超30亿中文数据首发!首个专为中文NLP打造的GLUE基准发布

AI WORLD 2019 世界人工智能峰会精彩重放!
10 月 18 日,2019 中关村论坛平行论坛 ——AI WORLD 2019 世界人工智能峰会在北京启幕。新智元杨静、科大讯飞胡郁、微软王永东、华为王成录、英特尔宋继强、旷视及智源学者孙剑、滴滴叶杰平、AWS 张峥、依图颜水成、地平线黄畅、autowise.ai 黄超等重磅嘉宾中关村论剑,重启充满创新活力的 AI 未来。峰会现场,新智元揭晓 AI Era 创新大奖,并重磅发布 AI 开放创新平台和献礼新书《智周万物:人工智能改变中国》。回放链接:
新智元报道
【新智元导读】首个专为中文量身打造的ChineseGLUE来袭!目前拥有八个数据集的整体测评及其基线模型,20多位来自各个顶尖机构的自愿者加入并成为了创始会员。还发布了已经处理好的大规模中文语料,可用于语言理解、预训练、文本生等任务,包含14G左右数据,含30亿中文字,已在新智元小程序宣布首发!欢迎来新智元 AI 朋友圈与大咖一起讨论~
GLUE终于有中文版了!
如果要评选NLP领域基准TOP 3,GLUE必须拥有姓名。GLUE是一个自然语言任务集合,包含了以下任务:
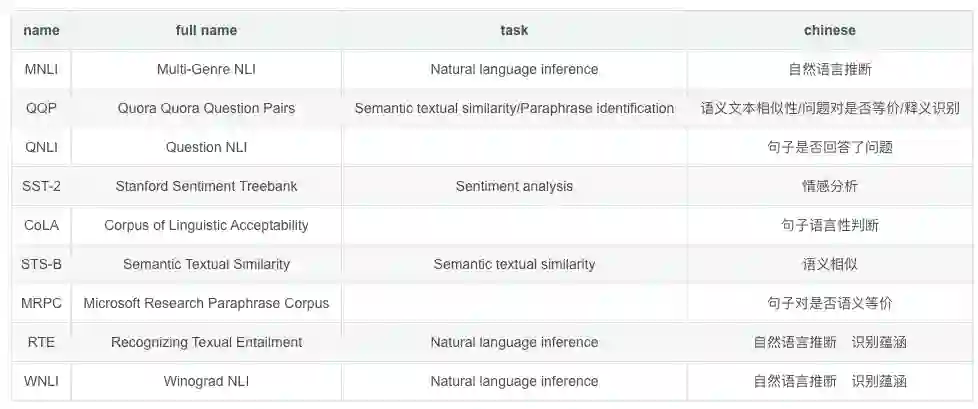
但一直以来GLUE只针对英文,没有专门针对全世界使用人数最多的语言汉语的GLUE基准。
和英文这种基于字母的语言不同,中文是象形文字,字与字之间没有分隔符,不同的分词(分字或词)会影响下游任务。显然当前的GLUE无法满足中文NLP。
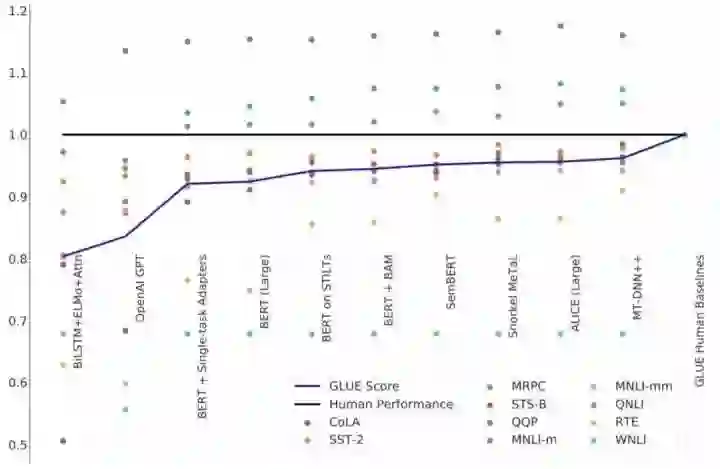
相对于英文的数据集,中文的公开可用的数据集还比较少。很多数据集是非公开的或缺失基准测评的;多数的论文描述的模型是在英文数据集上做的测试和评估,那么对于中文效果如何?不得而知。
如今,预训练模型极大的促进了自然语言理解。不同的预训练模型相继产生,但不少最先进(state of the art)的模型,并没有官方的中文的版本,也没有对这些预训练模型在不同任务上的公开测试,导致技术的发展和应用还有不少距离,或者说技术应用上的滞后。
是时候推出针对中文的GLUE基准了!
