作为初创公司的第一位数据工程师,我学到了什么

公司在招人的时候不仅要找到合适的人,还要让他们相信加入公司是正确的选择。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
当我收到 EmCasa 公司的面试邀约的时候,我是另外一家公司的数据科学家。他们想找一位可以帮助他们组织数据的人。我问他们现在已经有哪些数据了,他们真诚地回答我:“我们只有 PostgreSQL 数据库里的几张表,还尝试使用了一些 BI 工具,仅此而已”。听了他们的话,我也很诚实地告诉他们:我没有亮眼的学位,之前也没做过数据工程师,不懂 Spark,不会 Airflow,不是 ETL 方面的专家,也不懂测试和 Git 之类的东西,我也不是一名开发人员。但我见过很多东西,有一些很好,有一些还不错但仍有提升的空间,还有一些完全不行。我的想法是要尽量避免去尝试已知不可行的东西。
我不知道他们是怎么想的,总之最后我成了他们公司的第一位数据工程师。
在加入这家公司后,一切都像他们之前所说的那样。我有足够的施展空间,可以按照我认为的最好的方式去做每一件事情。第一周,我们就制定了一些季度 OKR:
从 Facebook Ad、Google Ad、SalesForce 和其他第三方服务获取数据;
实现一个 BI 平台;
将物业估价算法准确度提高 20%;
将评估模型设计成独立的 API;
更新和改进 Web 爬虫。
为了从第三方服务提取数据,我们开始调研 ETL 解决方案,比如 StitchData、Fivetran、Segment、Alooma、Rivery,等等。要为每个第三方服务 API 构建自定义集成方案需要花费很多时间,但我们速度要快,而使用 ETL 服务解决方案可以为我们节省几个月的开发和维护时间。我们决定使用 Rivery,并在两周内搭建了一个 Redshift 集群,用来每天更新来自第三方服务的数据。这个时候,Luca 加入了我们,成了我们的 BI 分析师。他现在有很多数据可以玩了。我们还使用 Metabase 作为仪表盘。到目前为止,一切都很顺利。我们终于有了真正的数据,而不只是 PostgreSQL 里的几个表了!
下一步是改进物业估价模型,并将其作为一个独立的 API(之前的模型是与后端绑定在一起的)。但我们没有足够的数据来创建新模型(虽然确实有了一些数据,但还不够)。于是,我把目光投向了我们的 Web 爬虫工具。它是用 Elixir(我们的后端就是用 Elixir 开发的)开发的,但我不懂 Elixir,于是我决定用 Python 从头开始开发另一个爬虫。我创建了一个叫作 Spatula 的 Python 包,它可以从其他网站爬取数据清单,并将它们保存到 S3。这个时候,我们的数据科学家 Priscila 也加入进来,她负责处理旧数据。我在本地运行 Spatula,她就可以使用 Athena 查询数据,然后开始建模。
