测试对比TensorFlow、MXNet、CNTK、Theano四个框架
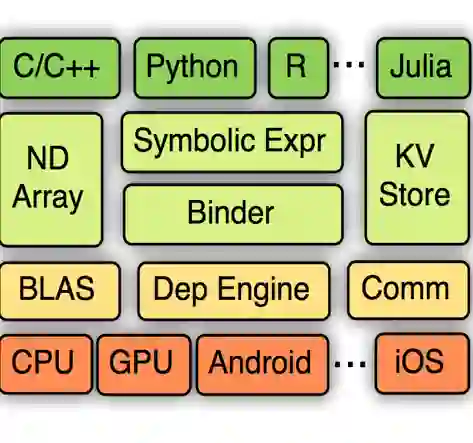
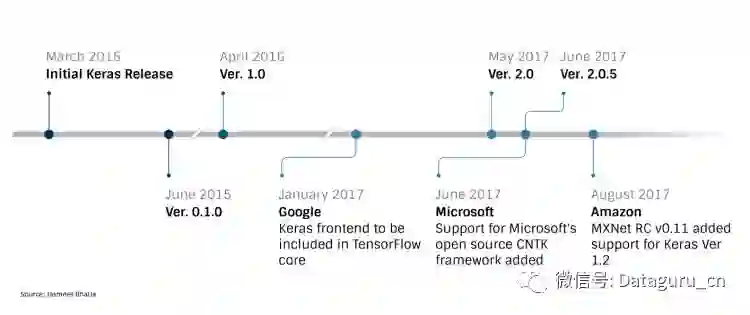
如果我们对 Keras 在数据科学和深度学习方面的流行还有疑问,那么考虑一下所有的主流云平台和深度学习框架的支持情况就能发现它的强大之处。目前,Keras 官方版已经支持谷歌的 TensorFlow、微软的 CNTK、蒙特利尔大学的 Theano,此外,AWS 去年就宣布 Keras 将支持 Apache MXNet,上个月发布的 MXNet 0.11 就新增 Core ML 和 Keras v1.2 的支持。不过到目前为止 MXNet 好像只支持 Keras v1.2.2 而不是版 2.0.5。
尽管我们可以使用任何 Keras 所支持的后端部署模型,但开发者和方案架构师应该了解 Keras 作为各深度学习库的高级 API,其本质上是不支持各个库所提供的全部基本参数微调。因此如果我们想要精细调整后端框架所提供的所有参数,那么我们较好直接使用深度学习框架而不是使用 Keras。当然这个情况会随着各种工具添加到 Keras 和深度学习框架中而得到改善,但现在 Keras 仍是一个十分优秀的工具,它能极好地适应于深度学习开发的早期阶段,并且为数据科学家和算法工程师快速构建与测试复杂的深度学习模型提供了强大的工具。