现在,由算法专家、AlBERT第一作者等20余位顶尖专业人才成立“开源协助组织”,共同推出了针对中文的GLUE基准:ChineseGLUE。
【中文任务基准测评ChineseGLUE】地址:
https://github.com/chineseGLUE/chineseGLUE
专为中文量身打造的ChineseGLUE,还发布了已经处理好的大规模中文语料,可用于语言理解、预训练、文本生等任务,包含14G左右数据,含30亿中文字,已在新智元小程序宣布首发!
地址:
http://106.13.187.75:8003/index
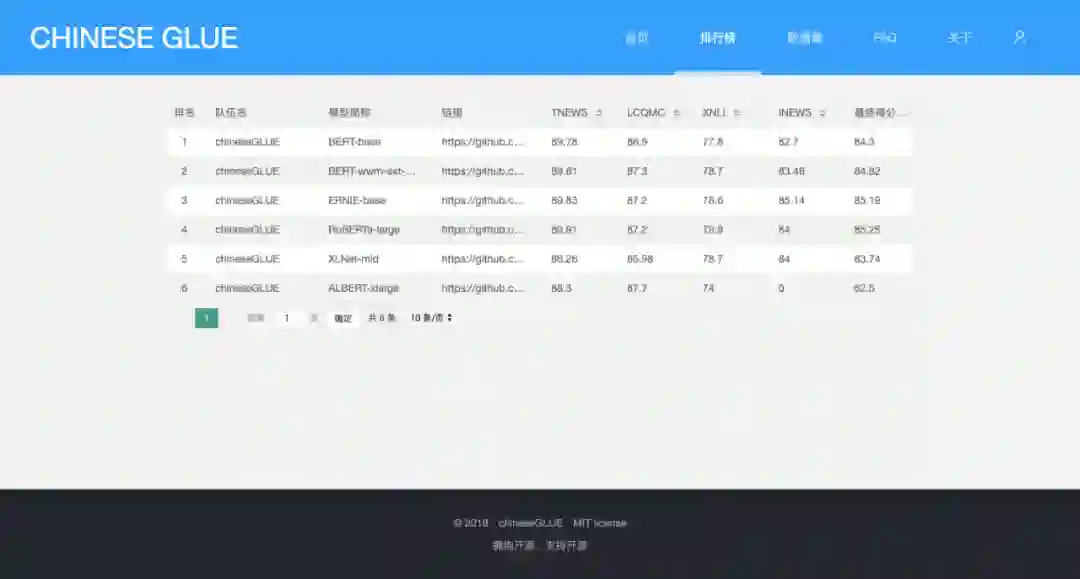
ChineseGLUE即中文语言理解测评基准,包括代表性的数据集、基准(预训练)模型、语料库、排行榜。
新智元获悉,团队的“目标”是跑遍主流的中文数据集。解决当前中文任务公开可用数据集匮乏、没有基准测评、最先进的预训练模型不足等中文任务基础设施问题。
为更好的服务中文语言理解、任务和产业界,做为通用语音模型测评的补充,通过完善中文语言理解基础设施的方式来促进中文语言模型的发展。
该基准会选择一系列有一定代表性的任务对应的数据集,作为测试基准的数据集。这些数据集会覆盖不同的任务、数据量、任务难度。中文任务的基准测试也会覆盖多个不同程度的语言任务。
除此之前,ChineseGLUE也包括了:
公开的排行榜
基线模型,包含开始的代码、预训练模型
语料库,用于语言建模、预训练或生成型任务
可用于语言建模、预训练或生成型任务等,数据量超过14G,主要部分来自于nlp_chinese_corpus项目。
当前语料库按照【预训练格式】处理,内含有多个文件夹;每个文件夹有许多不超过4M大小的小文件,文件格式符合预训练格式:每句话一行,文档间空行隔开。
