最佳实践 | 教你用一条SQL搞定跨数据库查询难题
导读
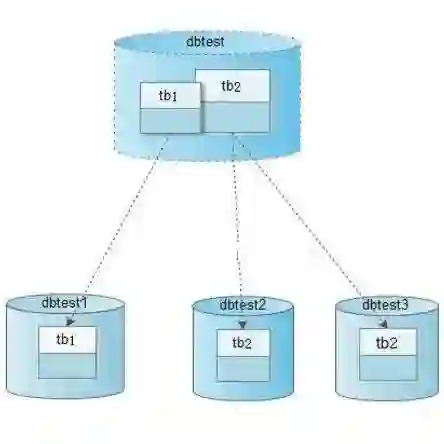
日前,某电商用户由于业务发展迅猛,访问量极速增长,导致数据库容量及性能遭遇瓶颈。为降低数据库大小,提升性能,用户决定对架构进行垂直拆分。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
该用户按照会员、商品、订单,将数据垂直拆分至三个数据库,分库后数据分布到不同的数据库实例,以达到降低数据量,增加实例数的扩容目的。
然而前途是美好的,道路是曲折的。一旦涉及拆分,就逃不开“原本在同一数据库里的查询,要变成跨两个数据库实例”的查询问题。
单库时,系统中很多列表和详情页所需数据可以简单通过SQL join关联表查询;而拆库后,拆分后的数据可能分布在不同的节点/实例上,不能跨库使用join,此时join带来的问题就很棘手了。
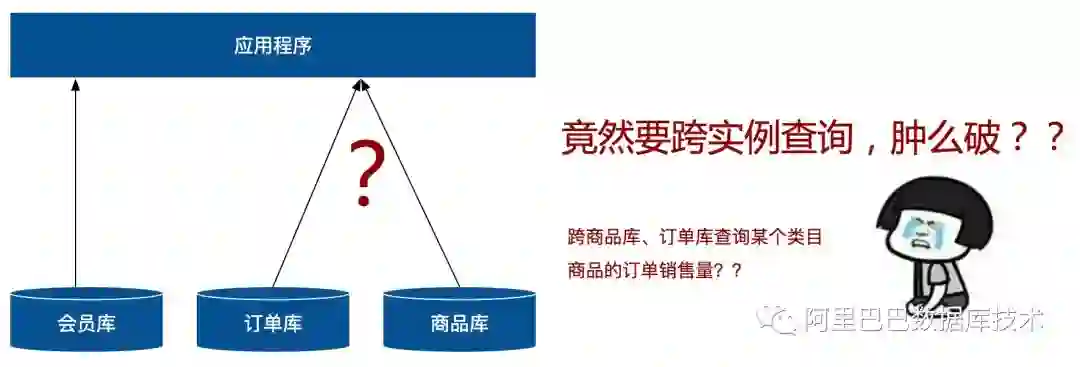
例如:业务中需要展示某个品类商品的售卖订单量,现在订单数据和商品数据分布在两个独立的数据库实例中,业务上要怎么进行关联查询?
用户首先想到的方法是,对现有业务代码进行重构,分别从两个数据库查询数据,然后在业务代码中进行join关联。那么问题来了,如果采用这个解决方案,业务上那么多查询改造起来,拆分难度极大,操作起来过于复杂。跨库join操作又没有非常高效的办法,需要各个分库迭代查询,查询效率也会有一定影响。
是不是光想想就一个头两个大?别担心,关于数据库拆分后的业务改造难题,其实用一条SQL就可轻松搞定。具体解法如下⬇️
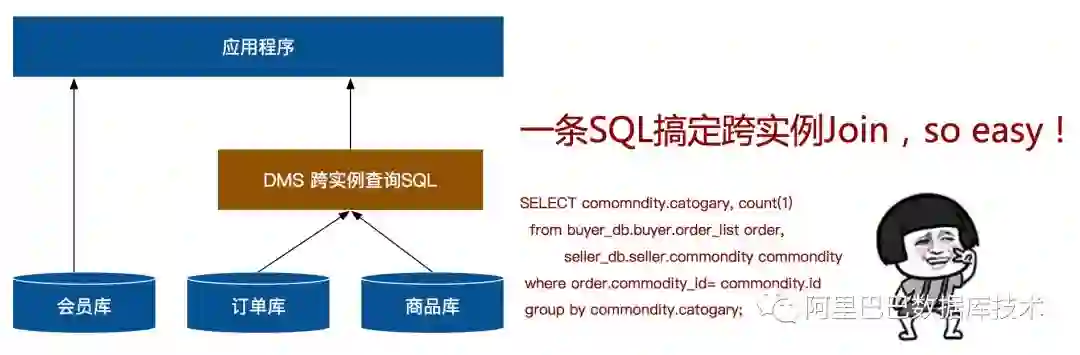
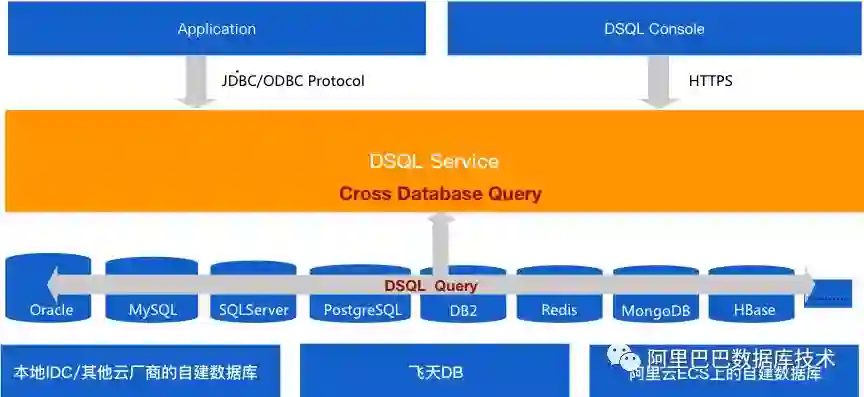
经沟通,我们发现用户遇到的其实就是典型的跨数据库实例查询问题。目前,阿里云DMS(数据管理)已经支持跨数据库实例SQL查询的能力,用户可以通过DMS,利用一条SQL即可解决上述难题。不仅能够满足“跨库Join”这一核心诉求,还能极大地简化用户的技术方案。
除了开篇介绍的客户案例,DMS跨数据库实例的查询功能可以解决我们业务中遇到的任意跨数据库查询的诉求。例如:跨线上库及历史库的join查询,快速获取全量数据;单元化架构下,join各个单元的数据库查询全局数据;游戏业务,可以join MySQL中的用户数据及MongoDB中的游戏装备数据等。
接下来,我们通过一个快速上手的实例,来看看用户如何写这条SQL。
商品库的信息
实例连接:198.12.13.1:3306 , 数据库名:seller
商品表名:commodity
包含部分字段的表结构:
createtable commondity(
id BIGINT(20), -- 商品ID
name varchar(100), -- 商品名称
create_time TIMESTAMP , -- 商品入库时间
