fence driver
同步的核心实现
libsync
位于 system/core/libsync,libsync 的主要作用是对 driver 接口的封装
Fence 类
这个 Fence 类位于 frameworks/native/libs/ui/Fence.cpp,主要是对 libsync 进行 C++ 封装,方便 framework 调用
FenceTime 类
这个 FenceTime 是一个工具类,是对 Fence 的进一步封装,提供两个主要的接口——isValid() 和 getSignalTime(),主要作用是针对需要多次查询 fence 的释放时间的场景 (通过调用 Fence::getSignalTime() 来查询 fence 的释放时间)。通过对 Fence 进行包裹,当第一次调用 FenceTime::getSignalTime() 的时候,如果 fence 已经释放,那么会将这个 fence 的释放时间缓存起来,然后下次再调用 FenceTime::getSignal() 的时间,就能将缓存起来的释放时间直接返回,从而减少对 Fence::getSignalTime() 不必要的调用 (因为 fence 释放的时间不会改变)。
fence in Android
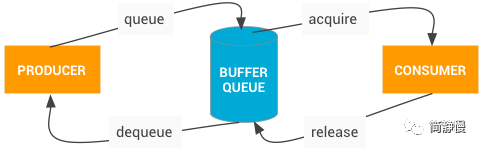
在 Android 里面,总共有三类 fence —— acquire fence,release fence 和 present fence。其中,acquire fence 和 release fence 隶属于 Layer,present fence 隶属于帧 (即 Layers):
-
acquire fence 前面提到,App 将 Buffer 通过 queueBuffer() 还给 BufferQueue 的时候,此时该 Buffer 的 GPU 侧其实是还没有完成的,此时会带上一个 fence,这个 fence 就是 acquire fence。当 SurfaceFlinger/ HWC 要读取 Buffer 以进行合成操作的时候,需要等 acquire fence 释放之后才行。
release fence
当 App 通过 dequeueBuffer() 从 BufferQueue 申请 Buffer,要对 Buffer 进行绘制的时候,需要保证 HWC 已经不再需要这个 Buffer 了,即需要等 release fence signal 才能对 Buffer 进行写操作。
present fence
present fence 在 HWC1 的时候称为 retire fence,在 HWC2 中改名为 present fence。当前帧成功显示到屏幕的时候,present fence 就会 signal。
原理分析
简单版
status_t SurfaceFlinger::doDump(int fd, const DumpArgs& args,bool asProto) NO_THREAD_SAFETY_ANALYSIS {...static const std::unordered_map<std::string, Dumper> dumpers = {......{"--latency"s, argsDumper(&SurfaceFlinger::dumpStatsLocked)},......};
从这里可以看到,我们在执行 dumpsys SurfaceFlinger 后面加的那些 --xxx 参数最终都会在这里被解析,这里咱们是 --latency,因此看 SurfaceFlinger::dumpStatsLocked:
void SurfaceFlinger::dumpStatsLocked(const DumpArgs& args, std::string& result) const {StringAppendF(&result, "%" PRId64 "\n", getVsyncPeriod());if (args.size() > 1) {const auto name = String8(args[1]);mCurrentState.traverseInZOrder([&](Layer* layer) {if (name == layer->getName()) {layer->dumpFrameStats(result);}});} else {mAnimFrameTracker.dumpStats(result);}}
从这里就能够看到,这里先会打印当前的 VSYNC 间隔,然后遍历当前的 Layer,然后逐个比较 Layer 的名字,如果跟传进来的参数一致的话,那么就会开始 dump layer 的信息;否则命令就结束了。因此,很多人会遇到这个问题:
❔ 为什么执行了这个命令却只打印出一个数字?
✔ 其实这个时候您应该去检查您的 Layer 参数是否正确。
接下来 layer->dumpFrameStats() 会去调 FrameTrack::dumpStats():
void FrameTracker::dumpStats(std::string& result) const {Mutex::Autolock lock(mMutex);processFencesLocked();const size_t o = mOffset;for (size_t i = 1; i < NUM_FRAME_RECORDS; i++) {const size_t index = (o+i) % NUM_FRAME_RECORDS;base::StringAppendF(&result, "%" PRId64 "\t%" PRId64 "\t%" PRId64 "\n",mFrameRecords[index].desiredPresentTime,mFrameRecords[index].actualPresentTime,mFrameRecords[index].frameReadyTime);}result.append("\n");}
NUM_FRAME_RECORDS 被定义为 128,因此输出的数组有 127 个。每组分别有三个数字—— desiredPresentTime,actualPresentTime,frameReadyTime,每个数字的意义分别是:
desiredPresentTime
下一个 HW-VSYNC 的时间戳
actualPresentTime
retire fence signal 的时间戳
frameReadyTime
acquire fence signal 的时间戳
从 dumpsys SurfaceFlinger --latency 获取到最新 127 帧的 present fence 的 signal time,结合前面对于 present fence 的说明,当某帧 present fence 被 signal 的时候,说明这一帧已经被显示到屏幕上了。因此,我们可以通过判断一秒内有多少个 present fence signal 了,来反推出一秒内有多少帧被刷到屏幕上,从而计算出 fps。
复杂版
-
这个 actualPresentTime 是从哪来的? 假设要统计 fps 的 Layer 没有更新,但是别的 Layer 更新了,这种情况下 present fence 也会正常 signal,那这样计算出来的 fps 是不是不准啊?