机器之心也尝试使用 TensorFlow 作为后端测试了 Keras,我们发现整个模型的搭建非常简洁,连入门者都能轻松读懂整个网络的架构。相比于直接使用 TensorFlow 搭建卷积神经网络,将 Keras 作为高级 API,并使用 TensorFlow 作为后端要简单地多。后面我们将会把 Keras 实现 CNN 的代码与注释上传至机器之心 GitHub 项目中,下图是我们使用 TensorFlow 作为后端初始化训练的情况:
以下是整个卷积网络的架构:

上面的代码清晰地定义了整个网络叠加所使用的层级。Sequential 代表序贯模型,即多个网络层的线性堆叠。在建立序贯模型后,我们可以从输入层开始依次添加不同的层级以实现整个网络的构建。上面的架构首先使用的是 2 维卷积层 Conv2D,卷积核大小为 3*3,激活函数为 ReLU,其中第一个参数 32 代表卷积核数目。此外,该卷积网络还使用了较大池化层 MaxPooling2D,pool_size=(2,2) 为两个方向(竖直,水平)上的下采样因子;Dropout 层,以 0.25 的概率在每次更新参数时随机断开输入的神经元;Dense 层,即全连接层;还有 Flatten 层,即将输入「压平」,也就是把多维的输入一维化,常用在从卷积层到全连接层的过渡。以上是该架构的基本层级,更详细的代码及注释请查看机器之心 GitHub 项目。