包含如下子语料库(总共14G语料):
新闻语料: 8G语料,分成两个上下两部分,总共有2000个小文件。
社区互动语料:3G语料,包含3G文本,总共有900多个小文件。
维基百科:1.1G左右文本,包含300左右小文件。
评论数据:2.3G左右文本,含有811个小文件,合并ChineseNLPCorpus的多个评论数据,清洗、格式转换、拆分成小文件。
这些语料,可以通过这两个项目,清洗数据并做格式转换获得;也可以通过邮件申请(chineseGLUE#163.com)获得单个项目的语料,告知单位或学校、姓名、语料用途;如需获得ChineseGLUE项目下的所有语料,需成为ChineseGLUE组织成员,并完成一个(小)任务。
我们知道,本土化意味着不仅仅只是将界面语言翻译成中文,其实还连带着思维转换、认知差异等更深层的改变,NLP基准也不例外。
新智元获悉,ChineseGLUE并不仅仅是名字里加了个Chinese,其实背后做了非常大的改动。
最大的不同,首先就是数据集。GLUE和ChineseGLUE的数据集完全不同,很多非常好的英文的数据集是没办法直接用的。
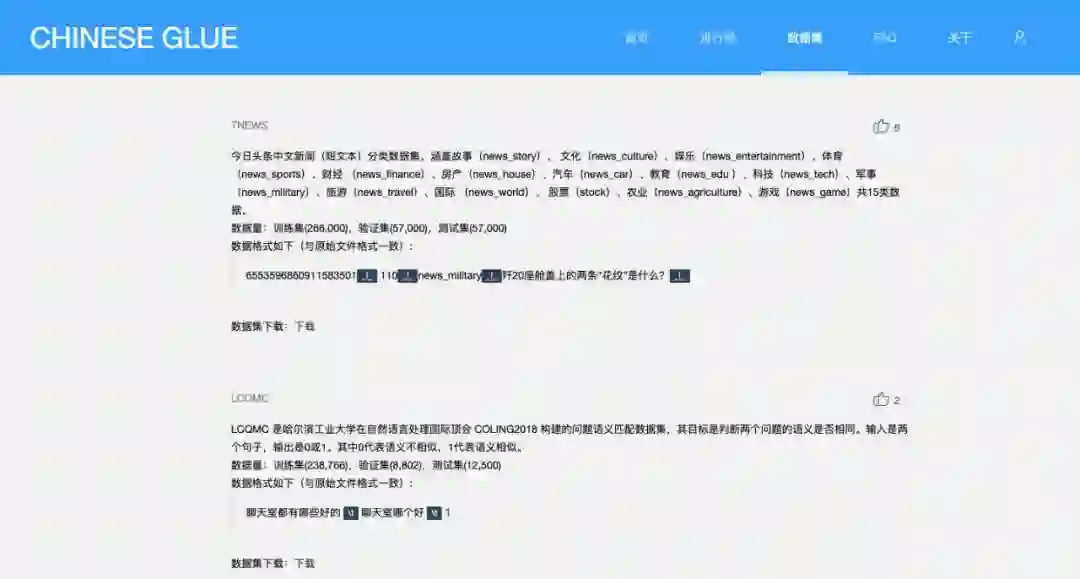
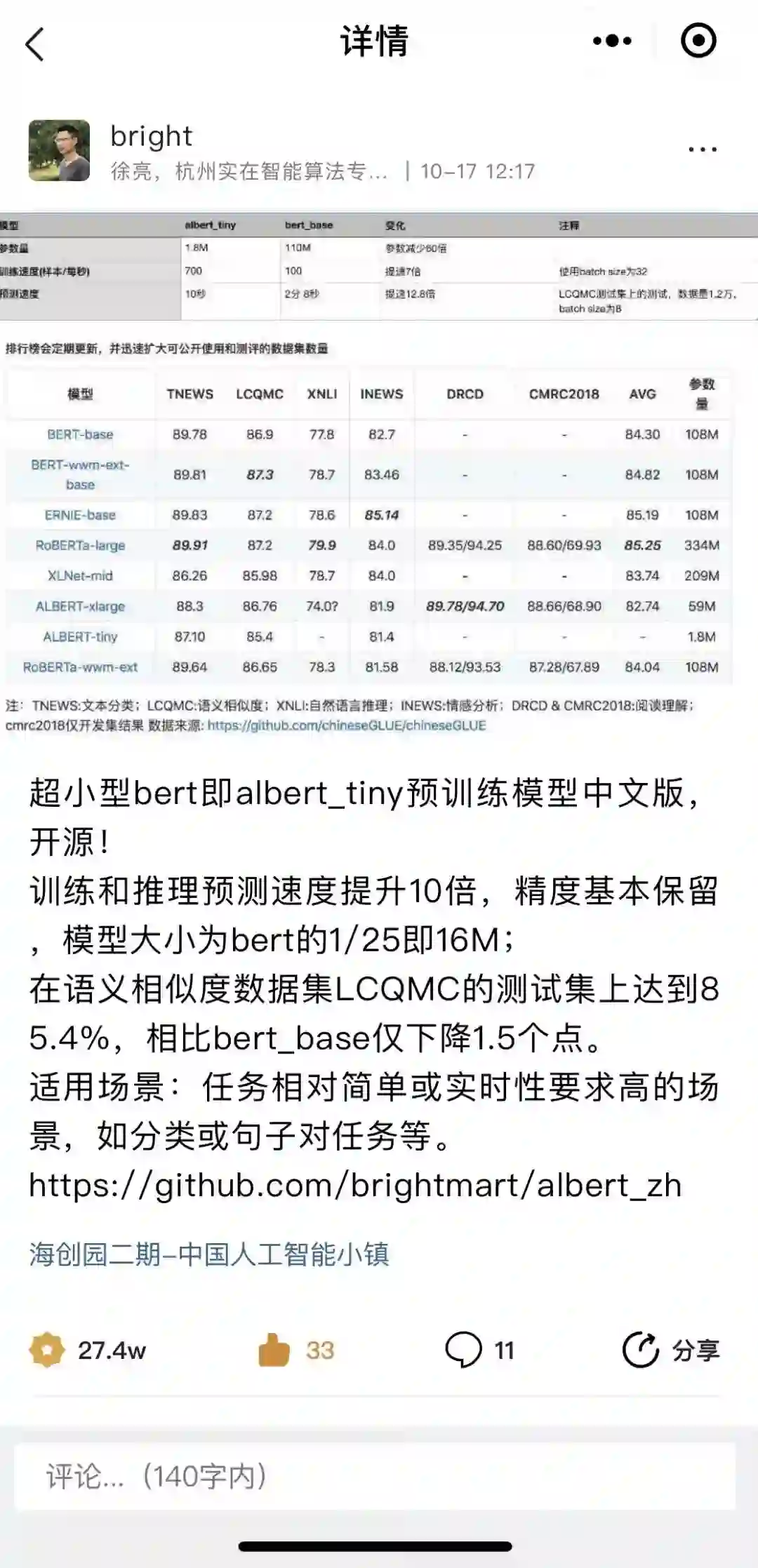
其次是开源问题。英文很多数据集、预训练模型都是开源的,而中文这方面非常稀缺,该项目发起者徐亮说这是目前ChineseGLUE面临最大的障碍了。
由于开源意愿不强,虽然很多大厂最先进的技术都用上了,但没有开源数据集和预训练模型,那么多数人就用不上;同时由于是针对企业内部定制的,缺乏普适性。而ChineseGLUE的目标之一,也是希望能够实现整个中文基础任务测评。
