基于知识图谱的人机对话系统 | 公开课笔记

参加 2018 AI开发者大会,请点击 ↑↑↑
分享嘉宾 | 刘升平(云知声 AI Labs 资深技术专家)
来源 | AI 科技大本营在线公开课
人机对话系统,或者会话交互,有望成为物联网时代的主要交互方式。而语言的理解与表达和知识是密切联系的,知识图谱作为一种大规模知识的表示形式,在人机对话系统中各模块都有重要的应用。而知性对话,则是基于知识图谱的人机会话交互服务。
AI 科技大本营邀请到了云知声 AI Labs 资深专家刘升平针对「基于知识图谱的人机对话系统方法与实践」做系统的讲解和梳理。
本次公开课介绍了知性会话的架构和关键技术,并结合工业级的人机对话系统实践经验,阐述了知识图谱在人机对话系统的核心模块上面的应用等等。

刘升平:云知声 AI Labs 资深技术专家/高级研发总监。前 IBM 研究院资深研究员,中文信息学会语言与知识计算专委会委员。2005 年获得北京大学数学学院博士,国内语义网研究的开创者之一,是 2010 年和 2011 年国际语义网大会的程序委员会委员。曾在语义网,机器学习、信息检索,医学信息学等领域发表过 20 多篇论文。在 IBM 工作期间,两次获得 IBM 研究成就奖。2012 年底,刘博士加入云知声 AI Labs,领导 NLP 团队,全面负责自然语言理解和生成、人机对话系统、聊天机器人、知识图谱、智慧医疗等方面的研发及管理工作。
在本次公开课上,他全面而具体地讲述了知识图谱在人机对话系统中的发展与应用,主要分为以下四部分:
语言知识、对话系统综述
知性会话的基本概念及案例分析
知性会话的关键技术:知识图谱的构建,实体发现与链接
知性会话的关键技术:话语理解及自然应答生成
▌一、语言、知识与人机对话系统综述
1. 语言和知识
语言和知识是密切相关的。这张冰山图很形象地解释了语言和知识的关系,我们看到的语言只是冰山上的一小角,就是我们说的话。但是你如果想理解这句话,跟这句话相关的背景知识就像冰山下面这一大块。
所以,这也是自然语言跟语音、图像很不一样的地方,我们听语音或看一个图片,它的所有信息都在语音信号或者图像像素里,但是语言的话就完全不是这样,这也是自然语言理解远远比语音识别或者图像识别更难的一个地方。
这次的报告内容综合了我最近三年在CCKS会议上做的三个报告。

2. 人机对话系统

人机对话系统最早在工业界引起比较大的轰动是 Apple Siri,它当时还是 iPhone 上的一个 APP,2010 年被苹果收购了。Siri 的创新在于,我们传统的手机 GUI 界面上加了一个语音 Voice-UI。
真正引发人机对话系统革命性创新的是于 2014 年推出的 Amazon Echo,它是一个完全基于语音交互的硬件,其语音技术比 Siri 前进了一大截,因为它支持远讲。
2017 年亚马逊又推出了一个带屏幕的音箱 Amazon Echo Show,大家觉得这是不是又回到 Siri,还是基于 GUI 呢?这里要注意区别, Amazon Echo 是 VUI+GUI,也就是说它是以 VUI 优先的,因为语音的优势是输入很便捷,你说几个字就能代表一段指令,可以代替操作很多界面。但缺点是输出很低效,如果在屏幕上显示很多内容,但是你要用语音说出来,可能得花好几分钟。所以 VUI+GUI 的结合是把两者优势做了整合,VUI 用来做输入,GUI 用来做输出。
更高级的形态是现在很多电影都能看到的像Eva、《钢铁侠》或者《西部世界》里面这种人形的机器人,完全可以跟人自由对话,它的交互是 VUI++,真正模拟人的多模态的交互形态,这个时间点也许在 2045 年会出现。
为什么人机对话系统目前在工业界这么热门?它最重要的一个意义是有望取代目前在手机上的 APP,成为 IoT 时代的一个最重要的人机交互形式,这是它的最主要意义所在。
3. 人机对话系统的交互形式和应用场景
就像人和人说话有多种目的和形式一样,人机对话系统也包含很多种交互形式:
1、聊天。典型代表是小冰,它包括问候和寒暄,其特点是没有明确目的,而且不一定回答用户的问题。聊天在现有的人机对话系统中主要是起到情感陪伴的作用。
2、问答。它要对用户的问答给出精准的答案。这些问题可以是事实性的问题,如“姚明有多高”,也可能是其他定义类,描述类或者比较类的问题。问答系统可以根据问答的数据来源分为基于常见问题-答案列表的FAQ问答,基于问答社区数据的CQA问答,基于知识库的KBQA问答。
3、操控,只是解析出它的语义,来供第三方执行,最典型的操控是打开空调、打开台灯,或者播放某一首歌。
4、任务式对话。它是一个目的性很强的对话,目标是收集信息,以完成某个填表单式的任务,最常见的像订外卖、订酒店、订机票,这种方式通过对话来做。
5、主动对话。让机器主动发起话题,不同的是,前面的交互都是让人来主动发起这个交互。

目前人机对话系统的应用场景有很多,像音箱、电视、空调等等,其显著特点是它不是人可以直接触摸到的,可以将语音交互看成遥控器的一种替代品,有遥控器的地方就可以用语音来交互。
另外一个应用场景是在车载方面,因为在开车时,你的眼睛和手脚都被占用着,所以这时通过语音来接听电话、导航甚至收发微信,是非常方便的,也比较安全。车载是刚需场景,所以目前出货量最多是在这块。像我们是从 2014 年开始做车载语音交互方案,到现在有 1500 多万的出货量。
另外一个应用领域是儿童教育机器人,右下角这些各种形状的儿童机器人,实际上可以看成儿童版的音箱,它的内容是面向儿童的,但是交互形式也是人机对话的方式。
4. 人机对话技术架构
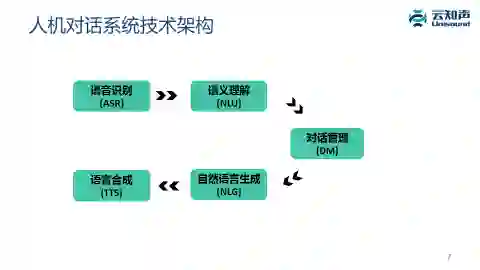
人机对话系统从学术界来讲,它的研究历史非常悠久,可能 AI 提出以后,在七八十年代就开始研究。它的技术分为五大部分:
1、语音识别:主要解决复杂真实场景噪声、用户口音多样的情况下,把人说的话转成文字,即做到“听得清”。
2、语义理解:主要是把用户说的话转成机器能理解执行的指令或查询,即做到“听得懂”。