下面是 Jasmeet Bhatia 测评的具体情况。
Keras 后端框架性能测试
Keras 还能使开发人员快速测试使用不同深度学习框架作为 Keras 后端的相对性能。Keras 配置文件中有一个参数决定了使用哪一个深度学习框架作为后端,因此我们可以构建一个相同的模型在不同的深度学习框架(如 TensorFlow、CNTK、Theano)上直接运行。而对于 MXNet 来说,由于目前只支持 Keras ver1.2.2,所以我们需要对代码做一点点修改就行。当然这个模型可以根据各个深度学习框架中的不同库而进行微调以实现更好的性能,不过 Keras 仍然提供了很好的机会来比较这些基本库之间的性能。
早先已经有一些文章比较了 Keras 所支持后端框架的相对性能,但是对比的时间都比较早,且主要是以 TensorFlow 和 Theano 作为后端的对比。因此本文根据 Keras 和深度学习框架的版本在更大的范围内做了一次对比。
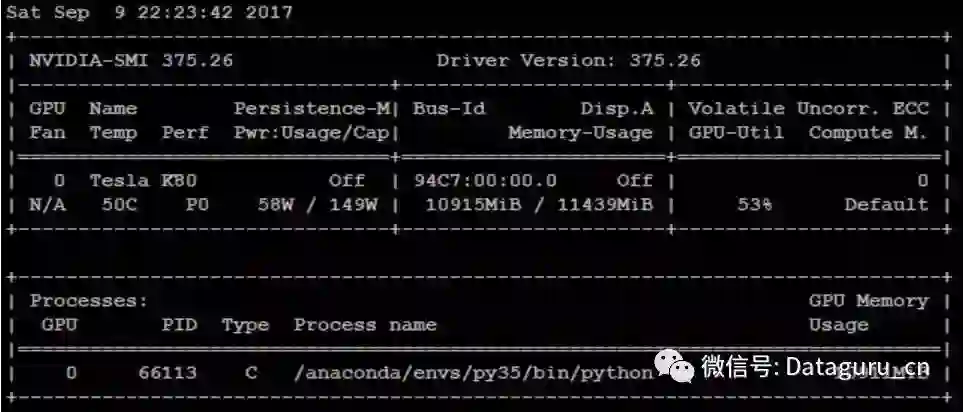
