从文本分类来看图卷积神经网络
“ 图神经网络火了这么久,是时候掌握它了。”
本文包括以下内容,阅读时间10min
图神经网络是什么意思
文本如何构建图
图卷积神经网络
源代码实现
图卷积神经网络最新进展
本文阅读基础
-
神经网络基础
-
本文不包含拉普拉斯矩阵的数学推导
01
—
“图神经网络”是什么
过去几年,神经网络在机器学习领域大行其道。比如说卷积神经网络(CNN)在图像识别领域的成功以及循环神经网络(LSTM)在文本识别领域的成功。对于图像来说,计算机将其量化为多维矩阵;对于文本来说,通过词嵌入(word embedding)的方法也可以将文档句子量化为规则的矩阵表示。以神经网络为代表的深度学习技术在这些规范化的数据上应用的比较成功。但是现实生活中还存在很多不规则的以图的形式存在的数据。比如说社交关系图谱中人与人之间的连接关系,又比如说电子商务系统中的人与货物的关系等等,这些数据结构像下面这样:
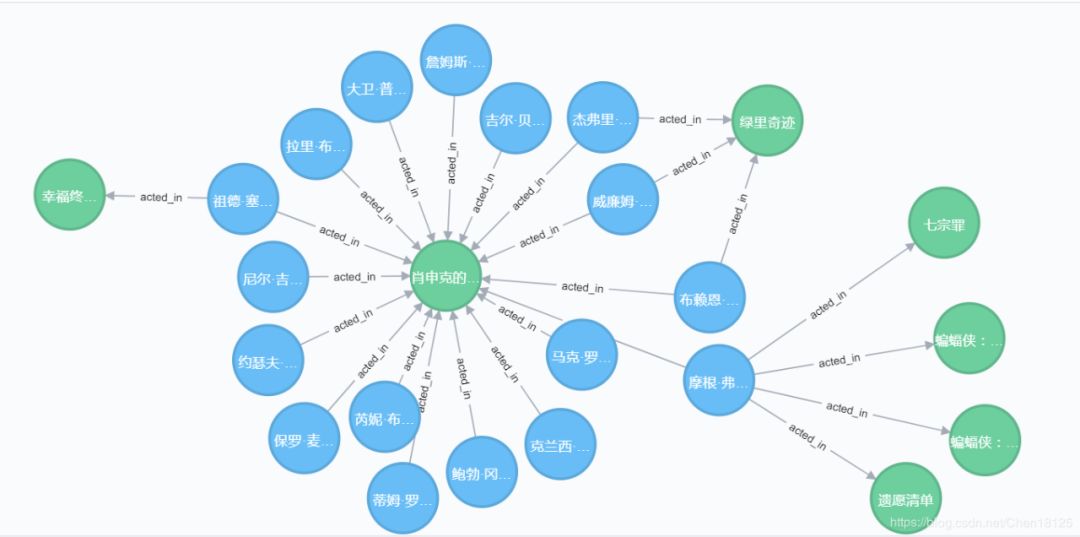
演员-电影 关系位于neo4j的图数据
图神经网络(Graph Neural Network, GNN)是指神经网络在图上应用的模型的统称,图神经网络有五大类别:分别是:图卷积网络(Graph Convolution Networks,GCN)、 图注意力网络(Graph Attention Networks)、图自编码器( Graph Autoencoders)、图生成网络( Graph Generative Networks) 和图时空网络(Graph Spatial-temporal Networks)。本文只重点介绍最经典和最有意义的基础模型GCN。
清华大学孙茂松教授组在 arXiv 发布了论文Graph Neural Networks: A Review of Methods and Applications,作者对现有的 GNN 模型做了详尽且全面的综述。
02
—
文本如何构建图
我们要构建一个具有定义好n个节点,m条边的图。
以经典的分类任务为例。我抽屉里有5本不同的机器学习书,里面一共有a个章节,同时所有书里面一共有b种不同的单词(不是单词个数,是所有的单词种类)。然后我们就可以给a个章节和b个单词标记唯一的id,一共n=a+b个节点,这是我们图的节点。
边的创建
我们有两种节点,章节和单词。然后边的构建则来源于章节-单词 关系和 单词-单词 关系。对于边章节-单词 来说,边的权重用的是单词在这个章节的TF-IDF算法,可以较好地表示这个单词和这个章节的关系。这个算法比直接用单词频率效果要好[1]。单词-单词 关系的边的权重则依赖于单词的共现关系。我们可以用固定宽度的滑窗对5本书的内容进行平滑,类似于word2vector的训练取样本过程,以此计算两个单词的关系。具体的算法则有PMI算法实现。
point-wise mutual information(PMI)是一个很流行的计算两个单词关系的算法。我们可以用它来计算两个单词节点的权重。节点 i 和节点 j 的权重计算公式如下:

