奇异值分解:协同过滤的前奏,你是SVD(上)

一 :内容预告
所以这周没写新东西,还是发一篇旧文,关于奇异值分解(Singular Value Decomposition,SVD)。
奇异值分解是一种非常重要的降维方法,主成分分析法(PCA)、潜在语义分析(LSA)和协同过滤(CF)都用到了奇异值分解。
这篇文章以数学推导为主,一步步搞清楚奇异值分解是什么。当然相信我,这些推导比较简单。
本文关注以下问题:
2:奇异值分解的流程总结和案例;
3:用奇异值分解进行降维;
4:特征分解、奇异值分解和主成分分析法的关系;
5:奇异值分解在词向量降维中的应用。
二:奇异值分解的数学公式
一个n×m的矩阵X,其奇异值分解定义为:
其中U称为左奇异矩阵,是一个n×n的正交矩阵,即满足UTU=E,UT=U-1。
而V称为右奇异矩阵,是一个m×m的正交矩阵。
Σ为n×m的对角矩阵,对角线上的非零元素是奇异值(Singular Value)。
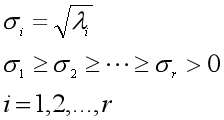
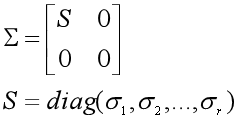
然后看右奇异矩阵V是什么。
将V写成列向量的形式(v1, v2, ...vr,... vm),那么V的列向量是实对称矩阵XTX的单位特征向量,也就是有:
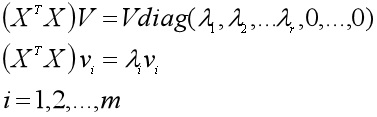
(一)第一种做法
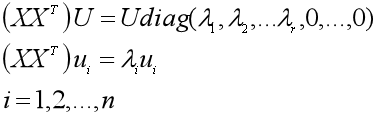

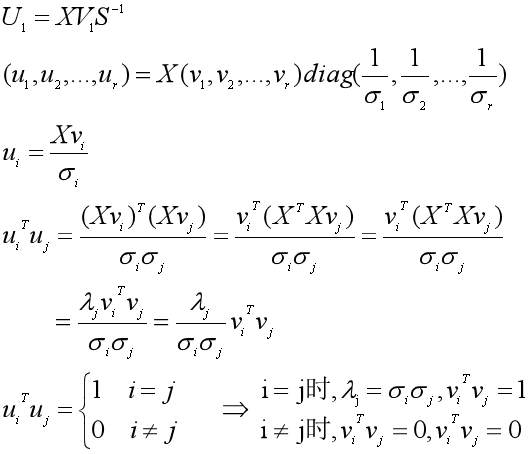
三:计算流程和案例
如果有一个n×m的矩阵X,秩为r,那么对X进行奇异值分解的一种做法是:
(1)求出实对称矩阵XTX的m个特征值λi(其中非零的有r个)和m个单位特征向量vi;
(2)把m个特征值λi从大到小排序,求出奇异值σi=√λi(i=1,...,r),并得到S=diag(σ1,σ2,...,σr);
(3)相应地把m个特征向量vi进行排列,就可以得到右奇异矩阵V=(v1, v2, ...vr,.. vm),同时得到非零特征值的特征向量矩阵V1=(v1, v2, ...vr);
(4)由XV1S-1求出n×r的矩阵U1,写成U1=(u1, u2, ...ur);
(5)构造n-r个列向量ui,每个都满足与其他n-1个列向量正交且是单位向量的条件,写成U2=(ur+1, ur+2, ...un),于是得到左奇异矩阵U=(U1, U2)=(u1, u2, ... ur, ..., un);
(6)得到X的奇异值分解:
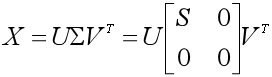
接下来我们就举一个简单的例子,按这个流程走一遍。
问题:
对以下的矩阵X进行奇异值分解。

求解:

四:奇异值分解降维
用奇异值分解进行降维,需要用到线性代数里的分块矩阵理论。
可以看到,矩阵Σ由奇异值和很多0元素构成,强迫症的我看到这些0元素比较难受,尤其是对角线上的!
所幸我们可以用矩阵分块的方法,把Σ中为0的对角元素抛弃。
同样,X是n×m的矩阵,右奇异矩阵V中的前r个列向量为V1=(v1, v2, ...vr),左奇异矩阵U中的前r个列向量为U1=(u1, u2, ...ur),S=diag(σ1,σ2,...,σr)是奇异值构成的对角矩阵。
则可以将奇异值分解化简为X=U1SV1T。

我们是用分块矩阵对奇异值分解进行化简的,现在让我们分块到底!
我们知道U1中有r个列向量,我们再将其分块,比如我们想把维度降到d维(d<r),那么把U1分为两个子矩阵U1=[U11, U12],有U11=[u1,u2,...,ud],U12=[ud+1,ud+2,...,ur]。
同样把V1进行分块,得到V1=[V11, V12],V11=[v1,v2,...,vd],V12=[vd+1,vd+2,...,vr]。

于是我们可以把X=U1SV1T也分块成:

因此如果我们想把维度降到d维,那么就让X≈U11S1V11T。
这样我们就舍弃了r-d维的信息U12S2V12T,那不免让人担心,信息是否会损失太多。
所以如何计算损失的信息量呢?
主成分分析法的文章提到了,可以用数据集的方差来衡量数据所包含的信息量的大小,方差越大,包含的信息越多。
而方差又和特征值密切相关,在某些特殊情况下方差就等于特征值。
于是我们隐约感觉到,可以用奇异值或者特征值来度量矩阵的信息量。
是的,矩阵X的信息量就定义为所有奇异值的平方和,也就是XTX的特征值之和:F=λ1+λ2+…+λr
那么降维后的矩阵U11S1V11T的信息量为:
F1=λ1+λ2+…+λd
而损失的信息为矩阵U12S2V12T的信息量:
F2=λd+1+λd+2+…+λr
于是损失的信息量占总信息量的比例为:
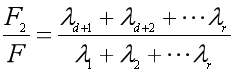
这样我们就可以清晰地看到,降至d维后,信息量是否损失太大,是否让我们无法承受。
不过好在S中的奇异值是降序排列的,而且数值一般下降得特别快,前面少数几个奇异值的平方和占总信息量的比例一般就已经很大了。
好,到这里我们就明白了,怎么度量降维后的矩阵所包含的信息量。
然后,作为好奇宝宝的你也许会问,为什么矩阵X的信息量就是所有奇异值的平方和呢?
好的,邓紫棋已经听到你的呼唤了,返场唱最后一首歌。
这里是用矩阵X的F范数的平方来度量信息量。
什么是矩阵的F范数呢?
矩阵的F范数定义为矩阵中每个元素平方之和的平方根,那么F范数的平方就是每个元素的平方和。

因为矩阵X每个元素的平方和(F范数的平方)是方阵XTX的对角线元素之和(迹),而方阵XTX的对角线元素之和(迹)就是其特征值之和,也就是奇异值的平方和。
所以矩阵X的信息量就是所有奇异值的平方和。
下一篇介绍奇异值分解和主成分分析法的关系,以及奇异值分解在词向量降维中的应用。
参考资料:
1、《A Tutorial on Principal Component Analysis. Derivation, Discussion and Singular Value Decomposition》
2、《A Singularly Valuable Decomposition: The SVD of a Matrix 》
END
推荐阅读
百度PaddleHub NLP模型全面升级,推理性能提升50%以上
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