3、对话管理:维护对话状态和目标,决定系统应该怎么说、怎么问下一句话,也就是生成一个应答的意图。
4、自然语言生成:就是根据系统应答的意图,用自然语言把这个应答意图表达出来。
5、语音合成: 用机器合成的语音把这句话播报出来。
这样形成一个完整人机对话的闭环。
5. 语音识别场景演进

因为人机对话系统是以语音作为入口,所以需要讲讲语音技术这块的进展。强调一点的是,如果想真正做好人机对话系统,除了对自然语言处理技术了解之外,对语音技术也必须有所了解。
最早像 Siri 这样的场景是近讲模式,它最主要解决的问题是口音问题,目前这方面的识别准确率非常高,已经能做到 97% 左右,大家平时用的手机语音输入法就是这种模式,一般建议离麦克风的距离是30cm左右。
Amazon Echo 则是远讲模式,你可以离麦克风 3 米甚至 5 米这么远。它要解决的问题很多,因为你离它远了以后更容易受周边噪音的影响,还有一个更致命的影响是声音反射引起的混响问题,特别是在玻璃房里,声音不断在反射,麦克风收到的声音就是很多声音混杂在一起。还有一个很不一样的地方,就是我们用微信语音的时候可以按下说,或者按着一直说,但当你面对一个音箱时,因为你离它有 3-5 米远,不可能按着说话的,这时就有新的技术,叫“语音唤醒”,就像我们跟人说话时叫人的名字一样,像“Hi,Google”,先唤醒机器,再同它对话。
目前语音识别最难的场景是人人对话,在人和人对话的时候,先对它做录音,而且要把它转成文字,这个最常见的场景像开会,自动把不同的人说话转录下来,甚至自动形成会议纪要。还有像司法的庭审,只要是和人说话的场景下都可以用到。这里面最难的问题是鸡尾酒会问题,很多人在一起,环境很嘈杂,大家都在说话,人可以听到只关注的人的说话,即使很嘈杂,但两个人一样可以聊天对话,但这对机器来说很难。
6. 人机对话系统中的机器角色演进
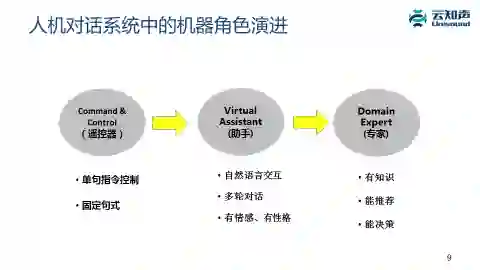
在人机对话里面机器的角色有个演进的过程:最早人机对话很简单,可以看成是个遥控器的替代品,用户通过固定句式或者单句指令来控制这个系统。
Siri、Amazon Echo 是一种助手的形态,也就是说,你可以通过自然语言交互,且对话是多轮的,甚至可以让机器有些情感。
但是下一个阶段是它会变成专家的角色,特别是面向行业或者特定领域时,当我们跟音箱对话时,希望这个音箱同时也是一个音乐专家,它可以跟你聊音乐的问题,可以跟你聊古典音乐,甚至教你一些音乐知识。我们跟儿童教育机器人对话时,希望这个机器人是一个儿童教育专家,我们跟空调对话时希望后面是个空调专家。这时它的特点是需要有这个领域的知识,而且能够帮你做推荐、做决策。
▌二、知性会话基本概念及示例分析
我们做对话必须理解这几个概念——语义、语境、语用。特别是语境,它就是在对话时才有含义,语境就是指人和人发生对话时的一个具体环境,这个环境又包括言语语境,就是我们所说的上下文,还有很多非言语语境,如说话的时间、地点、天气都是非言语语境,还有说话人的信息等等,我们今天强调的知识也是一种重要的非言语语境。
假如用户说「太冷了」这三个字,语义是温度有点低,但如果考虑语用,这句话在特定语境下面传递的会话意义、真实含义: 如果在车里面开着空调,理解这句话的意思是把空调温度调高一点;如果是冬天没有开空调,这句话的意思可能是把车的暖气打开,或者把车的窗户关上;现在马上到秋天了,如果一个女孩子对你说「太冷了」,她的含义可能是想让你给她一个拥抱之类的。所以语境和语用是非常重要的概念,如果做人机对话系统,都会接触到这两个概念。
1. 人机(设备)对话系统下的语境
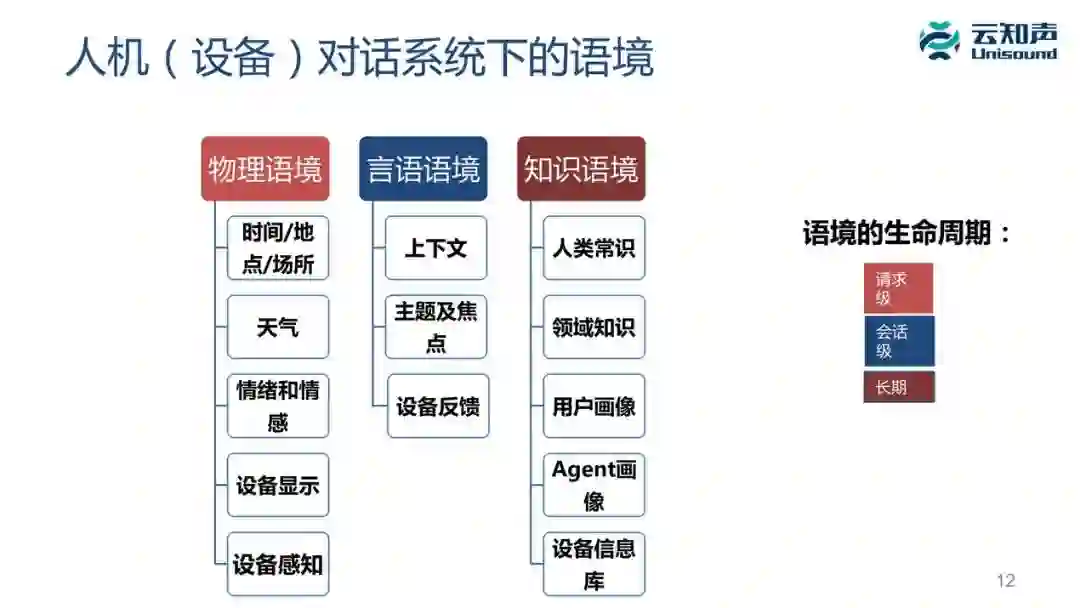
刚才是说人和人对话时,语境很关键,现在我们做人机对话系统,人和设备对话的时候有哪些语境呢?
1、物理语境。也就是你说话当时现场的信息,包括(1)时间、地点、场所,这个场所是指在车里或在家里等等。(2)天气。(3)情绪和情感。(4)设备上面显示的内容。(5)设备能感知到的信息,比如我们和空调对话,空调能够感知到室内外的温度、湿度。这个语境的生命周期是请求级的。
2、言语语境。(1)上下文,设备上和设备上面反馈的信息也是一种上下文,这个生命周期可以看成是会话级的。
3、知识语境。包括:
(1)人类的常识和领域知识。举个简单的例子,以前我们一句话叫「中国乒乓球队谁也赢不了」,还有「中国足球队也是谁也赢不了」,这两句话看起来字面是一样的,但人能够理解这两句话的差别,因为我们有常识是:中国足球队很弱,中国乒乓球队很强。所以知识对这句话的理解至关重要。
(2)用户画像,包括用户的一些基本信息,用户的性别、年龄、文化水平、爱好等等。(3)Agent 画像,就是这个机器人定义的信息,像小冰把它的 Agent 画像定义为一个 18 岁的邻家小妹。(4)设备信息库,如果把音箱作为中控的话,中控连接的设备信息、设备状态等都是语境。如果在家里对中控说「我回家了」这句话到底是什么含义?中控可能会根据你的设备状态、根据当前的环境情况,给你决定是开灯还是关灯,是给你开窗户还是拉窗帘等等。
2. 不要神话知识图谱
知识图谱的历史和概念大家已经比较理解了,我这里主要强调几个基本概念:最重要的知识图谱概念就是「Things,Not Strings」,知识图谱里面的东西都是一个个实体而不是字符串。
另外,我们也不要神化知识图谱,它其实只是一种知识的组织形式而已。因为不管做什么应用,在各种场景下都有知识,以前可能用其他方式来表示这个知识。在概念层,我们以前也接触过类似的东西,就像我们做关于数据库建模时用 ER 模型,它也是一种概念模型。我们写程序,做面向对象设计时会画些类图,这些都是概念模型,这些模型都可以很方便的转成知识图谱来表示。我认为知识图谱首先是知识的一种组织形式。在数据层,知识图谱是一种图模型,它是用节点、边来表达实体、值、关系和属性等。
3. 什么是知性会话?