我们首先了解一下用于测试的配置。所有的性能测试都在 Azure NC6 VM 上使用 Nvidia Tesla K80 GPU 执行,使用的 VM 镜像是 Ubuntu 上的 Azure DSVM(数据科学虚拟机)。除了其他数据科学工具,我们还预安装了 Keras、TensorFlow、Theano 和 MXNet。对于测试来说,所有的软件包都是用的版,但因为 MXNet 只支持 Keras 1.2.2,所以其使用的旧版。
配置
因为每一个深度学习框架的依赖项不同,我们的测试在下面三种配置中运行:

性能测试
为了比较 DL 框架不同的性能,我们如下所述使用了 5 种不同的测试模型。为了确保没有特定的框架得到任何特定的处理,所有模型都来自 GitHub Keras/examples 仓库中所维护的。
模型源代码地址:https://github.com/fchollet/keras/tree/master/examples
测试的代码可以在作者的 GitHub 项目中找到:https://github.com/jasmeetsb/deep-learning-keras-projects
注意:有两个测试 MXNet 并没有参与,因为 MXNet 并不支持版的 Keras,且 MXNet 作为后端运行该模型需要调整大量代码。在其他三个测试中以 MXNet 作为后端也需要进行一些细微的调整,主要是新版本的 Keras 重命名了一些函数。