新智元获悉,ChineseGLUE是一个非常大的工程,目前还处在刚刚起步阶段。接下来的规划,大概就是首先呼吁大家一起努力来敦促大厂开源开放,其次希望能有企业赞助,然后激励志愿者来做一些整理工作。
他还透露了该工程的大致路线图,共分成三个阶段:
第一阶段,也就是beta版,从10月24号到12月30号。首先整理搜集8到10个数据集,然后对这些数据集进行最先进的模型测评。提交链接:
http://106.13.187.75:8003/submit
第二阶段,也就是正式版,大概会在明年推出。这个阶段的重心是开始建立一些私有数据集,或者说数据集是公开的但是测试集是私有的,以便吸引更多人参与测评。这样ChineseGLUE就会成为一个更权威、客观的基准测试。
第三阶段,大概在2021年,准备好迎接更大的挑战、更高难度的任务和数据集。
任何开源项目的发展,都需要大量的贡献者为这个社区添砖加瓦。如果你也认可ChineseGLUE,希望能够参与其中,成为未来可能改变中文NLP基准测试的一份子,那么你可能会获得以下好处:
成为中国第一个中文任务基准测评的创始会员
能与其他专业人士共同贡献力量,促进中文自然语言处理事业的发展
参与部分工作后,获得已经清洗并预训练的后的、与英文wiki & bookCorpus同等量级、大规模的预训练语料,用于研究目的
优先使用state of the art的中文预训练模型,包括各种体验版或未公开版本
参与方式:
Hard模式:发送邮件 chineseGLUE#163.com,简要介绍你自己、背景、工作或研究方向、你的组织、在哪方面可以为社区贡献力量,评估后会与你取得联系
Easy模式:ChineseGLUE发起人徐亮已入驻新智元小程序。你可以在新智元小程序里,近距离和徐亮沟通、第一时间获取“内幕消息”,并且与社区中来自华为、阿里、英特尔等大咖0距离交流!