PMI(i, j)的计算方式如下:
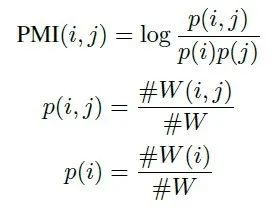
#W(i) 表示所有的滑窗中包含单词节点 i 的个数。
#W(i; j) 表示所有的滑窗中同时包含单词节点 i 和单词节点 j 的个数。
#W 是总的滑窗次数
PMI值为正则说明两个单词语义高度相关,为负则说明相关性不高。因此最后的图构造过程中只保留了具有正值的单词节点对组成的边。
图的节点和边确定了,接下来介绍如何应用图卷积神经网络进行一些学习应用。
2019年AAAI有一篇论文使用了此方法进行章节分类。题目“Graph Convolutional Networks for Text Classification”
03
—
图卷积神经网络
图卷积神经网络(Graph Convolutional Network, GCN)是一类采用图卷积的神经网络,发展到现在已经有基于最简单的图卷积改进的无数版本,在图网络领域的地位正如同卷积操作在图像处理里的地位。
什么是卷积
离散卷积的本质是一种加权求和。
https://www.zhihu.com/question/22298352
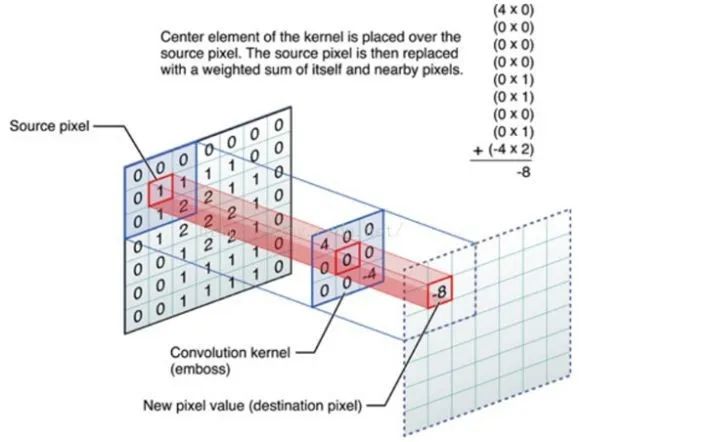
卷积过程示意图
CNN中卷积的本质就是利用共享参数的过滤器 kernel,通过计算中心像素点及相邻像素点的加权和来构成feature map实现空间特征的提取,加权系数就是卷积核的权重系数。卷积核的权重系数通过BP算法得到迭代优化。卷积核的参数正是通过优化才能实现特征提取的作用,GCN的理论很重要一点就是引入可以优化的卷积参数来实现对图结构数据特征的获取。
社交网络中图结构
对于图 