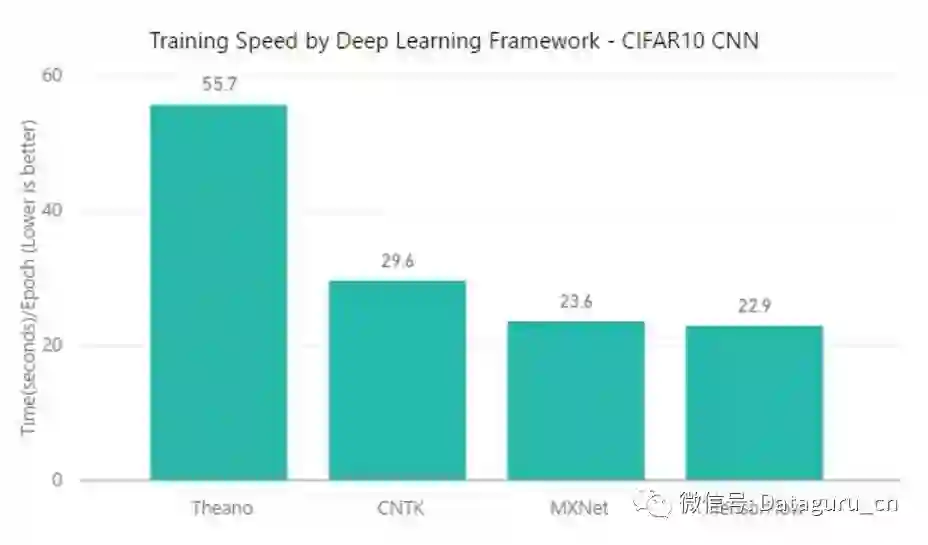
测试一:CIFAR-10 & CNN
学习模型的类型:卷积神经网络(CNN)
数据集/任务:CIFAR-10 小图片数据集
目标:将图片分类为 10 个类别
根据每一个 epoch 的训练速度,TensorFlow 要比 MXNet 快那么一点点。
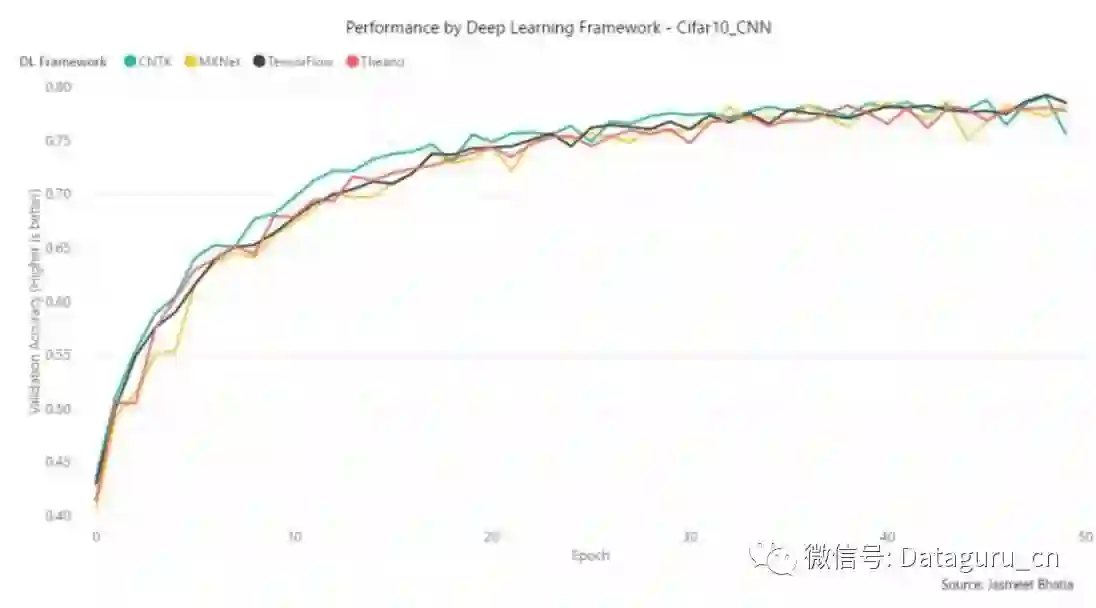
而按照准确度/收敛速度来说,CNTK 在前 25 个 epoch 中领先一点,而在 50 个 epoch 后,其他框架都到达相近的准确度,而 CNTK 却略微下降。
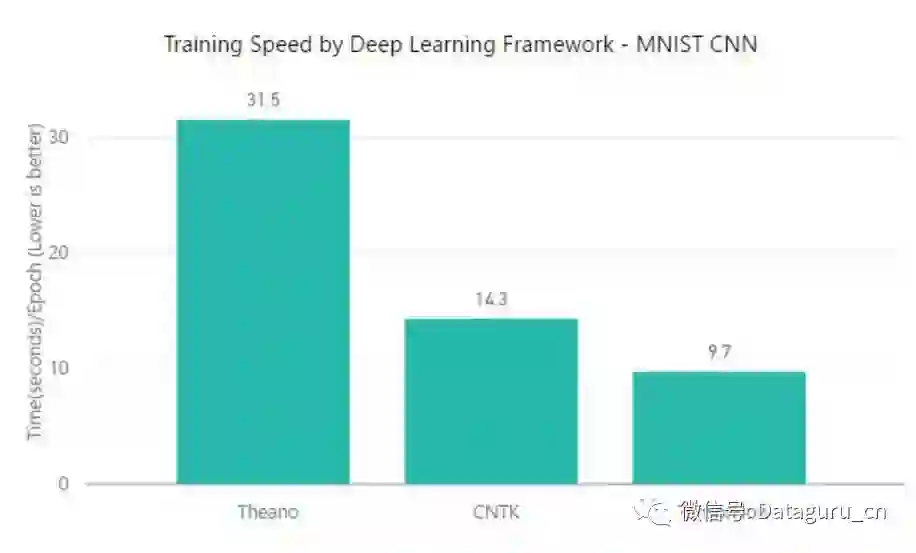
测试二:MNIST & CNN
学习模型的类型:CNN
数据集/任务:MNIST 手写数字数据集
目标:将图片分类为 10 类手写数字
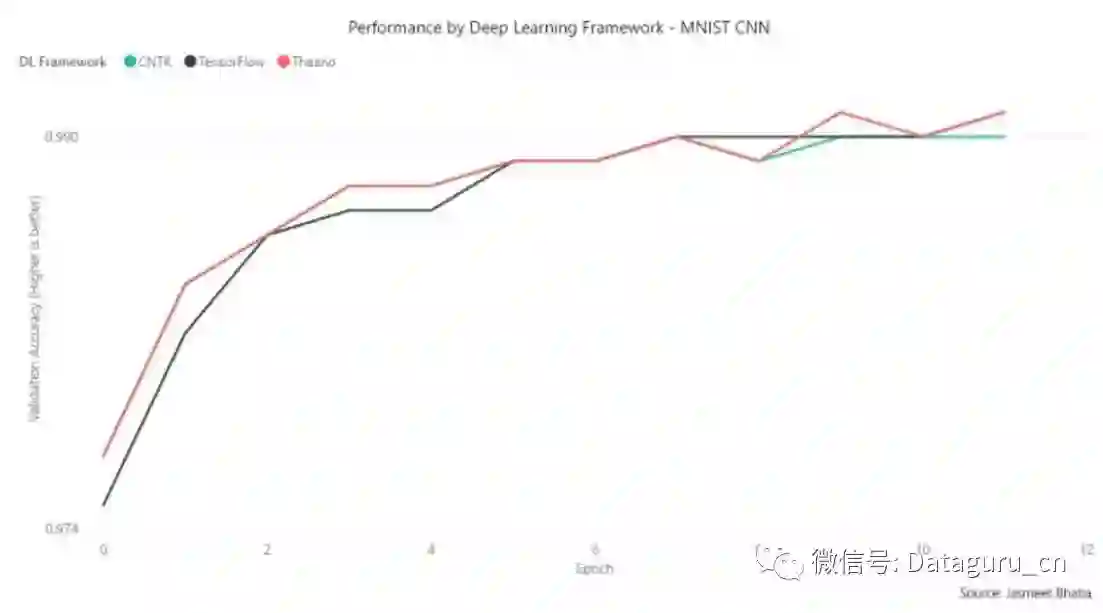
在该测试中,TensorFlow 明显要在训练时间上更加优秀,但在准确度/收敛速度上所有框架都有相似的特征。
测试三:MNIST&MLP
学习模型的类型:多层感知机/深度神经网络
数据集/任务:MNIST 手写数字数据集