什么叫知性会话?我这里举个例子,用户可能跟音箱聊天:「你喜欢谢霆锋?」「喜欢,他很酷」「你知道他女朋友是谁吗?」「王菲」「来一首她的《传奇》」这是一种操控,机器就会给你播放王菲的传奇,播放之后系统还可以接着问说「你还想听李键的原唱吗?」这是一种主动对话,用户说「好的」,系统可以播放李键的《传奇》,用户还可以问「他的音乐风格是什么样的?」系统说「李健的风格,有民谣的简洁,但比民谣华丽得多。」
你看这个例子的话,它涉及很多跟音乐相关的知识,还包括一些歌星的人物相关的知识。交互形式有聊天、问答、操控、主动对话,是通过知识把它们关联在一起,你会感觉整个对话是个很流畅的对话。
总结下来,知性会话的意思是:它以知识图谱为中心,通过实体发现与链接技术把各种各样可以用来作为对话的数据源融合在一起,实现跨领域、跨交互形式的多轮对话。
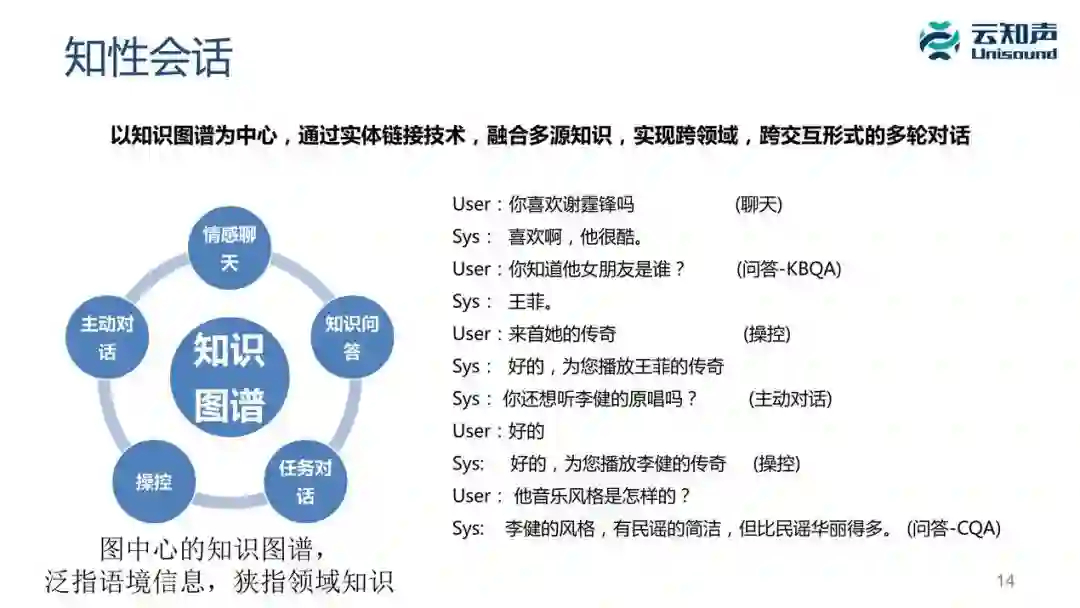
知性会话的主要特点有:一是跨领域,跨交互形式共享上下文,你可以看它的聊天和问答可以衔接在以前;二是它体现了领域专家的机器人定位,它对这些领域的知识非常了解,可以在聊天或者问答中体现出它掌握的领域知识。它有这方面的知识后,也可以主动发起一些对话。
知性会话的核心技术有:
离线处理,首先要有知识图谱,所以有一个知识图谱构建的问题。另外,我们要把各种跟对话相关的数据通过实体发现与链接技术跟知识图谱关联起来。
在线处理。基于知识做话语理解,怎么在聊天里把知识融合进去,还有基于知识图谱的问答,基于知识图谱的主动对话等。
▌三、知性会话关键技术
(一)知识图谱构建
1. 知识图谱的构建方法
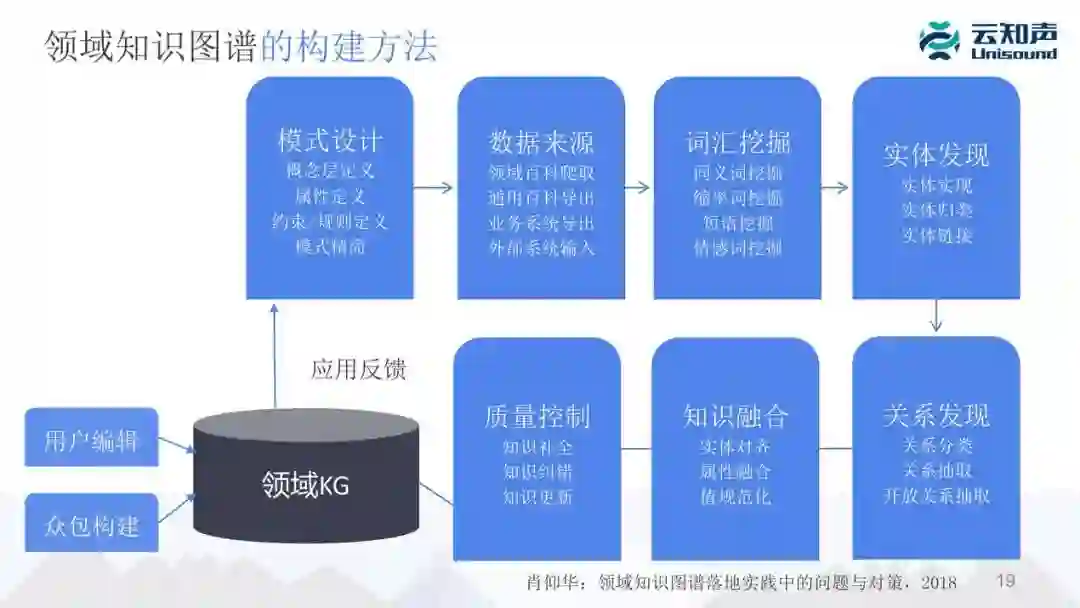
这里我引用复旦肖老师总结的知识图谱构建方法,第一步是做模式设计,我们要定义有哪些类或概念、哪些属性或关系。
第二步确定我们的知识从哪来,所谓的数据来源,这里可以通过对一些结构化的数据、非结构化的数据做转换、对非结构化的数据,即文本,从里面去信息抽取。
第三步,知识图谱里最重要的是词汇的挖掘,各种同义词、缩略词、短语等等。
第四步,有词汇不够,我们要把同义词聚集为一个概念,也就是所谓的实体发现,包括实体实现、实体归类、实体链接等等。
第五步,除了实体之外,知识图谱里还有边,也就是关系,我们要做关系的抽取。
第六步,因为我们的知识图谱可能来源于不同的数据源,所以我们要做知识的融合,主要是实体对齐、属性融合、值的规范化。
最后,对知识图谱的质量做检查控制,包括知识的补全,有错的话要纠错,还有知识更新,最后形成一个领域的知识图谱。
2. 知识图谱的评估方法
如果你不知道怎么评价知识图谱的话,就根本不知道你的知识图谱建得好还是坏、有用还是没用。评估的方法基本可以分为四大类别:最重要的类别是第二类基于应用,把知识图谱在应用里看效果怎样,通过应用效果来间接评估知识本体。我们不要先找几十个人花一两年建知识图谱然后再去找应用,而是知识图谱必须是应用驱动的,根据应用效果来评价知识图谱,这是推荐的一个方法。