void FrameTracker::processFencesLocked() const {FrameRecord* records = const_cast<FrameRecord*>(mFrameRecords);int& numFences = const_cast<int&>(mNumFences);for (int i = 1; i < NUM_FRAME_RECORDS && numFences > 0; i++) {size_t idx = (mOffset+NUM_FRAME_RECORDS-i) % NUM_FRAME_RECORDS;...const std::shared_ptr<FenceTime>& pfence =records[idx].actualPresentFence;if (pfence != nullptr) {// actualPresentTime 是在这里赋值的records[idx].actualPresentTime = pfence->getSignalTime();if (records[idx].actualPresentTime < INT64_MAX) {records[idx].actualPresentFence = nullptr;numFences--;updated = true;}}......
struct FrameRecord {FrameRecord() :desiredPresentTime(0),frameReadyTime(0),actualPresentTime(0) {}nsecs_t desiredPresentTime;nsecs_t frameReadyTime;nsecs_t actualPresentTime;std::shared_ptr<FenceTime> frameReadyFence;std::shared_ptr<FenceTime> actualPresentFence;};
从上面的代码可以看出,actualPresentTime 是调用 actualPresentFence 的 getSignalTime() 赋值的。而 actualPresentFence 是通过 setActualPresentFence() 赋值的:
void FrameTracker::setActualPresentFence(std::shared_ptr<FenceTime>&& readyFence) {Mutex::Autolock lock(mMutex);mFrameRecords[mOffset].actualPresentFence = std::move(readyFence);mNumFences++;}
setActualPresentFence() 又是经过下面的调用流程最终被调用的:
SurfaceFlinger::postComposition()\_ BufferLayer::onPostCompostion()
这里重点看一下 SurfaceFlinger::postComposition():
void SurfaceFlinger::postComposition(){......mDrawingState.traverseInZOrder([&](Layer* layer) {bool frameLatched =layer->onPostComposition(displayDevice->getId(), glCompositionDoneFenceTime,presentFenceTime, compositorTiming);......
回忆一下我们前面的问题:
❔ 假设要统计 fps 的 Layer 没有更新,但是别的 Layer 更新了,这种情况下 present fence 也会正常 signal,那这样计算出来的 fps 是不是不准啊?
答案就在 mDrawingState,在 Surfacelinger 中有两个用来记录当前系统中 Layers 状态的全局变量:
-
mDrawingState mDrawingState 代表的是上次 "drawing" 时候的状态
mCurrentState
mCurrentState 代表的是当前的状态因此,如果当前 Layer 没有更新,那么是不会被记录到 mDrawingState 里的,因此这一次的 present fence 也就不会被记录到该 Layer 的 FrameTracker 里的 actualPresentTime 了。
再说回来,SurfaceFlinger::postComposition() 是 SurfaceFlinger 合成的最后阶段。presentFenceTime 就是前面的 readyFence 参数了,它是在这里被赋值的:
mPreviousPresentFences[0] = mActiveVsyncSource? getHwComposer().getPresentFence(*mActiveVsyncSource->getId()): Fence::NO_FENCE;auto presentFenceTime = std::make_shared<FenceTime>(mPreviousPresentFences[0]);
而 getPresentFence() 这个函数,就把这个流程转移到了 HWC 了:
sp<Fence> HWComposer::getPresentFence(DisplayId displayId) const {RETURN_IF_INVALID_DISPLAY(displayId, Fence::NO_FENCE);return mDisplayData.at(displayId).lastPresentFence;}
至此,我们一路辗转,终于找到了这个 present fence 的真身,只不过这里它还蒙着一层面纱,我们需要在看一下这个 lastPresentFence 是在哪里赋值的,这里按照不同的合成方式位置有所不同:
DEVICE 合成
DEVICE 合成的 lastPresentFence 是在 HWComposer::prepare() 里赋值:
status_t HWComposer::prepare(DisplayId displayId, const compositionengine::Output& output) {......if (!displayData.hasClientComposition) {sp<Fence> outPresentFence;uint32_t state = UINT32_MAX;error = hwcDisplay->presentOrValidate(&numTypes, &numRequests, &outPresentFence , &state);if (error != HWC2::Error::HasChanges) {RETURN_IF_HWC_ERROR_FOR("presentOrValidate", error, displayId, UNKNOWN_ERROR);}if (state == 1) { //Present Succeeded.......displayData.lastPresentFence = outPresentFence;
这个函数非常重要,它通过一系列的调用:
HWComposer::prepare()\_ Display::presentOrValidate()\_ Composer::presentOrValidateDisplay()\_ CommandWriter::presentOrvalidateDisplay()
最终通过 HwBinder 通知 HWC 的 Server 端开始进行 DEVICE 合成,Server 端在收到 Client 端的请求以后,会返回给 Client 端一个 present fence (时刻记住,fence 用于跨环境的同步,例如这里就是 Surfacelinger 和 HWC 之间的同步)。然后当下一个 HW-VSYNC 来的时候,会将合成好的内容显示到屏幕上并且将该 present fence signal,标志着这一帧已经显示在屏幕上了。
GPU 合成
GPU 合成的 lastPresentFence 是在 presentAndGetPresentFences() 里赋值:
status_t HWComposer::presentAndGetReleaseFences(DisplayId displayId) {......displayData.lastPresentFence = Fence::NO_FENCE;auto error = hwcDisplay->present(&displayData.lastPresentFence);
总结
说了这么多,一句话总结计算一个 App 的 fps 的原理就是:
长按右侧二维码
查看更多开发者精彩分享

"开发者说·DTalk" 面向中国开发者们征集 Google 