目标:将图片分类为 10 类手写数字
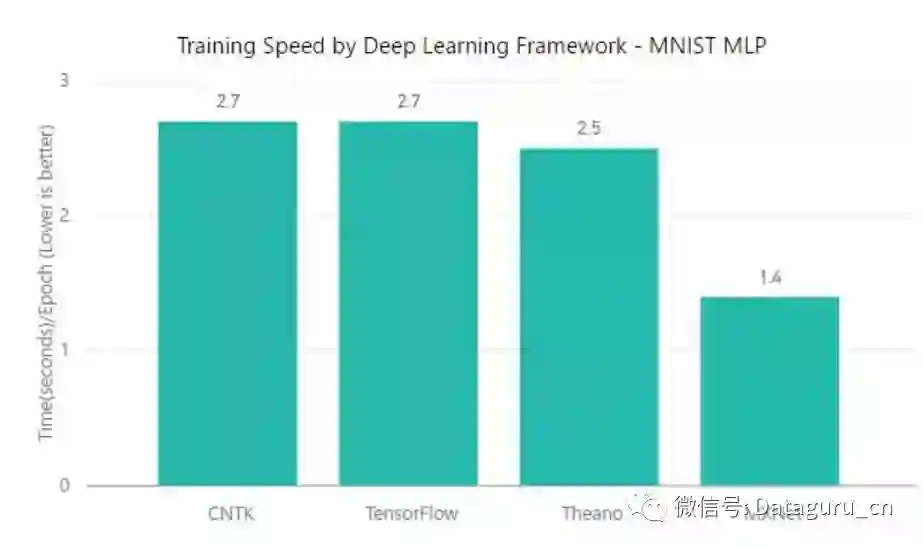
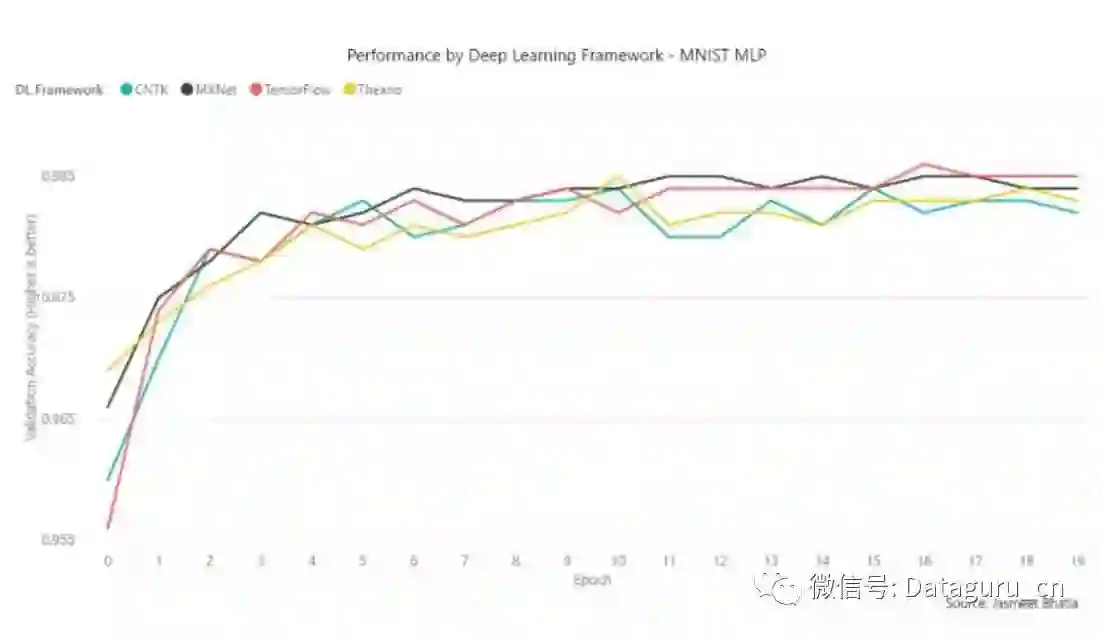
在使用 MNIST 数据集执行标准的神经网络测试中,CNTK、TensorFlow 和 Theano 实现了相似的分数(2.5 – 2.7 s/epoch),而 MXNet 却只需要 1.4s/epoch。此外,MXNet 同样在准确度/收敛速度上有一点点优势。
测试四:MNIST&RNN
学习模型的类型:层级循环神经网络(HRNN)
数据集/任务:MNIST 手写数字数据集
目标:将图片分类为 10 类手写数字
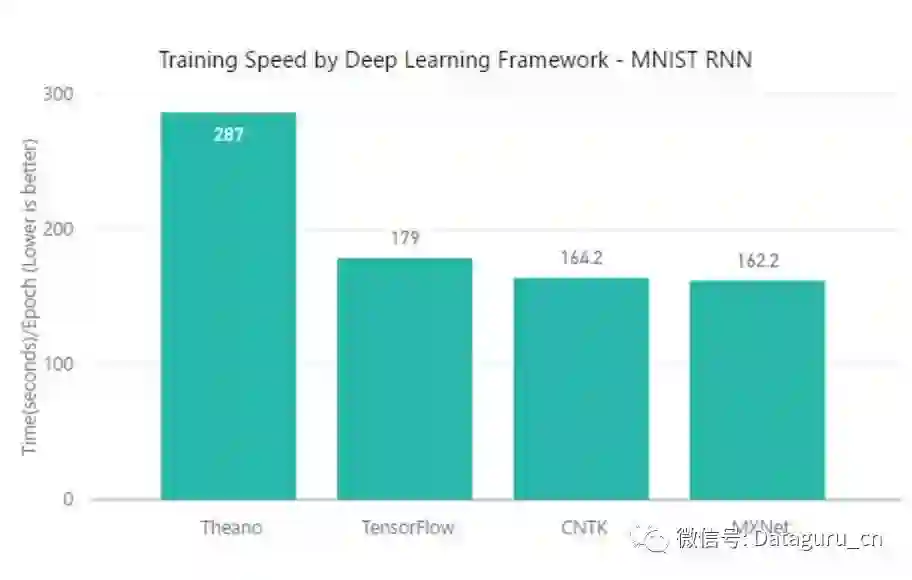
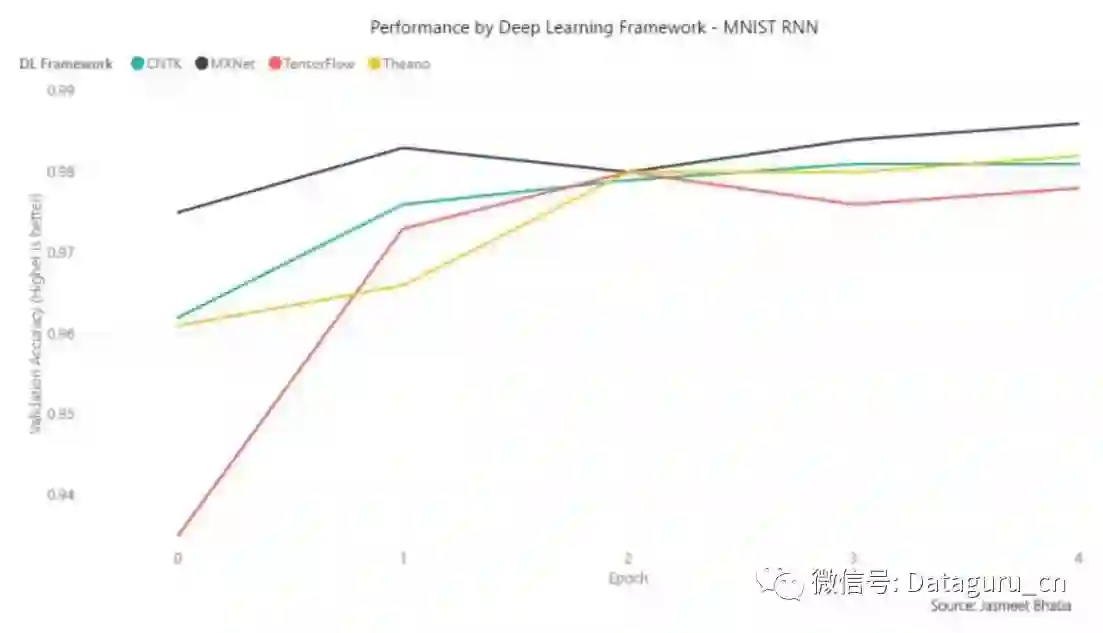
在训练时间上,CNTK 和 MXNet 有相似的性能(162 – 164 s/epoch),TensorFlow 的时间为 179s/epoch,而 Theano 所需的时间则显著地增多。
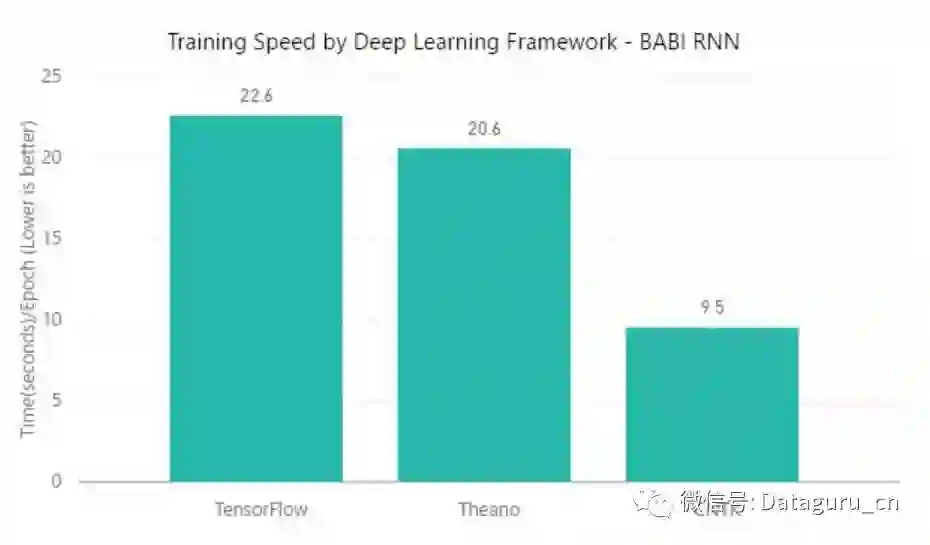
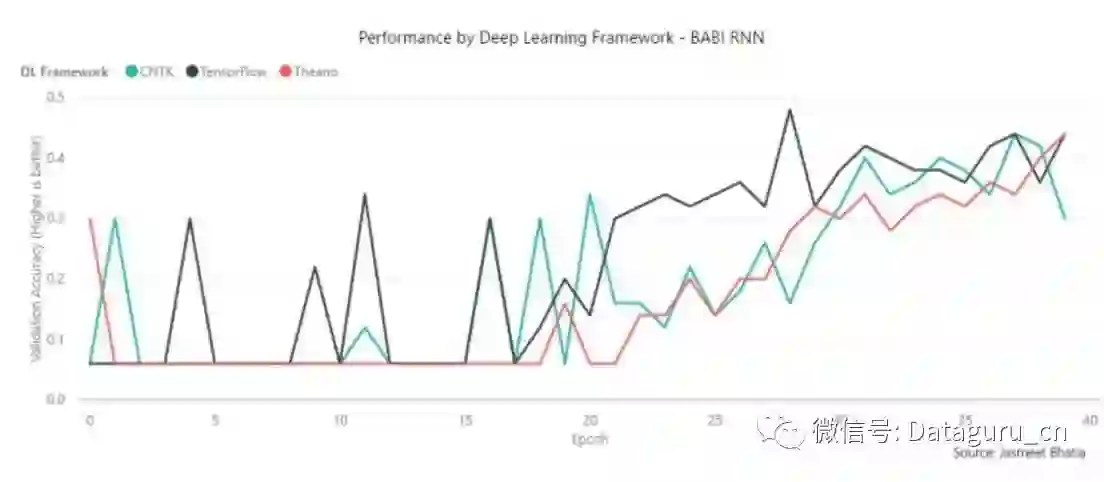
测试五:BABI & RNN