还有基于黄金标准评估,也就是说如果我们有些好的知识图谱,或者我们可以建一个小的知识图谱,根据这个标准知识图谱去评估我们建的知识图谱的情况。我们可以看看计算概念和关系的覆盖率,即有多少出现在标准知识图谱中的概念和关系被包含了,这可以评价我们的建的知识图谱是否完整。
另外,简单的评估方式基于指标。可以定一些统计指标,比如这个知识图谱里有多少概念、多少关系、关系属性,然后我们还可以对它进行抽查,看它的准确率、一致性等指标。
3. 敏捷构建
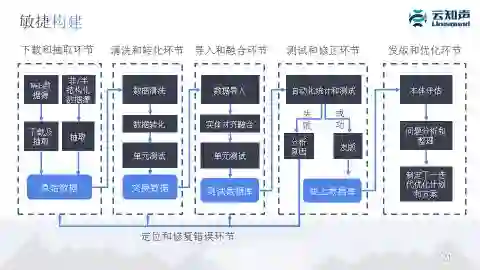
我们现在做应用很多情况都是做敏捷开发,也就是说可能半个月或者一个月就会发一次版本,这时候我们知识图谱也要跟着应用快速迭代,这时候是需要对知识图谱敏捷构建的过程。这里强调我们要对知识图谱做自动化的测试,测试完之后要判断它是否能够发版,发版之后要继续分析它目前的问题。可以把知识图谱看成一个软件,它是不是有哪些 bug 或者需要哪些新功能,根据这些制定下一个版本的发版计划。核心想法就是把知识图谱也看成是一个软件,也要有版本管理,也要有敏捷的开发。
(二)实体发现与链接
需要解决的问题:如果我们这时候已经有知识图谱了,现在还依赖于实体发现与链接技术。这个技术解决刚才那个问题,「Thinks,not Strings」,它最重要的问题是把字符串和知识图谱的实体关联起来。它要解决两个问题,一个是我们同一个意义可能有表达不同的形式,像「科比」、「黑曼巴」、「科神」很多是指的科比这个人。还有一个是自然语言或者字符串本身有歧义性,就像「苹果」可能是指苹果电脑、苹果手机,也可能是一个水果。
解决方法:所以它的做法是分两步,实体发现和实体链接,实体发现是发现文本中的 mention,就是字符串,像「这个苹果很贵」的「苹果」是 mention。实体链接是把这个 Mention 和知识图谱里的实体关联起来,知识图谱里的实体关于「苹果」可能有多个实体,有苹果公司,还有苹果这个品牌,还可能是苹果手机、苹果电脑,还有水果叫苹果等等,这里的「苹果」到底指哪个呢?可能要靠上下文的判断。
1. 基于实体的多源数据融合
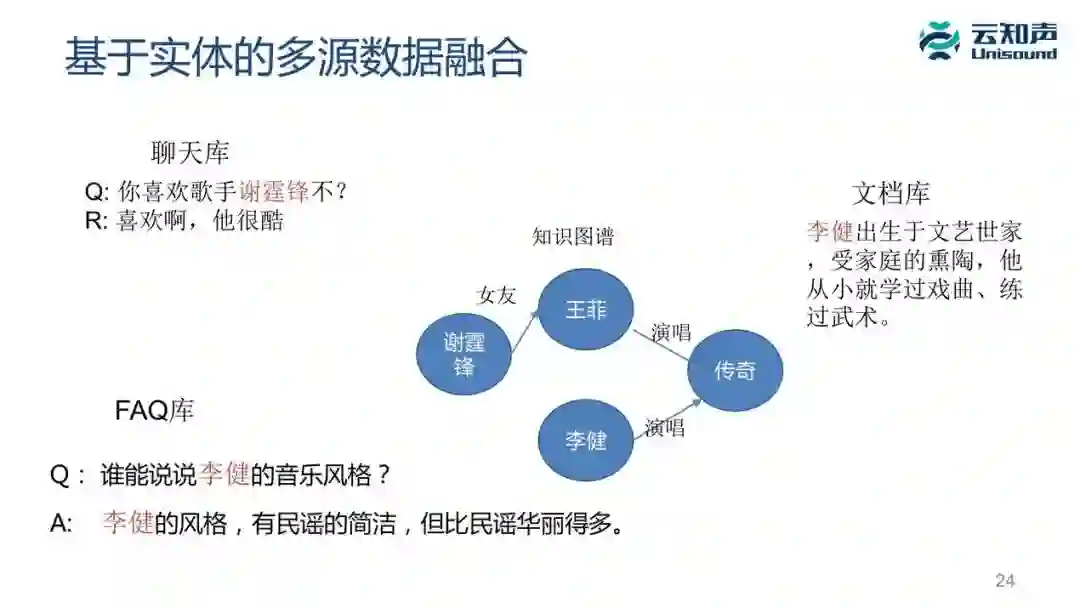
我这里举个很简单的知识图谱,谢霆锋的女友是王菲,王菲唱了《传奇》这首歌,《传奇》这首歌的原唱是李健。
我们在对话这块的数据来源有几个:一个是聊天库,像「你喜欢歌手谢霆锋吗」「喜欢,他很酷。」,还有 FAQ 库,我们可能从百度知道或者很多地方可以找到社区问答的数据,就像这里说「谁能说说李健的音乐风格?」「李健的风格,有民谣的简洁,但比民谣华丽得多。」
我们也会从网上找到很多文档,包括百科的文档或者网页性的文档,我们对这些文档、聊天库、FAQ 库、文档库,我们都要去做实体链接,把这里面出现的歌手和我们知识图谱的歌手关联起来。
2. 如何进行实体发现与链接?