那么有什么东西来度量节点的邻居节点这个关系呢?拉普拉斯矩阵。举个简单的例子,对于下图中的左图而言,它的度矩阵 



图结构数据的各种表示
以下是重点
图卷积网络(GCN)第一层的传播公式如下:
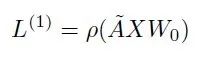
ρ是激活函数,比如ReLU。
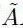
X是第一层输入的特征矩阵,维度N*M,M表示每个节点的特征向量维度;
Wo是权重参数矩阵,维度M*K,K代表转给下一层的向量维度。
因此第一层输出L1的向量维度就是 N*K。
在上面介绍的文本分类任务中,
X是原始输入,我们用对角线为1的单位矩阵来表示,维度N*N;可以理解为是对节点的one-hot表示。Wo采用的参数是N*K随机初始化(K=200),。
XWo 的维度就是N*200,相当于对每个输入节点做了embedding,维度为200。
A * XWo 这个矩阵乘法怎么理解?这才是理解图卷积的关键。复习一下矩阵乘法公式,发现新生成的L1这个N*K矩阵的每一个节点的K个维度,都是对应该节点的相邻节点邻接权重乘以相邻节点在这个维度上的值的累加和。从而实现了通过一次卷积,GCN可以让每个节点都拥有其邻居节点的信息。
(不准确的讲,图的邻接矩阵乘以图节点embedding,就相当于是做一次卷积)
下面我画了一个示意图
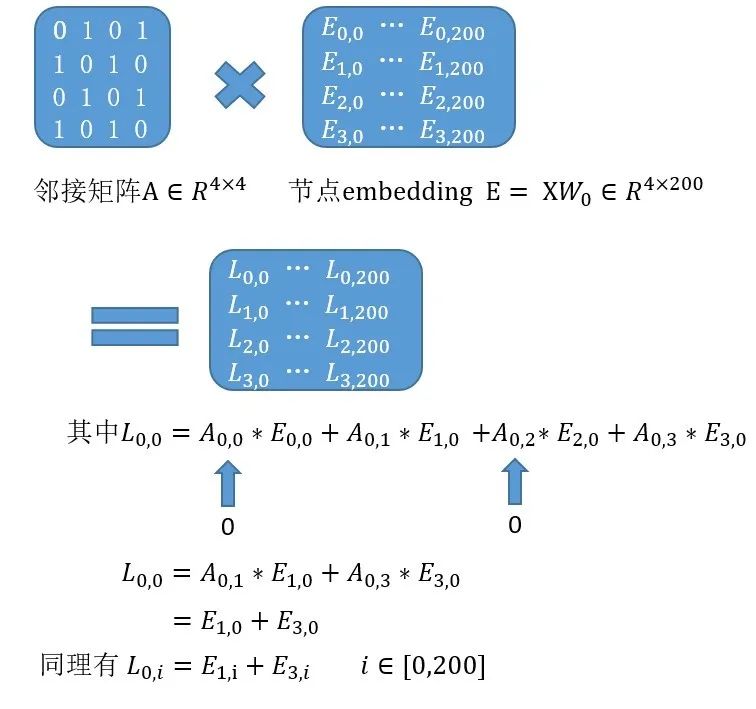
结论:新生成的0号节点的向量全部由相邻的1号节点和3号节点的向量等加权求和得到。从而实现了周边节点卷积(加权求和)得到新的自身的目的。
(邻接矩阵A第一行0 1 0 1表示0号节点和1,3号节点相连,和2号不连接)
如果要让节点拥有周边更广泛的节点信息,可以多次进行卷积。
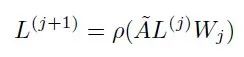
上面的
没有考虑节点自身对自己的影响,因为邻接矩阵对角线为0;
邻接矩阵
没有被规范化,这在提取图特征时可能存在问题,比如邻居节点多的节点倾向于有更大的影响力。
因此更常用的公式是:
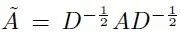
又称为规范化对称邻接矩阵(normalized symmetric adjacency matrix)。关于这个公式理解,可以参考[1]
04
—
pytorch代码实现
有的人看代码更能理解。下面介绍了两层图卷积网络的模型定义:
class gcn(nn.Module):def __init__(self, X_size, A_hat, args, bias=True): # X_size = num featuressuper(gcn, self).__init__()self.A_hat = torch.tensor(A_hat, requires_grad=False).float()self.weight = nn.parameter.Parameter(torch.FloatTensor(X_size, args.hidden_size_1))var = 2./(self.weight.size(1)+self.weight.size(0))self.weight.data.normal_(0,var)self.weight2 = nn.parameter.Parameter(torch.FloatTensor(args.hidden_size_1, args.hidden_size_2))var2 = 2./(self.weight2.size(1)+self.weight2.size(0))self.weight2.data.normal_(0,var2)if bias:self.bias = nn.parameter.Parameter(torch.FloatTensor(args.hidden_size_1))self.bias.data.normal_(0,var)self.bias2 = nn.parameter.Parameter(torch.FloatTensor(args.hidden_size_2))self.bias2.data.normal_(0,var2)else:self.register_parameter("bias", None)self.fc1 = nn.Linear(args.hidden_size_2, args.num_classes)def forward(self, X): ### 2-layer GCN architectureX = torch.mm(X, self.weight)if self.bias is not None:X = (X + self.bias)X = F.relu(torch.mm(self.A_hat, X))X = torch.mm(X, self.weight2)if self.bias2 is not None:X = (X + self.bias2)X = F.relu(torch.mm(self.A_hat, X))return self.fc1(X)# 第一层权重维度 args.hidden_size_1取200,# 第二层权重维度args.hidden_size_2取20;# args.num_classes=5
最开始介绍的5本书的章节和单词构成的图,一共有100个章节节点和5000个单词节点。每个章节节点的标签是属于哪本书。一共五类。希望通过对其中50个章节的标签进行标记和训练,让网络学会剩下50个章节属于哪本书。属于半监督学习。
05
—
图卷积神经网络最新进展
本文的写作基础是来源于AAAI2019的一篇论文Graph Convolutional Networks for Text Classification,用GCN做文本分类。在AAAI2020上,清华大学科大讯飞的学者提出张量卷积神经网络在文本分类的应用Tensor Graph Convolutional Networks for Text Classification,通过利用文本构成多种图结构,进一步提高文本分类的性能。
在崭新的的2020年,图神经网络GNN又有哪些崭新的发展可能呢?分享一个AAAI2020详细讲解GNN的ppt,很好的回答了这些问题。

链接
http://cse.msu.edu/~mayao4/tutorials/aaai2020/
参考阅读:
[1] 另类解读
https://zhuanlan.zhihu.com/p/89503068
[2] 另类解读
https://www.zhihu.com/question/54504471/answer/332657604
[3] 挖坑好文
Yao, Liang, Chengsheng Mao, and Yuan Luo. "Graph convolutional networks for text classification." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. 2019.
[4] 一个图卷积分类的项目代码
https://github.com/plkmo/Bible_Text_GCN
深度学习冲鸭

一个小小DLer,已经在深度学习道路上走过了不少时间,写过简书、CSDN,打过各种深度学习比赛,写过很多paper解读文章。公众号后台回复:知识图谱、python、DL、ML、NLP、C++、TensorFlow、QL、pytorch4NLP、PRML,可以获得对应的资源。
有帮助的话,给个好看吧!