catogary BIGINT(30), -- 商品类目
features text, -- 商品描述
param text); -- 商品属性
订单库的信息
实例连接:198.12.13.2:3306 , 数据库名:buyer
订单表表名:order_list
包含部分字段的表结构:
createtable order_list(
id BIGINT(20), -- 订单ID
buyer_id BIGINT(30), -- 买家ID
create_time TIMESTAMP , -- 订单生成时间
seller_idBIGINT(30), -- 卖家ID
commodity_id BIGINT(30), -- 商品ID
status int(8) – 订单状态)
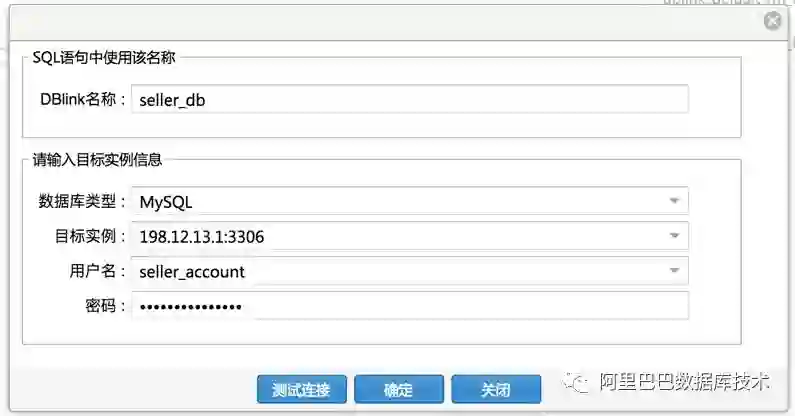
创建DBLink
在编写查询SQL之前,需要先在DMS中配置卖家库和买家库的DBLink。

编写并运行跨库查询SQL
当DBLink配置完成后,即可开始在DMS中编写并运行SQL,实现查询某个商品的订单列表的需求。
SELECT comomndity.catogary,
count(1)
from buyer_db.buyer.order_list
order,
seller_db.seller.commondity commondity
where order.commodity_id= commondity.id
GROUP BY commondity.catogary;
这条SQL的语法完全兼容MySQL,只是在From的表名前面带上DBLink。
所以,业务方只需要使用DMS跨数据库查询SQL便可轻松解决拆库之后的跨库查询难题,业务基本无需改造。
SELECT * FROM oracle.dsqltest.b oracle inner join
mysql.dsqltest.a mysql on oracle.id = mysql.id
WHERE oracle.id=1
DMS提供的跨数据库实例查询功能孵化于阿里巴巴集团,目前已服务超过5000名开发者,全面支撑阿里巴巴跨数据库实例的所有线上查询需求。
DMS支持跨同异构数据库的在线查询,支持MySQL、SQLServer、PostgreSQL及Redis等数据源,为应用提供了一种数据全局查询的能力。用户无需通过数据汇集,即可通过标准SQL实现跨实例的交叉查询。
1. 点击“阅读原文”⬇️,登录DMS控制台(注:需先登录阿里云账号)
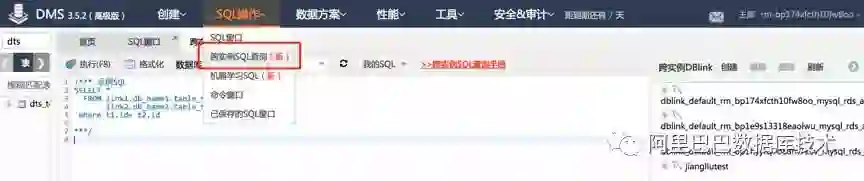
2. 从SQL操作中,进入➡️ “跨实例SQL窗口”
3. 扫描下方二维码或打开右侧URL,即可参考使用指南
(https://help.aliyun.com/document_detail/88530.html),创建DBlink,编写并运行SQL


点击阅读原文,马上体验