第一步预处理,首先建立一个 mention 到 entity(实体)的关系,这也是目前这个算法的局限性,我们事先要知道一个 mention 可能对应到哪些实体。然后抽取实体相关特征:
一是实体的先验概率。就像苹果可能是水果的先验概率为 40%,是苹果手机的先验概率为 60%,如果我们说葡萄呢?可能葡萄是水果的先验概率有 90%,10% 是其他东西。二是实体上下文的词分布,我们看这些实体周边到底是什么词,或者它篇章的主题词,就像苹果手机出现在文章里都是科技类的主题词。三是实体之间的语义关联度,因为知识图谱是一个图的结构,所以每个实体环绕它周边都有些其他的实体,这些实体都是相关的特征。
第二步,这时实体链接就变成一个排序问题,找到 mention 之后,我们可以根据前面 mention 关系表找到它的候选实体,现在保持只需要对候选实体排序,返回一个最可能的实体。
第三步,对候选实体进行排序,可以用最基本的方法。这个有两大类:一个是实体本身的信息,还有一个是可以利用实体和实体之间的协同关系做排序。如果是苹果旁边的实体都是偏电脑类的,那这个苹果可能就指苹果电脑。
(三)融合知识的话语理解
做完实体链接处理以后可以做真正的对话系统这一块,对话系统里最基本的是对用户话语的理解,我们怎么去理解用户说的一句话。
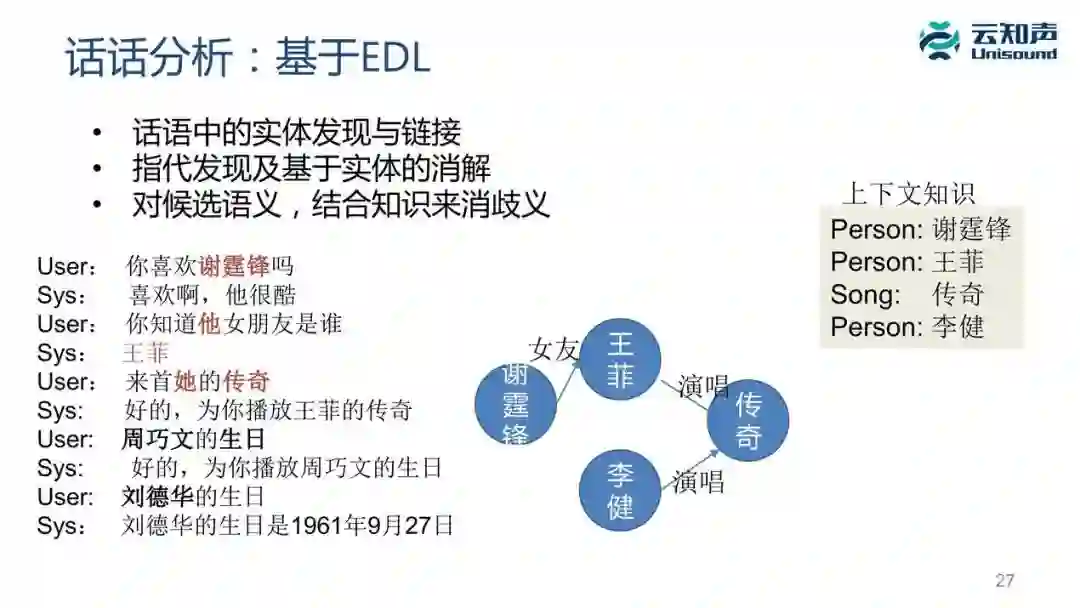
第一步要做实体的发现与链接,像刚才那个例子,「你喜欢谢霆锋吗」,我们要把谢霆锋跟知识图谱的实体关联起来。
第二步做指代发现,比如「你知道他女朋友是谁」,那这个「他」到底是指谁,我们首先要发现他是一个指代词,然后再根据上下文去判断「他」在这个例子里面是谢霆锋这个实体。
另外,我们做语义理解还有一种情况是结合知识做消歧义。比如用户说「周巧文的生日」,因为《生日》是一首歌的名字,周巧文是这个歌的歌手,这时候我们理解它是个音乐,因为本来就在音箱下面,这时我们可以直接播放周巧文的《生日》这首歌。但是如果系统又问一下「刘德华的生日」,这时候虽然我们的命名实体识别很有可能把「生日」也可能打成歌名的标签,刘德华打成歌手的标签,歌手的歌名,很容易以为是播放音乐,但是我们通过知识的验证知道刘德华并没有唱过这首歌,这时候要转成问答,这不是一个操控性的指令。直接返回他的生日,说「刘德华的生日是 1961 年 9 月 27 日」。
这几个例子是我们通过知识帮助去理解用户的指令。我下面再讲一下怎么把知识和聊天结合起来。
(四)融合知识的聊天
1. 上下文
现在学术界都用深度学习模型,所以我会简单讲一下深度学习的方法,把它的基本思想讲一下。我们现在一般在学界把聊天变成一个 Sequence-to-Sequence 的模型,就是有一个 encoder对输入进行编码为向量, 通过 decoder 把应答生成出来。这时核心问题变成怎么把上下文加进去,最基本的方法是把上下文的文本跟当前文本的向量合在一起作为 encoder 的输入;另外我们可以把上下文作为向量,在 decoder 阶段输入;或者用主题模型对这个 session 去建模,把这个 session 主题模型也作为 decoder 的输入,这样就可以实现一并上下文的效果。
2. 一致性
