学界 | MnasNet论文解读:终端轻量化模型新思路
AI 科技评论按,本文作者陈泰红(ahong007@yeah.net),他为 AI 科技评论撰写了关于 MnasNet 论文的独家解读文章。
1. Motivation
CNN 模型近年发展非常迅猛,在多项视觉任务中都展现出极佳的性能。但 CNN 模型体积巨大,计算性能低,这是比较明显的缺点,计算需求的增加使得在诸如终端(手机/AR/VR/无人机)上部署最先进的 CNN 模型变得困难。
终端轻量化神经网络模型需要同时考虑三个维度:参数少、速度快和精度高。目前 Mobile V1&V2,shuffle Net V1 等 CNN 模型在移动端取得一定进展,但是使用间接评价标准,如 FLOPS 等,手工设计模型卷积架构难以在三个维度取得平衡。Google 团队最新提出 MnasNet,使用强化学习的思路,提出一种资源约束的终端 CNN 模型的自动神经结构搜索方法。论文将实时性显式地结合到主要目标中,这样搜索空间就可以识别出一个在准确性和实时性实现良好平衡的模型,即实时性和准确率作为 reward,并且直接使用手机平台(Pixel phones 等)运行模型,直接测量实时性和准确率。为了进一步在灵活性和搜索空间大小之间取得适当的平衡,论文还提出一种新的分解层次搜索空间,该空间允许整个网络的分层多样性。
MnasNet 模型在 Pixel phones 上直接运行,在 ImageNet 分类和 COCO 目标检测等计算机视觉领域均取得 state-of-art 水平。ImageNet 分类任务中,在 pixel 1 上取得了 74.0% 的 top-1 精度,耗时 76 毫秒,比 MobileNetV2 快 1.5 倍,比 NASNet 快 2.4 倍。在 COCO 目标检测任务中,比 MobileNets 取得了更好的 mAP 和实时性。
2. Related Work
CNN 模型压缩有一些常用的方式:量化、减枝和手工设计神经网络架构(卷积方式)。比较著名的量化模型有 Deepcompression,Binary-Net,Tenary-Net,Dorefa-Net、SqueezeNet,Mobile V1&V2,shuffle Net V1&V2。
SongHan 提出的 DeepCompression 可以说是神经网络压缩领域开山之作,主要分为三个主要的部分:剪枝,量化,哈夫曼编码。量化将大量的数学运算变成了位操作(Binary-Net),这样就节省了大量的空间和前向传播的时间,使神经网络的应用门槛变得更低。但是这些压缩算法在准确率上有很大的局限性。论文使用的多是选择传统 CNN 架构(AlexNet,VGG)作为测试对象,而这些网络本身冗余度较高。
而设计神经网络架构的方式是目前在终端常用的方式,比如 MobileNet V2 等已经在小米手机的 AI 相机和指纹识别、人脸识别等应用场景落地。
SqueezeNet 为了降低模型参数,替换 3x3 的卷积 kernel 为 1x1 的卷积 kernel,减少输入 3x3 卷积的 input feature map 数量,减少 pooling 。
MobileNet V1 的主要工作是用 depthwise sparable convolutions 替代过去的 standard convolutions 来解决卷积网络的计算效率和参数量的问题。MobileNet V2 主要的改进有两点:
1、Linear Bottlenecks。也就是去掉了小维度输出层后面的非线性激活层,目的是为了保证模型的表达能力。
2、Inverted Residual block。该结构和传统 residual block 中维度先缩减再扩增正好相反,因此 shotcut 也就变成了连接的是维度缩减后的 feature map。
