PPDet:减少Anchor-free目标检测中的标签噪声,小目标检测提升明显


简介

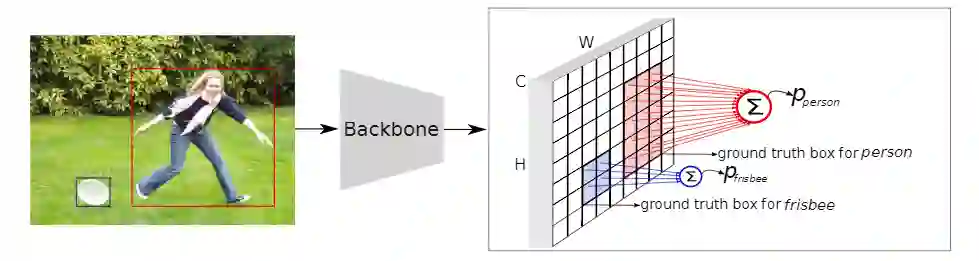
本文方法
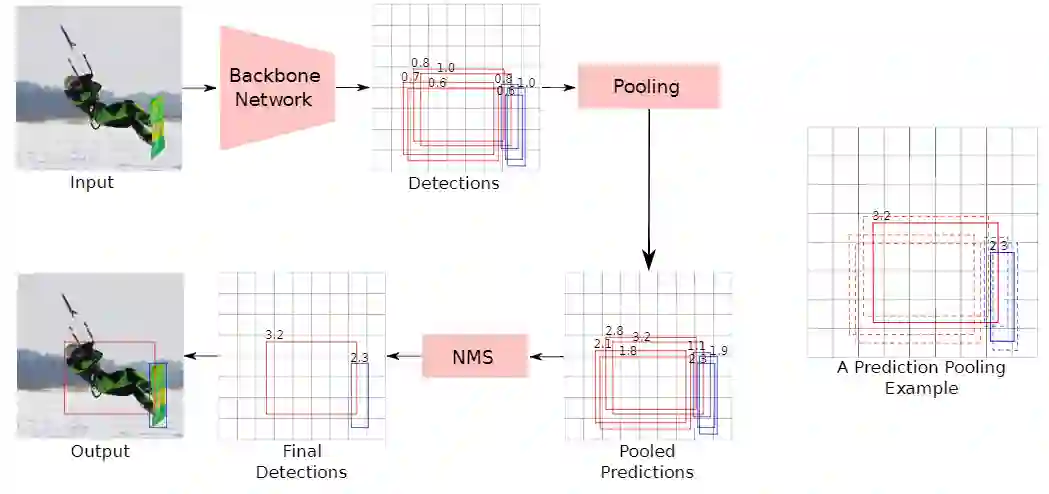
2、 Inference推理
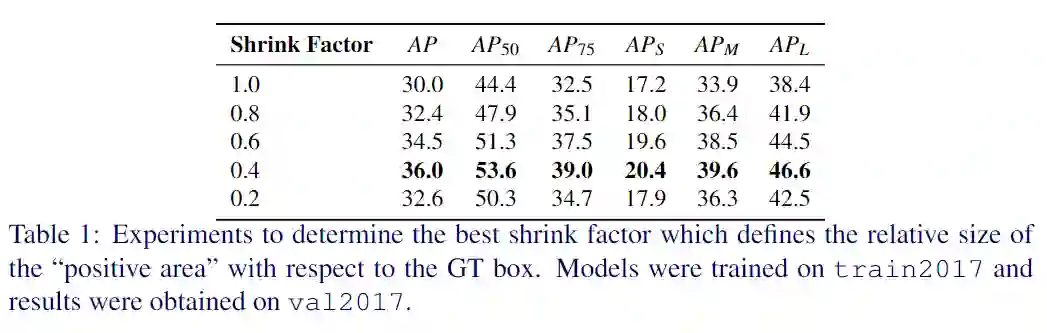
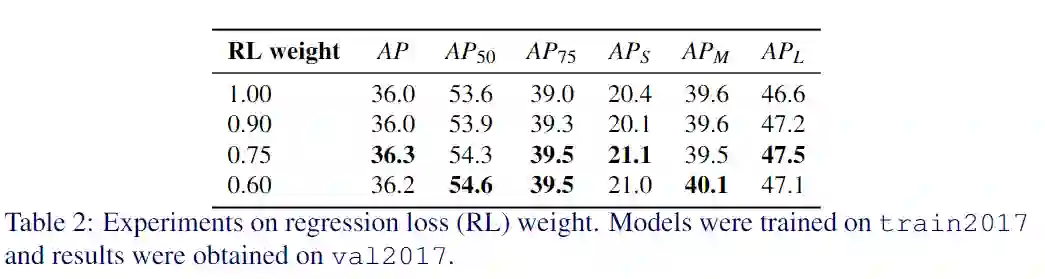
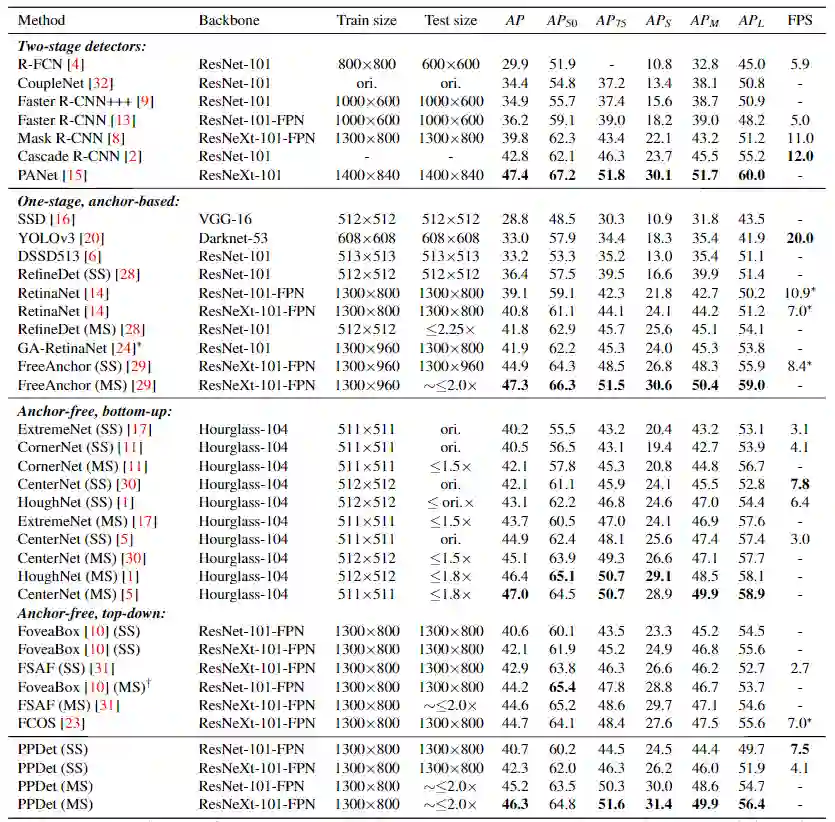
实验与结果

点击阅读原文,直达NeurIPS小组~
登录查看更多
相关内容
Arxiv
3+阅读 · 2019年3月20日


相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年3月20日