聊天还有一个很重要的问题是一致性。我们刚才说语境里面有一个agent画像,跟我聊天的对象虽然是机器人,但是它有统一的人格,它的性别、年龄、籍贯、爱好应该是一致的,这是目前聊天机器人里面最难的一点。你对机器人问它「多大了?」它可能说「18 岁」,如果你再去问一下「你今年高寿」,它很有可能回答「我今年 88 岁」,或者问你「芳龄几许」,它很有可能回答「小女子今年芳龄二八等等」。
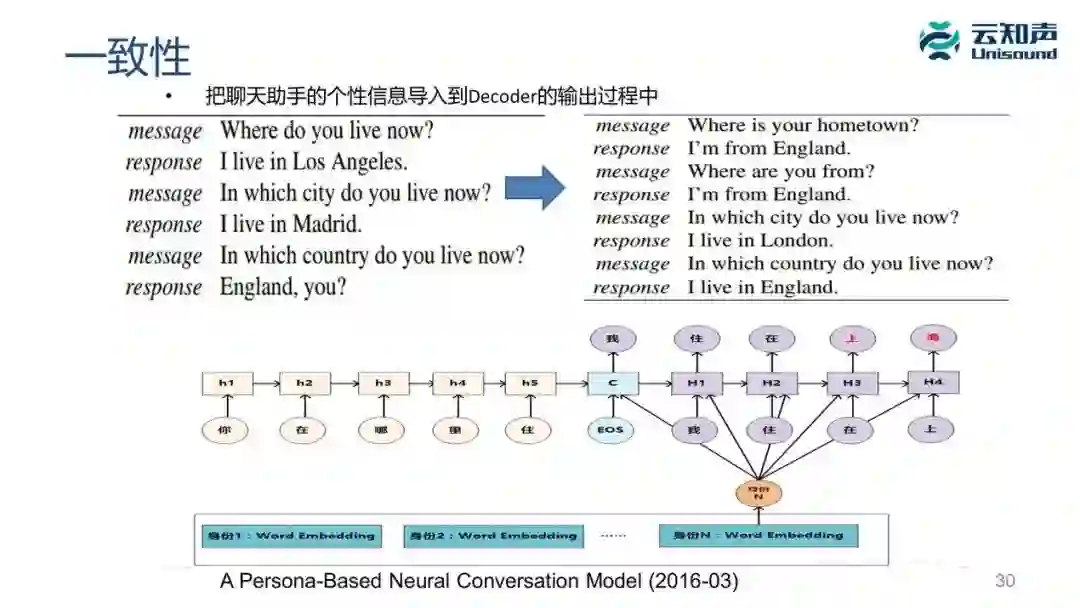
为什么会出现这种情况?因为目前聊天的机器人都是靠从各个来源去收集各种语料堆在一起的,对这种语料并没有做归一化处理,因为有的语料说「我今年 88 岁」,有的语料里面可能说「我今年 18 岁」等等,这时候换个方式问它可能会出现问答不一致的地方。更复杂的例子,你问它「你出生地在哪里?」它说「我在北京」,然后问它「你是中国人吗?」它可能就回答不了,虽然人类常识知道北京属于中国等等。
在深度学习里如果想把这些所谓的机器人的信息,进行建模或向量化处理导入到 decoder 模型里去,这时候它会优先从身份信息的词向量去生成应答,这样也能达到一定一致性的效果。
3. 融合知识

另外,做问答的时候,像我们这个例子问「姚明有多高」,我们生成比较自然的问答,说「他是两米二六,他是唯一一个可以从太空看到的人类。」当然,这是开玩笑的。这种聊天就融合了知识,它知道姚明的身高。这时候通过深度学习模型做 decode 时,除了生成常规的应答之外,有部分的应答还要从知识库里去检索,然后再把这个应答跟文本的应答拼在一起。

更多的类似工作可以看看获得今年IJCAI杰出论文奖的黄民烈老师的工作。
(四)基于知识的问答
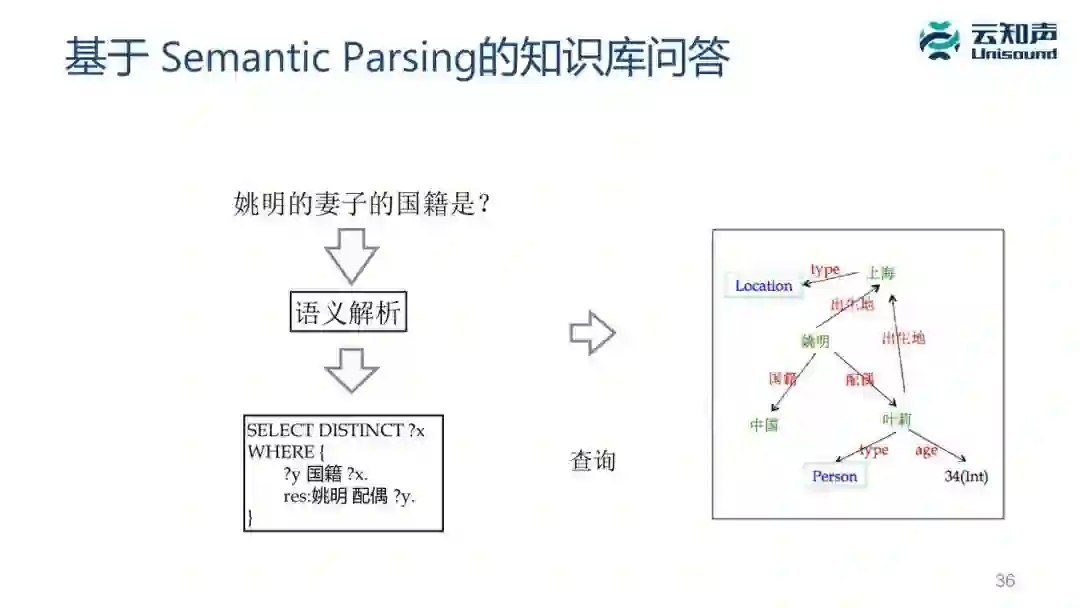
知识问答主要有两种方法:一种是基于 Semantic Parsing 的传统方法,它是把一个问题解析成一个形式化的查询语言,再把查询语言知识库里面做查询。这个方法的最大难点是把自然语言的问题转成这样一个形式化的查询语言。同样也有很多方法,最简单的基于规则、基于模板,复杂点的基于翻译模型、基于深度学习模型等。
目前学术界比较多的是基于机器学习的知识库的问答方法,这里面它的基本思想是把问题建模成一个 embedding,然后对知识图谱也做 embedding,变成一个个向量,这个问答就转换成了一个相似度匹配的问题,把知识库里的子图的向量跟问题对应子图进行相似度匹配。
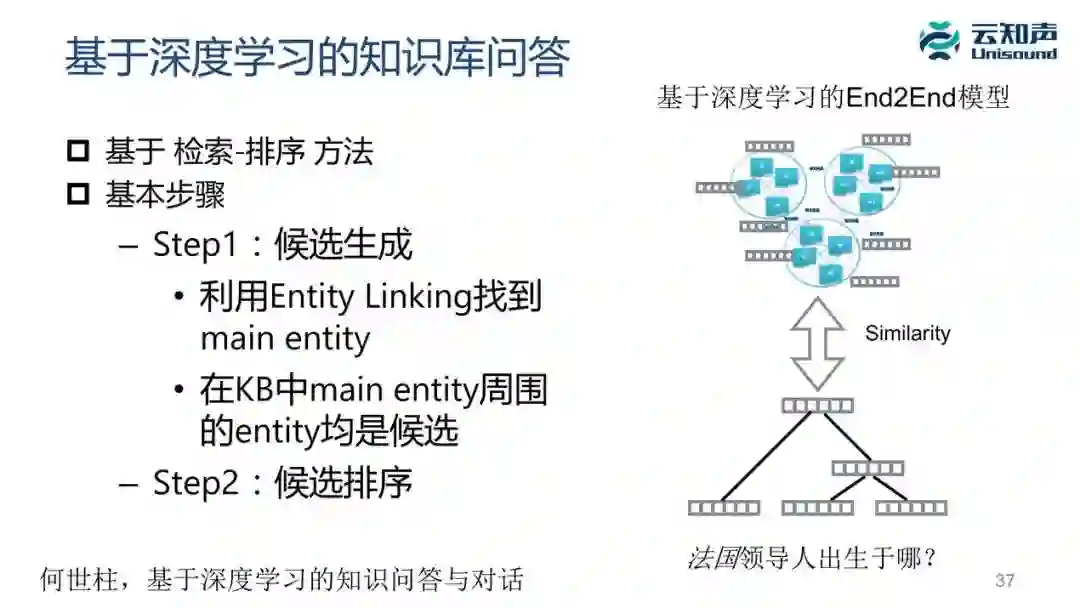
还有很多其他方法,目前比较多的是基于网络的方法,基于带注意力机制的循环神经网络的方法。这块我给一个参考,大家可以看一下《揭开知识库问答 KB-QA 的面纱》这篇文章,讲得非常详尽、非常好。我个人的观点是现在基于深度学习的知识库问答目前在工业界这块不是很成熟,它的效果不太可控,我们在系统里还是用基于传统的 Semantic Parsing 问答。
在 CQA 上也有很多把知识结合进去的方法。CQA 最核心的问题是我们要算用户的问题和在我们问答库里问题的语义相似度,这里的核心问题是怎么能把知识放到对句子的向量表示里。最近的 SIGIR2018 中提到,把知识和注意力的神经网络结合在一起的方法。现在这种论文基本都是一个网络图。另外一篇文章也是类似的,总体是在文本做排序时把知识向量化。
