携程框架团队对于应用监控系统的探索与思考

随着市场环境的变化以及国际化的进程,企业的各种对内、对外需求也日益增长。服务化的架构以及容器化的应用加速了各种功能、产品的迭代与更新。随之而来,我们也面临着一个不断膨胀,日渐复杂的系统。
复杂度的成倍增加对故障的根因分析、执行流程的调优以及数据链路的追踪带来了极大的挑战。因此,对于一个企业级的应用监控系统来说,也应该持续地发展、演化,才能更好地解决痛点,提高用户的整体效率。
如今,应用的执行流程往往由种种内外部依赖、软硬件结合构成。相应的,针对不同的需求,监控领域也有着业务指标监控、应用监控以及基础设施监控等等类别。
对于应用监控系统来说,它的主要职责是管理、监控一个软件应用的性能与可用性 [1]。在服务化场景下,它应致力于快速监测并诊断出一个复杂的服务调用链路中的潜在问题,帮助研发人员更好地维护服务的质量 [2]。
一个完整的应用监控体系往往包含着多种组成,例如客户端的日志以及宿主机的心跳状态等。随着系统复杂度的增加,每一个相关的组件都有可能含有帮助用户定位系统异常根因的线索。因此,对于种种不同来源的原始数据,都应该进行归类、量化,这样才能帮助用户在遇到问题或者维护应用的时候更加有的放矢。
不同的系统有着不同的监控粒度以及目标着重点,因而它们的度量也不尽相同。依托对于携程当前服务应用的场景以及对于外部资源的参考,我们对于应用监控系统的作用域进行了如下定义 [3]:
1、Trace:即一次完整的事务调用请求。比方说一个用户的下单请求,经过层层服务预处理,到支付服务成功,数据落库,成功返回,这就是一条完整的 Trace 。Trace 最大的特点就是它含有上下文环境,通常来说会由一个唯一的 ID 来进行标识。一个 Trace 内可能有多个不同的事务 (Transaction) 以及标志事件 (Event) 组成。
2、Log:即日志。代表了用户主动记录的离散的数据。通常来说就是用户采用 logging 组件输出到日志文件的具有 WARN,INFO,ERROR 等用来表示不同执行状态级别的信息。这些日志信息在用户进行问题分析判断时可以提供更为详尽的线索。
3、Metric:代表了用户定义关心的或者通用的预定义的一些运行时指标。通常来说,Metric 具有时序可累积性。根据不同的粒度需求,Metric 可以做到小时级、分钟级、秒级等。通常来说, Metric 是数据采集项目的聚合,旨在为用户展示某个指标在某个时段的运行状态。
4、Report:报表是针对某种特定领域,经过对收集而来的各种数据进行统计、分析而产生的关键信息展示载体。报表含有丰富的信息,通过报表用户可以获得关于特定领域指标集的多维信息,从而更好地作出排障、调优决策。