还等什么,赶快加入新智元小程序吧!
排名不分先后:
顾问
张俊林:中国中文信息学会理事,中科院软件所博士,新浪微博机器学习团队AI Lab负责人。技术书籍《这就是搜索引擎:核心技术详解》(该书荣获全国第十二届优秀图书奖)、《大数据日知录:架构与算法》的作者。
创始会员
徐亮:中文任务基准测评chineseGLUE发起人。杭州实在智能算法专家,多个预训练模型中文版开源项目作者(github.com/brightmart)
Danny Lan:CMU博士、google研究员,SOTA语言理解模型AlBERT第一作者。
徐国强:MIT博士,平安集团上海Gammalab负责人。
张轩玮:毕业于北京大学,目前在爱奇艺从事nlp有关的工作,之前做过热点聚合,文本分类,标签生成,机器翻译方面的工作。
谢炜坚:百度大数据部的算法工程师,NLP工业界经验三年,包括NLU、检索式问答、语义匹配、文本分类相关的工作。类相关的工作,先前对BERT/BERT-wwm-ext/Roberta/XLNet等预训练模型均有fine-tune经验。
曹辰捷:平安金融壹账通,算法工程师,做阅读理解和预训练相关的,CRMC2019阅读理解冠军团队成员。
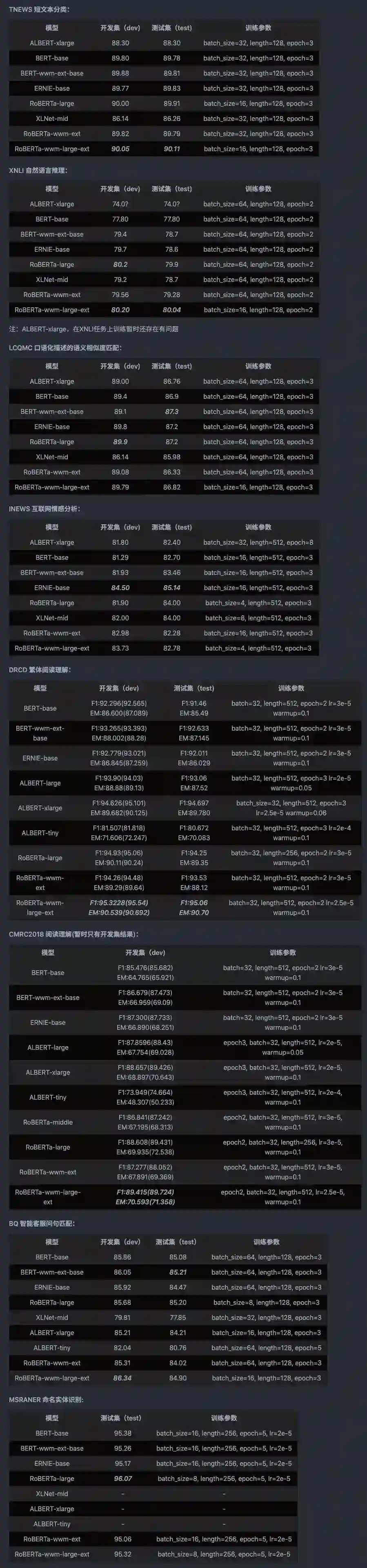
各个模型的总排行榜、多个数据集介绍、相关的基线模型、大规模中文语料、更多组织的信息,请点击【阅读原文】