(五)基于知识的主动会话
这个实际上是非常关键的。在我们人机对话系统,特别是在 VUI 交互下, VUI 音箱是没有界面的,这就意味着你无法知道这个音箱到底支持哪些功能。当你面对音箱的时候,你怎么知道它的功能,到底哪些话能说,哪些话不能说,或者它有什么东西?这时候很需要机器人主动的对话,能引导用户用它,知道它的功能。
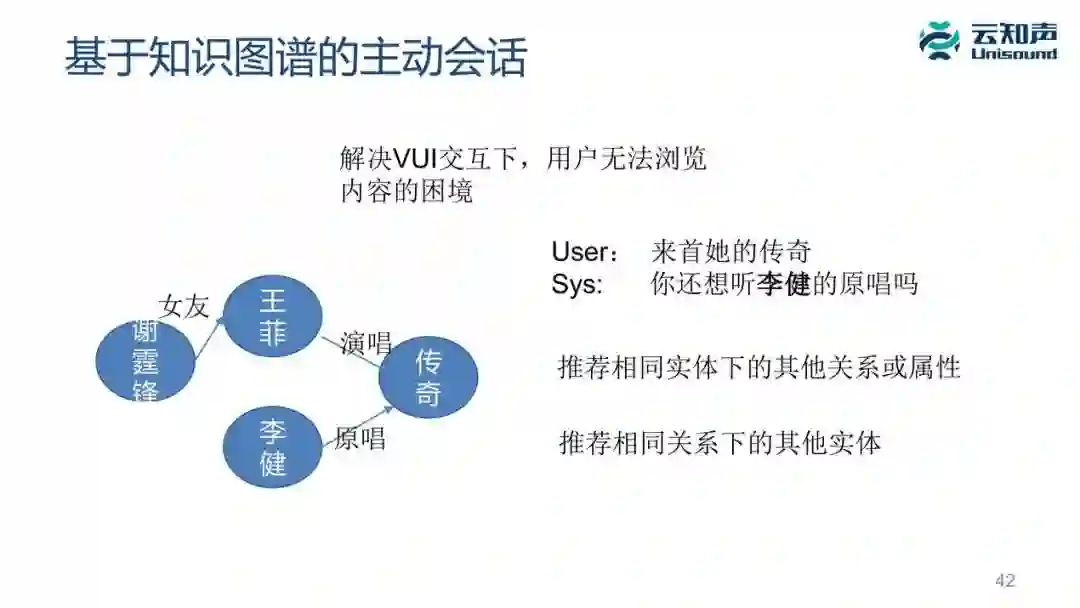
再举个例子,如果一个用户说「来首《传奇》」,机器可以主动问他说「播放以后还想听听李健原唱吗?」其实它的思想很简单,就是根据我们的知识图谱里面,看看相同实体下面有没有其他关系或者属性,或者推荐一个相同关系下面其他的实体。
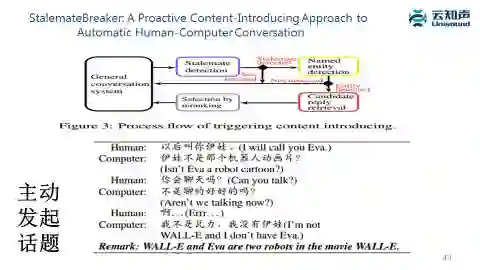
这里一篇百度的文章思想也是类似的,如果觉得聊天聊不下去了,会先在上下文里去做实体分析和实体链接,找到作为聊天主题的实体之后再根据知识图谱找相关的实体,根据相关的实体产生话题。
▌四、总结
前面把聊天、问答、对话、语义解析怎么跟知识结合起来做了简单的介绍。接下来做个总结:
第一,为什么人机对话系统很重要?

1、它有可能成为物联网时代的最主要交互形式,类似于 OS。
2、知性会话的核心是知识图谱。它最重要的是做两件事情:一是线下要做基于知识图谱做多源数据的融合,二是在服务时要做基于知识图谱聊天、问答、对话、操控一体化。
3、从技术上来讲,深度学习和知识图谱技术的结合是目前最重要的一个趋势。我个人比较看好 Sequence-to-Sequence 模型,因为它的表达能力非常丰富,而且应用场景非常多,基本上自然语言处理里面大部分的问题都可以建模成一个 Sequence-to-Sequence。包括我们的翻译是一个语言到另外一个语言,还有聊天问答甚至拼音输入法,就是把拼音序列转成文字序列等等,还有做分词、词性识别、命名实体识别等等都是 Sequence-to-Sequence,这种模型分为 encoder 和 decoder 两个阶段,它在不同的阶段都可以把一些知识融合进去。
第二,在人机对话系统里的技术演进是怎样的?
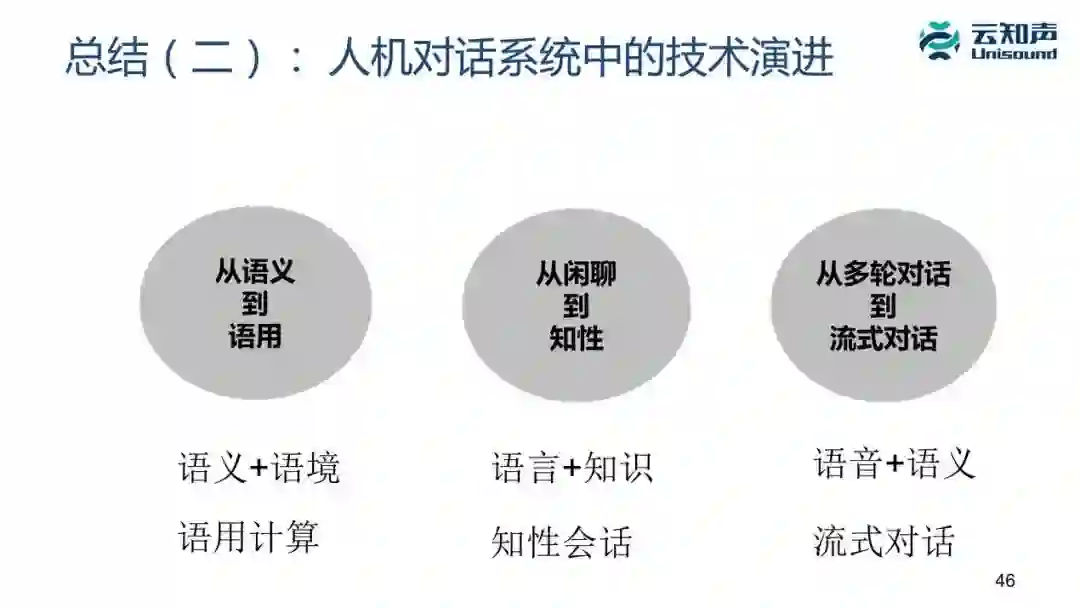
1、在对话里不能只看语义,还要看语用,语用就是「语义+语境」。
2、我们不能只做闲聊式的机器人,而且是希望我们机器人是掌握领域知识,它是有文化的,而且文化水平还很高,是个领域专家,是知性会话。
3、流式对话。我们目前跟音箱的交互都是先唤醒,说「小爱同学,给我点首歌」,又说「小爱同学,播放下一首」。非常麻烦,但人和人对话是不会总频繁叫人的名字的,这时候就需要流式对话,这块的技术难点是怎么判断一个人说话是不是说完了,你是否可以打断,这是目前技术上最难的一点。还有一个是怎么去拒绝噪音,因为现在对话是没有唤醒词的,这时候旁边人的说话甚至电视里面说的话很有可能被误识别,机器也会对它做响应。
▌五、答听众问
Q:我们公司在构建电商的知识图谱,但是电商的数据是每天都会更新的,有什么好的办法对知识图谱进行更新吗?而且基于 neo4j 的图谱如何做知识推理?