服务化架构下,以往的单一应用被拆分为一个个不同维度的服务,每个完整的事务逻辑往往由多种外部请求构成。调用关系的复杂性增加了发现应用问题的难度。同时,多个服务间的依赖关系,依赖合理性与调用性能分析以及资源容量规划也成为了需要考虑的问题。
由此可见,一个完整的分布式调用链路追踪是应用监控体系中举足轻重的一环。如果说 Metric 和 Report 是具有统计性的较粗粒度的数据归纳结果,分布式链路追踪 (Trace) 就是一个细粒度的独立完整的调用记录。因此,Trace 提供的翔实信息对于理解系统行为、应用长尾分析以及故障根因分析有着很大助益。
当下也有许多的监控组件支持分布式调用链追踪。例如开源的 Zipkin,Skywalking,Pinpoint,Jaeger,CAT 以及商业的 NewRelic APM 等产品。
它们的理论模型大多都是借鉴或者近似于 Google Dapper 这篇论文中提到的思想 [4]。每个 Trace 由树形结构组织的 Span 构成,每个 Span 代表了某次具有特定耗时的外部调用,例如一次 RPC 请求或者一次 DB 操作。与 Dapper 以及 OpenTracing 的思想类似 [5], 我们将 Trace 内的调用链路组织成一个个事务 ( Transaction ),每个事务含有自己的操作 (Operation), 目标 (Target) 以及属性 (Properties)。
比方说,如今有许多服务都会大量的采用 Redis 作为数据缓存,一次这样的操作就是一种操作 Redis 的 Transaction。通过设置该事务的目标以及属性 (比方说将某次 Redis 操作的 Key 置为某种属性),用户可以更详尽地了解这次操作的流程与内容。
同时,对于不具备时间跨度的某些标识类事件,我们采用 Event 进行标识。这可以帮助我们快速定位、了解到该操作的执行路径。如下就是一个典型的 Redis Transaction:

通过 Trace 及其丰富的层级、属性, 我们能够更好的理解整个系统的运行流程,更快地识别耗时过长的链路。通过链路抽样的分析比较不同版本下服务的性能表现。
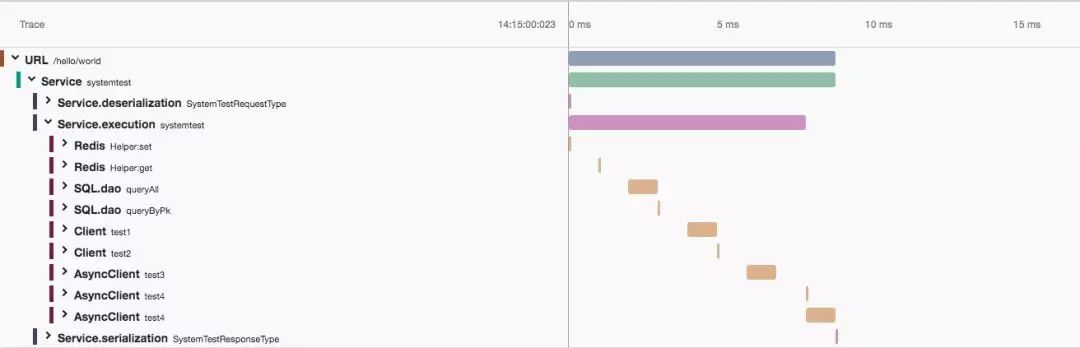
当服务发生异常时,一个完整的 Trace 也可以帮助用户快速定位问题根因。异常状态会从异常产生的具体节点上浮到对应的事务层级。这样的组织方式有助于排障人员发现到底是哪一个下游服务,哪一个 DB 还是自身执行发生了问题, 同时异常抛出时的 StackTrace 也会被附加到对应的 Transaction 中,方便用户回溯异常产生的现场。