学习模型的类型:循环神经网络(RNN)
数据集/任务:bAbi Project (https://research.fb.com/downloads/babi/)
目标:分别根据故事(story)和问题训练两个循环神经网络,致使合并的向量可以回答一系列 bAbi 任务。
该测试并没有使用 MXNet,TensorFlow 和 Theano 在每一个 epoch 上要比 CNTK 要快了一倍多。
结语
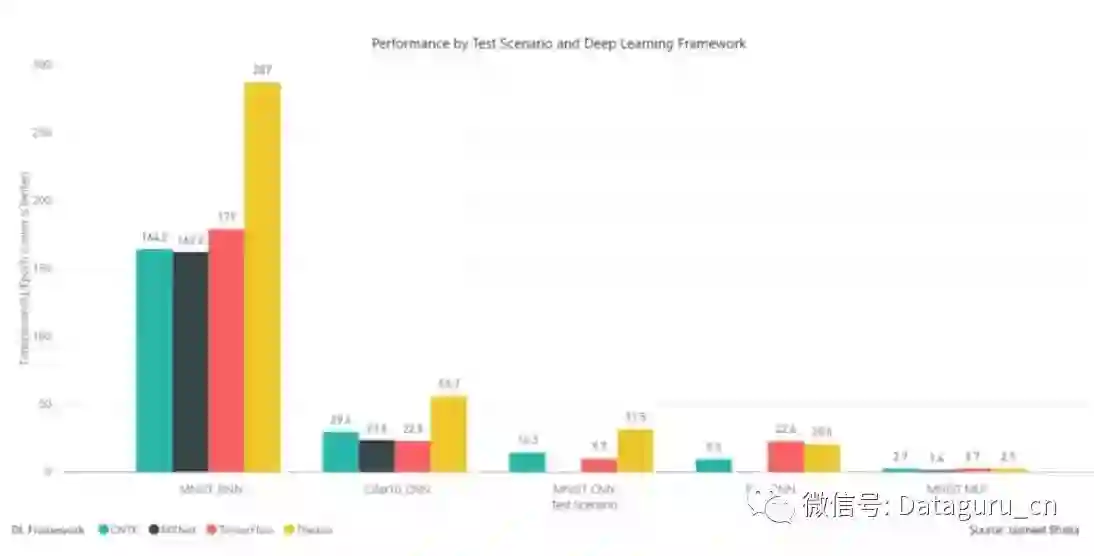
TensorFlow 在 CNN 测试中表现都是较好的,但是在 RNN 测试中表现并不太好。
CNTK 在 Babi RNN 和 MNIST RNN 测试上要比 TensorFlow 和 Theano 好得多,但是在 CNN 测试上要比 TensorFlow 差一些。
MXNet 在 RNN 测试上要比 CNTK 和 TensorFlow 要好一点,此外它在 MLP 上要比所有框架的性能都要好。不过 MXNet 并不支持 Keras v2 函数,所以我们并不能在没有修正代码的情况下直接测试,因此可能会有一点偏差。
Theano 在深度神经网络(MLP)中要比 TensorFlow 和 CNTK 好一点。