接下来,我开始研究 Airflow,不过我遇到了一些麻烦。一个是学习如何编写 DAG,一个是学习如何将 Airflow 可靠地部署到 AWS 上。我花了很多时间学习 Airflow、Terraform、Docker 和 AWS ECS,才顺利地在 AWS 上进行了第一次部署(https://github.com/nicor88/aws-ecs-airflow),然后又花了更多的时间按照我们的需求进行了定制。我担心这项任务会占用太多时间,所以我问经理是否可以把时间往后推一点,并换一种方式来安排任务(我知道这种方式从长远来看是行不通的)。经理的回答是:“我们在面试你的时候就知道你的情况,有些东西你也不懂,但你可以花时间去学,找到正确的方式来完成这些任务”。这种管理姿态和”做正确的事情“的承诺是我在其他公司从未见过的。随后,我们花了更多的力气部署好了 Airflow,让 Spatula 爬虫每周爬取一次数据。
收集用户信息,用来预测房产销售价格。我们会询问物业的详细信息,如有多少个房间、套房、浴室和车库。
这个时候,Priscila 的新估值模型也准备就绪,但还没有准备好用于生产环境。我开始和她结对编程,并告诉她我修改了哪些东西,以及为什么和怎么改的。然后我们一起部署了 Priceteller,这是我们的第一个机器学习模型。它是运行在 AWS Lambda 上的 Flask API 和 API 网关。在部署之前,我们还与开发团队讨论了很多与代码质量、测试和文档相关的问题。他们不想在生产环境中向不可靠的 API 发送请求——他们提出这样的高标准绝对是有道理的。当我们达到他们的标准,我们的第一个机器学习模型就可以上线了。最近,我们还部署了第二个实时模型 Selekta,它可以根据用户的偏好来推荐清单。
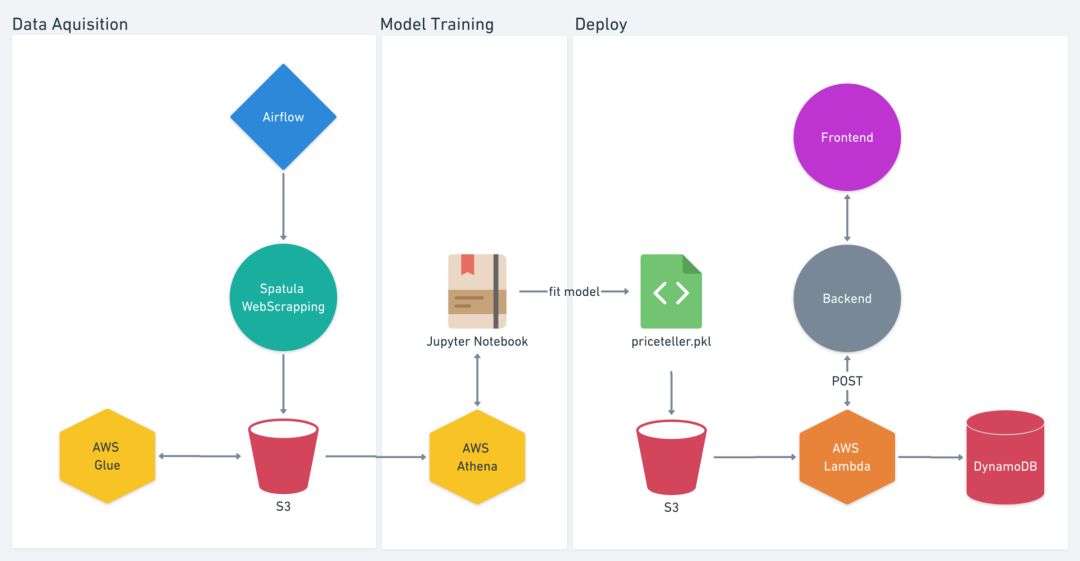
我们的第一个机器学习模型,从数据抓取到部署
Priscila 告诉我她以前的公司是如何使用 Airflow 的。因为我之前都没有用过 Airflow,所以试着通过反复试错来学习。她提出了一个改进清单,我全盘接受了。从那时起,我们开始在 AWS Glue 上运行 Spark 作业,并用一个 Airflow 任务来触发和监控它们。我们的作业每隔一个小时从后端获取数据。我们还有其他一些负责保存用户日志事件的任务。我们还创建了一个推荐模型,每天以批次的方式运行。不知不觉地,我们现在在 S3 上有了一个数据量超过 2TB 的数据湖。
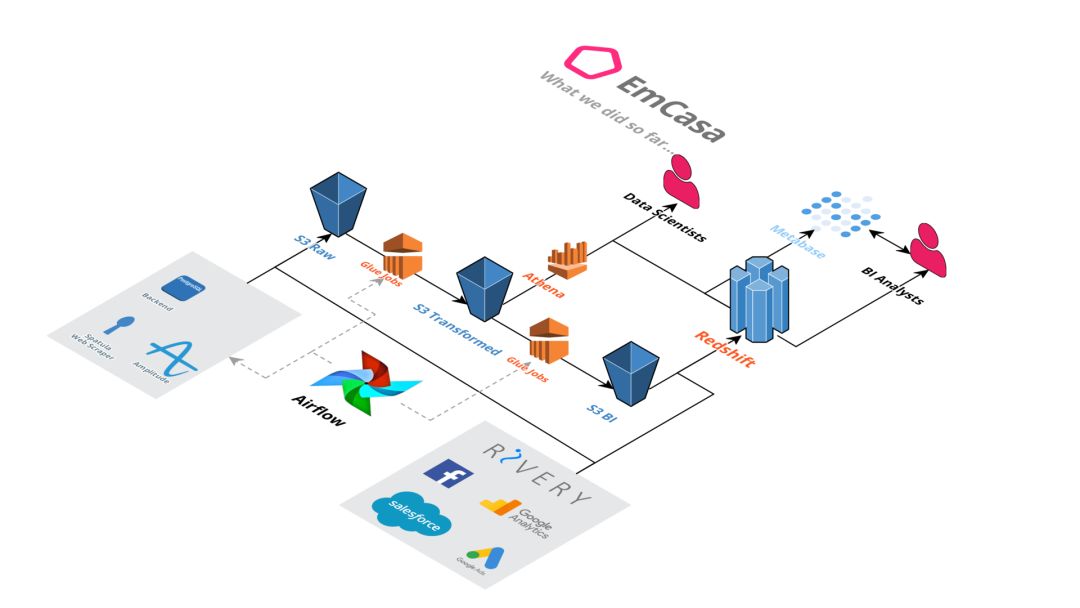
我们目前的数据基础设施
这些事情就发生在六个月内,我们用健壮的工具和技术为公司打好了数据基础。
对于有数据科学背景的人来说,数据工程并不复杂。作为数据科学家,我们感觉到没有可用的数据或工具来完成这项工作是多么的痛苦。但我们可以学习,Airflow、AWS、Spark、Git、Python,凡是你能想到的东西。只要你知道目标是什么,就能在短时间内学会它们。漫无目的的学习很难有成效。
知道要做什么和动手去做是两码事。这与公司的文化有关。在面试的时候我就知道,我加入了一个可以让我拥有自主权的公司,可以用我认为正确的方式去解决问题。你可以在面试中问他们数据对公司来说有多重要。只是用于提供支持吗?还是公司发展战略的一部分?他们对你是真诚的吗?如果数据并不是公司发展战略的一部分,那么你很可能没办法花很多时间去计划和做正确的事情。