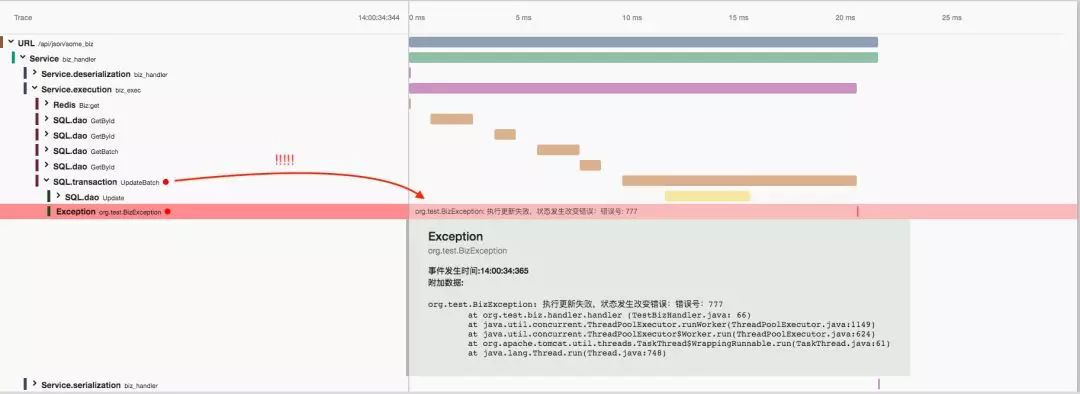
分布式的调用链路追踪具有很明显的层级关系,无论是性能调优亦或是异常分析,往往都能通过不断地定位、下钻,缩小目标范围,最终找到根因。
作为一个应用监控系统重要的一环,Trace 能够对关注于服务性能、质量的人提供一定的帮助。对于开发人员来说,每个应用的研发人员都应该关注并维护好自己的服务质量。
所谓服务质量,包含了响应时间(性能),错误率,稳定性等多种特性。对于性能需求,Trace 的记录天然的展示了该调用链路的耗时分布,通过对调用链路中对应目标的事务的分析,开发人员可以快速地定位系统交互链路上的瓶颈,从而更好地对症下药。
与此同时,一个良好的服务也应该具有高稳定性。特别是对于直接与客户打交道的业务来说,一次缓慢的调用就有可能意味着一个潜在客户的流失。监控系统应该收集并分析包含长尾调用等的 Trace ,通过这样的记录我们能够较快地发掘出造成长尾的原因,尽可能的使每次调用维持在预期的延时之内。
与开发人员不同,测试人员更关注于系统的准确性,以及新旧版本应用在执行上的差异。通过具有完整层级组织以及特殊事件标识 (Event) 的 Trace,测试人员可以更好地了解系统行为以及执行路径。一方面,Trace 可以展示出该次执行的正确性,另一方面,通过设计、实施不同执行路径的测试,可以做到更高的覆盖率,减少系统出现异常的可能。
对于应用监控运维人员来说,故障的及时发现以及根因分析相对来说是一个更为重要的目标。Trace 的异常节点高亮以及异常状态上浮可以更好的辅助定位问题的发生源。通过事务记录下的属性,问题可以更进一步地被缩小到调用目标、对应操作甚至是发生的基础设施的级别 ( Redis 操作、Key、所在 IP,或者是 MySQL 对应的 DB、执行语句等 ),进而可以制定出对应的解决方案。
应用监控系统的主要目的是帮助用户监控、维护一定的服务质量。稳定性对于一个服务来说也是一个至关重要的指标。
对此,单次的 Trace 并不能很好的展示一定时段内的服务表现。在分布式、服务化的场景下,针对一些常用的调用,我们引入了“组成成分”的概念。
比方说,在一段时间内,针对某个特定的 DB 的 SELECT 操作就属于这个服务的调用链路的一个成分。与此相近,特定的 Redis 操作,或者外部服务调用也是成分的一种。