从上面的结果可以看出来,所有的深度学习框架都有其擅长的领域,并没有哪个框架一定要比其他框架好。CNTK 可作为 Keras 后端并用于 RNN 的使用案例,TensorFlow 可用于 CNN,而 MXNet 虽然显示了性能上非常大的潜力,但仍然还是让人期待其支持所有 Keras 函数的时候。在开源社区中,这些框架都在不断扩展与增强,从而提供更好的性能并轻松地部署到产品中。在考虑使用这些深度学习框架投入生产时,性能是首要的。在大多数情况下,我们还需要考虑部署的难易度和其他辅助工具,它们都将帮助我们管理产品化的机器学习模型。最后,所有的框架性能都是在作为 Keras 后端时测评的,所以会有一点误差,不过本文至少可以帮助大家对这些框架的性能有一定了解。此外本文在大家采用不同后端时可以给出一点相对客观的建议。
原文链接:http://www.datasciencecentral.com/profiles/blogs/search-for-the-fastest-deep-learning-framework-supported-by-keras
文章来源:机器之心

《机器读心术之文本挖掘与自然语言处理》在全国的独有性,以及将艰难知识通俗化讲授的能力,学完将熟悉文本挖掘与自然语言处理技术,懂得怎样运用到自己的实际工作,将数据挖掘能力从有限的结构化数据延伸到非结构化的海量文字材料。点击下方二维码报名课程