Shuffle Net 引入 pointwise group convolution 和 channel shuffle 解决效率问题,比如小米 MIX2,它自带的 0.5 秒人脸识别自动解锁使用的就是 Shuffle Net。Shuffle Net V2 是最新发表在 ECCV2018 的论文,提出了四点准则,并对网络进行了四点改进:(1)使用相同的通道宽度的卷积;(2)考虑使用组卷积;(3)降低碎片化程度;(4)减少元素级运算。
在终端设备手工设计神经网络难以在准确率和实时性间取得平衡,更为复杂的是,每种设备类型都有自己的软件和硬件特性,并且可能需要不同的体系结构才能达到最佳的精度-效率权衡。目前芯片设计公司如高通、小米、华为、苹果都有针对自家芯片做的底层优化,以提高 CNN 的实时性。
3. Architecture
3.1 搜索算法
本文提出了一种用于设计移动 CNN 模型的自动神经结构搜索方法。图 1 显示论文总体视图,与以前方法的主要区别是多目标奖励和新的搜索空间。论文考虑两个因素:首先,将设计问题描述为一个考虑 CNN 模型精度和推理实时性的多目标优化问题。使用架构搜索和强化学习以找到模型,在准确率和实时性取得平衡。其次,之前很多自动化搜索方法主要是搜索几种类型的单元,然后通过 CNN 网络重复叠加相同的单元,而未能考虑卷积操作造成的运算效率差异。
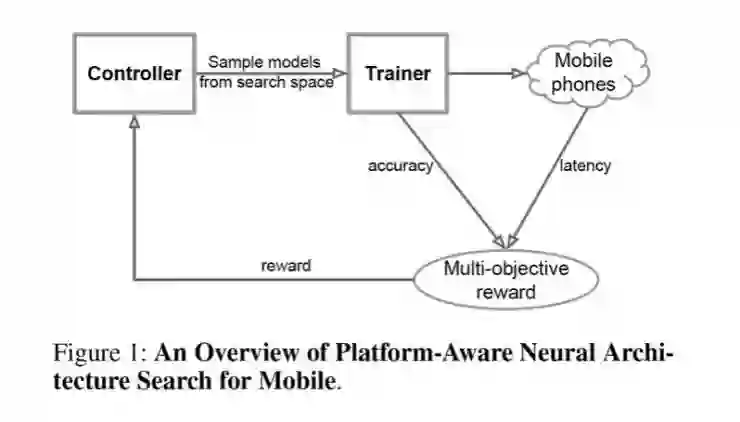
帕雷托最优(called Pareto optimal)是经济学的一个概念,是指资源分配的一种理想状态。给定固有的一群人和可分配的资源,如果从一种分配状态到另一种状态的变化中,在没有使任何人境况变坏的前提下,使得至少一个人变得更好,这就是帕雷托改善。帕雷托最优的状态就是不可能再有更多的帕雷托改善的状态。
m 表示模型,ACC(m) 表示目标模型的准确率,LAT(m) 表示耗时,T 表示目标耗时。而论文提出一种策略,基于梯度的强化学习方法寻找帕雷托最优,同时对 ACC(m) 和 LAT(m) 帕雷托改善。

如图 1 所示,模型包括三个部分:基于 RNN 的控制器,用于实现模型准确率的训练器,基于推断引擎测量耗时。论文采用评估-更新循环训练控制器,直到模型收敛。
3.2 层级搜索空间
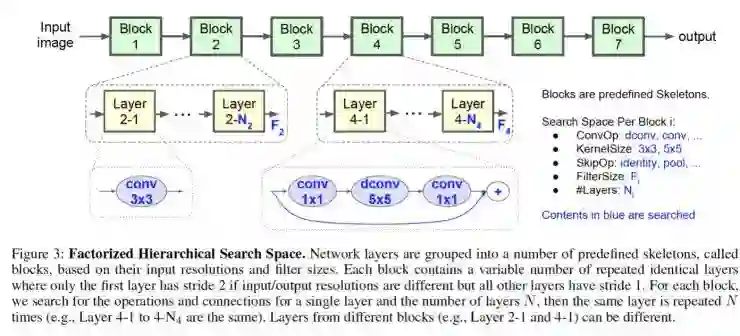
论文使用层级搜索空间,即划分 CNN layers 成多个 groups,对每个 group 搜索卷积和连接,相比其他算法只搜索几个复杂的单元,然后重复叠加相同的单元,论文简化了每个单元格的搜索空间,但允许各个单元不同。
如图 3 所示,论文划分 CNN 模型为一系列预定义的 Block 序列,逐渐降低输入分辨率和增加滤波器尺寸。每一个 Block 内含有一系列 identical layers,其卷积操作和连接由每一个 Block 搜索空间确定。对第 i 个 Block,由以下参数决定:
卷积类型(Convolutional ops ConvOp): regular conv (conv), depthwise conv (dconv), and mobile inverted bottleneck conv with various expansion ratios
卷积内核 Convolutional kernel size KernelSize: 3x3, 5x5.
跳跃层连接方式 Skip operations SkipOp: max or average pooling, identity residual skip, or no skip path.
输出滤波器尺寸 Output filter size Fi
每个 block 卷积层个数 Number of layers per block Ni.