通过对于成分指标的分析,将其聚合成一个成分分析的报表。成分分析报表展示的是对应服务在其执行路径上各个不同事务的表现情况。一个典型的成分报表构成如下:
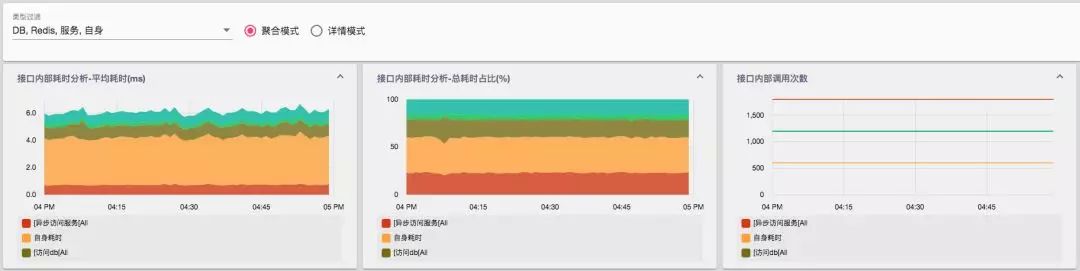
成分报表分析了各种不同成分的响应时间、被调用次数以及该成分在总体耗时内的占比。成分能够帮助用户整体掌握系统的运行状态。多样化的成分聚合、下钻能够为分布式系统的各调用链路分析提供依据。
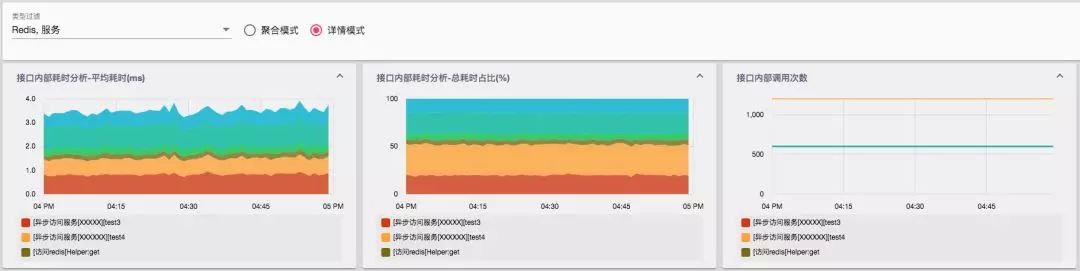
目前来说,成分数据做到了秒级收集,分钟级聚合。在异常发生时,通过对于特定时段的成分进行下钻,也可以帮助我们分析、追溯调用链路中出现问题的根源。
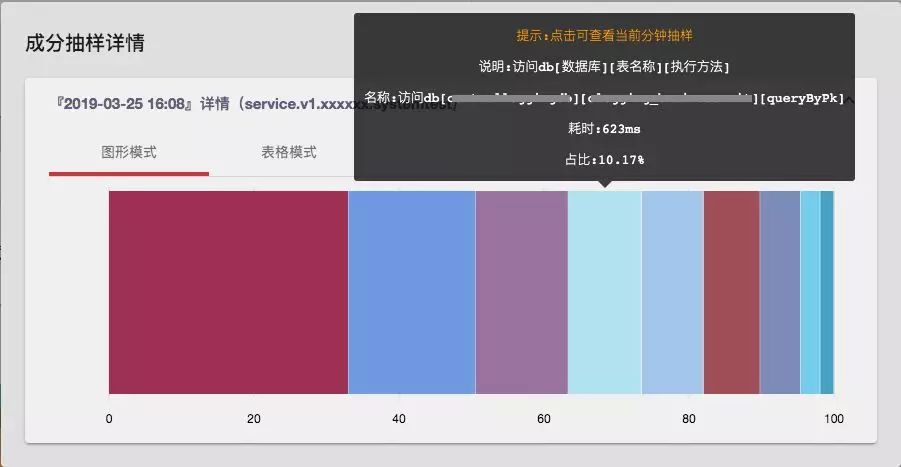
当系统出现故障时,往往也伴随着成分指标的异常。如下述示例中, 服务的耗时出现了突增,收到了告警。为了定位到是整个调用链路中的哪一部分出现了问题,可以查看对应时间段的成分分析。
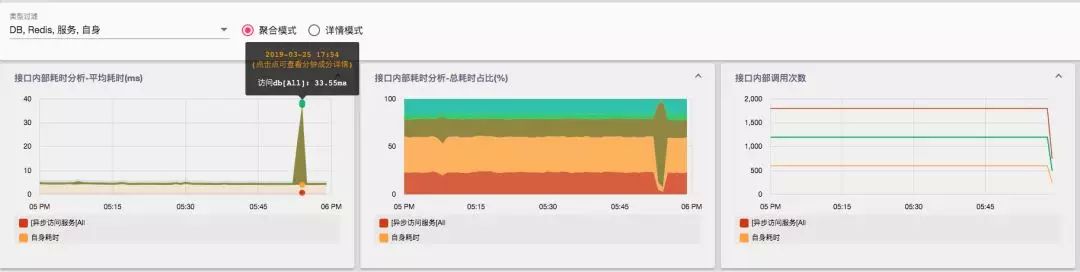
观察得到,在这一分钟内服务对各个外部链路的访问次数没有明显异常。但是数据库的访问时间出现了突增,可以明显看到访问数据库对应的成分的耗时占比在整个调用中的比例扩大了。继而,我们去查询对应现象发生的当前分钟的情况,通过详情面版继而可以定位到是针对特定的数据库、表的访问出现了异常。在此之后,通过收集而来的异常 Trace,可以进而为后续定位服务发生耗时异常的根因分析提供线索。
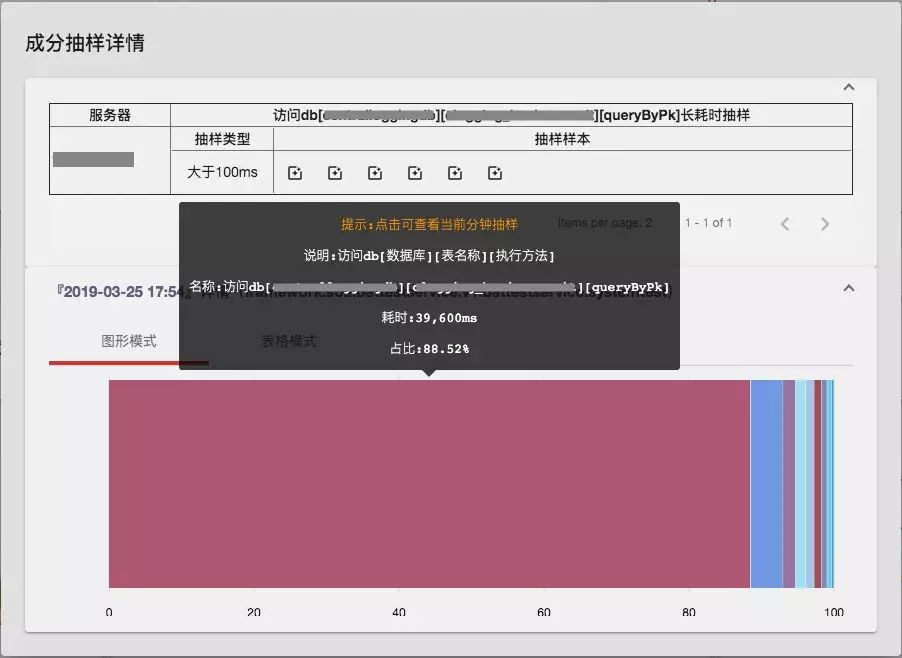
在持续演进的过程中,我们也对现有的系统在易用性、可用性方面进行了反思。
对于一个应用监控系统来说,不断地做“加法”,收集、分析并不断完善从软件到硬件等方方面面的数据指标固然不可或缺,但是善用“减法”,去粗取精反而有的时候更能使用户有的放矢。
现如今,大多数应用监控系统都能够收集并提供多种指标的展示。对于较为没有经验的用户来说,他们往往在遇到问题时会不知道应该从哪里下手。与之相反,有经验的同事往往有他们自己的排障习惯,他们能在各种系统的各种指标看板中来回穿梭,最终一步步缩小范围,找到原因。
因此,我们将思维反转了一下,不通过堆砌数据,而是依托于问题的场景,通过与有丰富排障经验的同事进行沟通,将数据整合成一个个具有特定排障目的的模块。
对于一个服务化的场景中,可能会发生服务耗时突增,服务出现错误以及服务调用存在长尾等多种潜在问题。举例说来,针对服务耗时异常场景,我们组织整理了一个专门用于耗时问题排障的模块。外部调用方的异常流量,内部调用链路成分的异常,应用的 GC 情况以及运行时宿主机的负载都可能导致服务时间出现异常。通过将对应指标进行有机聚合,用户可以学习他人的经验, 从而进行更有效的排障。