A:这是个好问题。我们刚才强调知识图谱要敏捷构建,敏捷构建就意味着你可以频繁的发版本,这时候就有版本合并的问题,其实也是更新的问题。更新这块主要的技术是知识本体的融合或者知识实体的匹配、实体的对齐。如果更新的数据量不是很大的话,我建议的方法是先通过实体对齐的技术,把更新的数据自动添加到知识图谱里去,如果量不大的话还需要做人工的 review,看更新的数据是否 OK。这个我认为也没有什么特别好的办法,因为更新本来就是知识图谱里最难的问题。
neo4j 的图谱如何做知识推理?首先,我个人认为它不太适合存储海量的知识图谱,电商的数量应该很大的,这时候用 neo4j 合适不合适还有待商榷。如何做知识推理?我们一般认为知识图谱最主要的是知识,尽量少去做推理,因为推理是挺难的一个东西,而且也没有特别工业化成熟度很高的工具。第二,如果非要做推理的话,我们一般做线下的推理,就是预先把推理做好,把它能展开的数据全展开,也叫「知识补全」,就像简单的传递性的关系或者预先把它都展开,相当于存储空间换时间,这是一个比较常用的方法。我们现在不太建议线上服务时做实时推理,因为那个性能一般很难达到要求。
Q:本体构建的大致方法能简单介绍一下吗?
A:本体构建的方法从大的面来讲有两种,一种是传统基于专家的方法,就是请一般专家全手工构建,他们对每个词、每个实体、词之间的关系都开会讨论,最后决定应该这样、应该那样,这是专家驱动的方法。但这种方法已经不太可行,而且这种方法也会成为我们做知识图谱的瓶颈,因为我们期望知识图谱是一个敏捷构建的。
目前大部分是数据驱动的方法,就是我们通过数据挖掘去自动构建知识图谱,适当地基于人工的 review。我倾向于极端的方法,我推荐的方式是知识图谱的构建整个是全自动,但是也需要专家的参与,但是专家参与不是做 review、不是做构建,而是做评测。整个知识图谱的效果根据应用的效果说话,这个应用不能假设整个知识图谱是完全正确的、完整的的。我们可以通过快速迭代,不断的对知识图谱去做更新,然后根据自动化的测试或者根据人工的抽样检查和应用的效果去看知识图谱的质量。只要我们知识图谱的质量能够满足应用的需求就 OK。
Q:实体抽取有一个大致的最佳实践吗?
A:最佳实践是这样的,如果从工业界角度看的话,实体抽取肯定是多个方法的融合,基于词典、基于规则、基于统计学习方法、基于深度学习方法,没有一个方法就能搞定所有的问题。虽然词典挖掘这个东西没有技术含量,但是实践中基于词典的方法是非常有效的方法,特别是在垂直领域里面,像医疗这种领域,当然,在有些领域可能这个方法不靠谱,比如在音乐领域,音乐里面有歌名,任何一个词都可能是歌名。
但基于词典方法还有一个重要考虑,一定要考虑这个词典的这个词有没有歧义,或者一个词的先验概率。比如「我爱你」也是一首歌名,但是它是歌名的概率可能不是特别大,但「忘情水」是歌名的概率就很大,所以词典不是简单的词条列表,而是要带先验概率的信息。
Q:知识图谱还需要语义网的知识吗?构建 OWL 可还需要很强的领域知识?
A:我们刚才说到知识图谱的前身是语义网,所以如果想更加深刻理解知识图谱,还是要了解一下语义网的知识,特别像 RDF OWL 的规范是要了解一下的。
OWL 的这个本体语言还是有点偏复杂,目前基本上不太推荐知识图谱搞得那么复杂,基本对应到 RDF 那种形态就差不多了。我们希望知识图谱可以构建尽量大,但是它从逻辑上来讲尽量简单,不要用 OWL 里面复杂的东西。一点点语义可以走得很远,没必要把模型搞得太复杂,因为把模型搞得太复杂的一个最重要难点是当你把实体放进去时你很难判断这个实体属于哪个概念。
Q:心理学出身的研究者在 NLP 学术领域是否有竞争力?对于心理学研究者转向 NLP 学术圈有哪些建议?
A:这个问题挺有意思的。我们组里有一个主力骨干就是学心理学出身的,但他当时学的心理学是偏统计方面的心理学,也就是计量心理学这方面的,所以他相对有一定的统计基础。这时候由统计基础转向到 NLP,因为有数学基础,是比较容易一点的。另外一点,心理学比较有意义的是认知这一块,因为神经网络这些原理跟认知心理学有一定的关系,所以心理学知识对转到 NLP 挺有帮助的。
关于具体的建议,不管哪个专业转到 NLP,最重要的是学好数学和机器学习最基础的东西,这个基础打好了,转向 NLP 就比较简单了。
Q:基于知识的方法和统计类的方法需要共融互补,老师有没有典型的合作思路,充分利用基于知识规则方法的稳定可控的同时,又能利用统计从有监督的大数据自动抽取模式?是否可以讲讲两者一起 NLP 的经验?
A:现在人工智能主要是三大学派——知识图谱派、统计学习派、深度学习派,从工业界角度来看,在解决具体问题时各有所长,所以需要把这三者融合在一起,真实的线上系统不会只有一个方法。所以知识方法是一个很重要的方法,而且它跟深度学习是有比较好的互补性,特别是可以提供深度学习方法里面没有的可解释性这一块。
具体怎么融合,最简单的融合方法就是做模型Ensemble,把几个分类器组装在一起,这个可以看周志华老师那本「西瓜书」,因为周老师做模型的 Ensemble是最拿手的。
此外,把知识或规则都可以作为特征,从这个角度融合在一起。另外,深度学习里的解码器也可以把知识融合进来,所以这块的方法是很多的。
【完】
2018 AI开发者大会
◆
只讲技术,拒绝空谈
◆
2018 AI开发者大会是一场由中美人工智能技术高手联袂打造的AI技术与产业的年度盛会!是一场以技术落地为导向的干货会议!大会设置了10场技术专题论坛,力邀15+硅谷实力讲师团和80+AI领军企业技术核心人物,多位一线经验大咖带你将AI从云端落地。
大会日程以及嘉宾议题请查看下方海报
(点击查看大图)


点击「阅读原文」,查看大会更多详情。2018 AI开发者大会——摆脱焦虑,拥抱技术前沿。