ConvOp, KernelSize, SkipOp, Fi 决定每一卷积层架构,而 Ni 决定每一个 block 重复卷积层的次数。
4. Experiment
论文直接在 ImageNet 训练集搜索最优解,之后进行少量的训练,从训练集选择 50K 图像作为验证集。控制器在搜索架构中采样约 8k 个模型,但只有很少的模型(<15)转移到 ImageNet 和 COCO。
在 ImageNet 的训练过程:模型试验 RMSProp 优化,decay=0.9,momentum =0.9。每一层卷积后均有 Batch norm,momentum 0.9997,weight decay = to 0.00001,模型的训练过程可参考 MnasNet 论文。
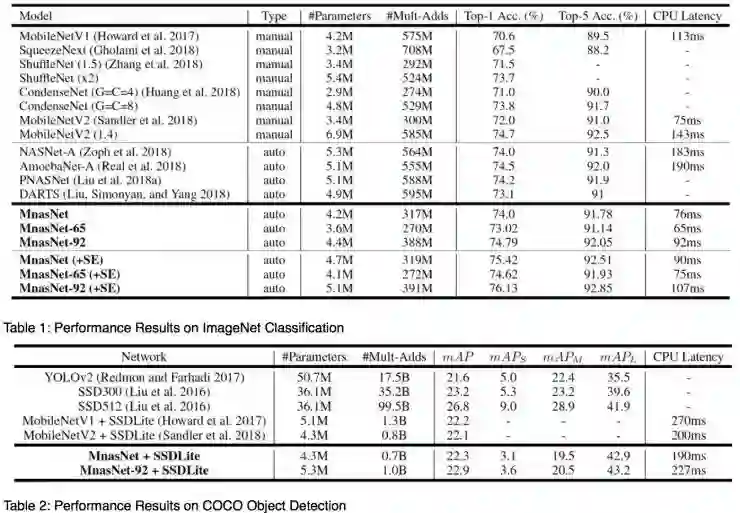
从论文的实验效果看到,MnasNet 模型在 MnasNet 分类任务和 COCO 目标检测任务中均优于自家公司之前提出的 MobileNet V1&V2,群雄逐鹿、百舸争流、青出于蓝。好的团队有实际业务需求,有服务器集群支持,有内涵底蕴精心打磨。
5. Discussion
论文的图 7 显示了 MnasNet 算法的神经网络架构,包含一系列线性连接 blocks,每个 block 虽然包含不同类别的卷积层,每一卷积层都包含 depthwise convolution 卷积操作,最大化模型的计算效率。但是和 MobileNet V1&V2 等算法有明显不同:
1、模型使用更多 5x5 depthwise convolutions。对于 depthwise separable convolution, 一个 5x5 卷积核比两个 3x3 卷积核更高效:
假如输入分辨率为(H,W,M),输出分辨率为(H,W,N),C5x5 和 C3x3 分别代表 5x5 卷积核和 3x3 卷积核计算量,通过计算可以看到,N>7 时,C5x5 计算效率大于 C3x3 计算效率:
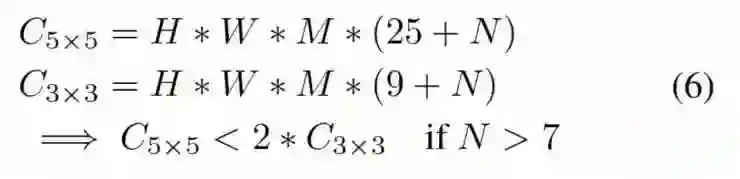
2、层分级的重要性。很多轻量化模型重复 block 架构,只改变滤波器尺寸和空间维度。论文提出的层级搜索空间允许模型的各个 block 包括不同的卷积层。轮的ablation study比较了 MnasNet 的各种变体(即单独重复使用各个 block),在准确率和实时性方面难以达到平衡,验证了层分级的重要性。
个人观点:论文使用强化学习的思路,首先确定了 block 的连接方式,在每个 block 使用层级搜索空间,确定每个卷积层的卷积类型,卷积核、跳跃层连接方式,滤波器的尺寸等。如果让强化学习自己选择模型的架构,比如 Encoder-Decoder,U-Net,FPN 等,是否在目标检测语义分割方面有更好的表现。
以上仅为个人阅读 MnasNet 论文后的理解,总结和一些思考,观点难免偏差,望读者以怀疑的态度阅读,欢迎交流指正。
参考文献:
1. MnasNet: Platform-Aware Neural Architecture Search for Mobile.
https://arxiv.org/pdf/1807.11626.pdf
2. Mobilenets:Efficient convolutional neural networks for mobile vision applications.
https://arxiv.org/pdf/1704.04861.pdf
3. Mobilenetv2: Inverted residuals and linear bottlenecks. CVPR2018 .
4. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices .
https://arxiv.org/pdf/1707.01083.pdf
5. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design.ECCV2018