对于应用监控领域我们仍在不断地探索、完善中。文中内容如有任何错误之处还望不吝斧正。有任何的意见、建议,也欢迎在评论区探讨。
引用
[1] Wikipedia contributors. “Application performance management.”/Wikipedia, The Free Encyclopedia/. Wikipedia, The Free Encyclopedia, 7 Mar. 2019. Web. 24 Mar. 2019.
[2] Wikipedia contributors. “Application service management.”/Wikipedia, The Free Encyclopedia/. Wikipedia, The Free Encyclopedia, 2 May. 2018. Web. 24 Mar. 2019.
[3] Peter Bourgon. “Metrics, tracing, and logging.”, 21 Feb 2017.
[4] Sigelman, Benjamin H., et al. “Dapper, a large-scale distributed systems tracing infrastructure.” (2010).
[5] OpenTracing contributors. “https://opentracing.io/docs/overview/spans/”.
作者简介
鄞劭涵,携程框架架构研发部高级软件工程师,爱丁堡大学高性能计算专业硕士。目前主要从事应用监控系统以及消息队列相关基础框架的研发。
活动推荐
各互联网公司的一线专家也在不断提升运维能力,从被动救火式运维向主动精细化运维实践、基于机器学习的智能运维实践、基于 Kubernetes 的自动化运维实践、全链路日志监控实践等方面转换。QCon 北京 2019 可能会有适合你业务的方案:
云原生架构下的混沌工程实践
5G 时代的 CDN 运维平台实践
混合云管下的自动化运维平台架构
Kubernetes 日志平台建设最佳实践
点击 「 阅读原文 」或识别二维码查看大会日程,现在购票即享 9 折限时折扣,立减 880 元,团购还有更多优惠!有任何问题欢迎联系票务小姐姐 Ring:13269076283,微信:qcon-0410