将 API、模型和仪表盘作为独立的产品,这为数据团队提供了极大的灵活性。但它们必须符合某些标准,这样才能将它们打通。将数据作为一种产品,并形成文化,保护团队免受日常业务问题的困扰——可以让分析师们去回答这些问题。我们的经理可以让我们免受外界的干扰,让我们能够集中精力学习,把事情做好。
有时候你需要独自完成一些工作,但有时候向那些有经验的人寻求帮助会为你节省很多时间。如果团队里有经验丰富的人,可以问问他们之前在其他公司是怎么做的。即使他们不知道该怎么做,至少也会知道什么行得通,什么行不通。寻求帮助肯定会把你引向正确的方向。
有些事情可以通过第三方工具轻松搞定,比如我在本文开头所说的 ETL 解决方案。如果你的数据仓库中没有来自 Facebook 的数据,那就没有必要浪费时间学习如何连接 Facebook Insights API;如果没有运行在 EMR 上的作业,就不需要学习如何在 EC2 上搭建 Spark 集群;如果没有 Glue Job,就不需要使用 EMR;如果没有 Athena 查询,就不需要 Glue Job。
先从尝试使用最简单的解决方案(不需要花很多时间维护的解决方案)开始。当简单的解决方案不能满足需求时,再开始学习其他工具。如果从一开始就使用复杂的解决方案可能会浪费你的时间。要专注于用最简单的解决方案尽可能快地提供业务价值。
花大半天时间去修复一个有问题的东西,这是最糟糕不过的事情了。如果经常出问题,那么要么是你做事的方式错了,要么没有用对工具,或者两者兼而有之。从一开始就做对事情可能会花掉你更多的时间,但在未来会为你节省时间。
如果有什么东西是你不懂的,请说出来,但也要证明你可以以及愿意去学。这样你就可以用工作时间学习新东西。
向其他团队成员分享他们不知道的东西。这样有助于你专注学习,也有助于减少不同工种之前的工作摩擦。如果数据工程师、数据科学家和机器学习工程师之间有了默契,工作就会变得更加顺畅。结对编程是一个很好的实践,可以借机分享你的知识,并获得实时反馈。花点时间分享你的知识,看看你能为别人提供些什么。
在完成一个大项目后,比如部署了一个新的 ETL 管道,就可以花点时间做一些次要的任务,比如写文档或修复遗留 bug。欲速则不达,马不停蹄地开始另一项大项目可能会让你走得更慢。
原文链接:
https://towardsdatascience.com/what-i-learned-from-being-a-startups-first-data-engineer-f19cd71d3f31
不久前,2019年国际篮联篮球世界杯让这个夏天的尾巴再度燃了起来!男篮在球场上身姿飞腾,让观众不禁拿起手机,疯狂按下快门记录着肆意飞扬的热血现场。输赢不论,那些个定格在镜头中的努力身影,都是一幅幅真实的拼搏模样。而手机里,搭载了AI技术的不同照片处理功能,也为这份记忆增添了不同色彩。9月21日,百度AI快车道将再次来到深圳,这次打算和众多“图像技术”圈的小伙伴们共享福利!
本期实战营,课程将聚焦“语义分割”专题,由百度三位明星讲师,通过百度飞桨语义分割库PaddleSeg为大家带来技术详解和实战应用,并通过基于DeepLabv3+人像分割案例现场带大家感受技术硬实力。大家可以扫描下方二维码或者“阅读原文”查看详情。

今日荐文
点击下方图片即可阅读

在数据科学领域,Rust会是Python的最佳替代方案吗?

你也「在看」吗?👇




