技术动态 | Neo4j知识图谱的技术解析及案例分享
转载公众号 | DataFunTalk

合作分享:Jesus Barrasa-Neo4j-欧洲区售前和技术总监
合作分享:丁可-Neo4j-亚太区高级技术顾问
编辑整理:吴祺尧-加州大学圣地亚哥分校
出品平台:DataFunTalk
导读:Neo4j近年来与众多公司合作,在很多领域中成功结合知识图谱技术,使得知识图谱顺利落地于各个项目中。今天由 Neo4j 的欧洲区售前和技术总监Barrasa博士来介绍知识图谱的技术解析与案例分享。
今天的介绍会围绕下面五点展开:
数据架构中的知识存在于何处
知识图谱在技能发现中的应用
知识图谱在元数据管理中的应用
知识图谱在语义搜索中的应用
总结
01
数据架构中的知识存在于何处
首先,我使用一个问题作为开场:在数据架构中知识存在于何处?我会使用一个金融领域的例子来帮助大家理解知识图谱的概念,并使得大家可以将知识图谱推广到其他领域中。
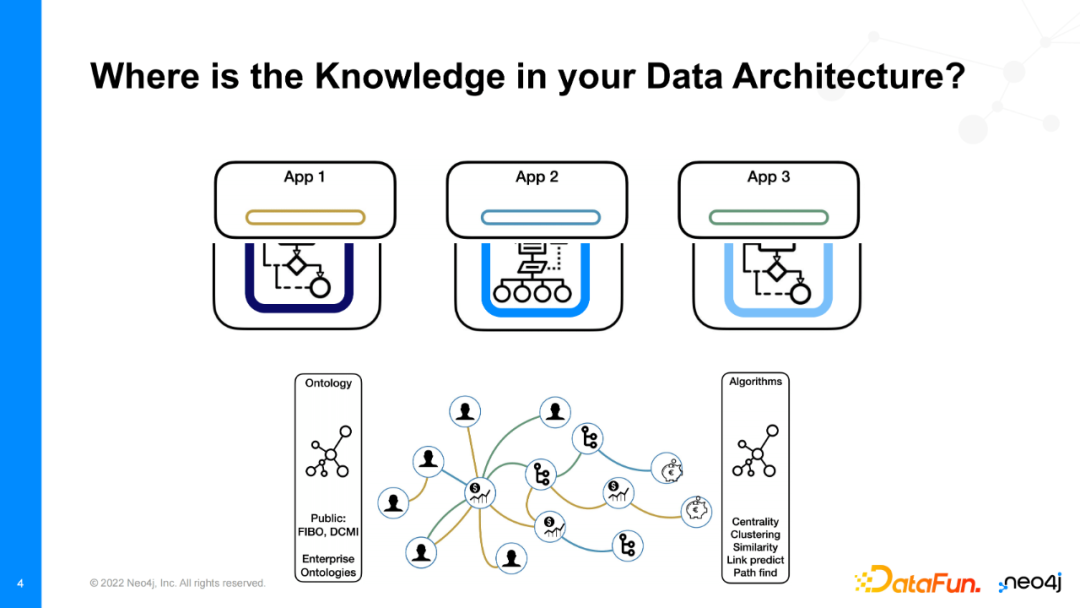
数据的来源与种类十分多样。我们可能会有顾客数据、产品数据、顾客行为数据,它们可以有很多存储方式,下面我以关系型数据库为例进行介绍。通常情况下,我们会有很多应用来消费、处理、理解这些数据。比如,有一个用来生成dashboard的“App 1”,它可以用来生成给上级主管查看的报告,那么这个app会查询数据库,结合顾客数据和顾客行为数据,自动输出一份由顾客账户为索引的总结。在这个app中,知识存在于那些可以用于处理、理解数据的代码中。它们往往是上百行SQL语句。又比如我们还有另一个应用“App 2”,它用于向顾客推荐需要升级的产品。具体地,它会结合顾客数据、顾客行为数据、产品数据等来向顾客推荐潜在的升级产品。相似地,应用决定了数据的意义,那么知识就存在于这一具体应用中。综上,我们可以发现数据的存储与知识是解耦的。上述范式可以重复运用于所有应用中,比如我们还可以有一个“App 3”,它生成一个可以用来监管的报告。
但是,这种解耦的知识存在形式像一个黑盒,对于我们来说很难去维护。所以,我们可以使用知识图谱使得我们的数据更加“聪明”,让业务逻辑与数据的联系更加紧密。
首先,我们使用图结构,将业务与数据的联系显式地用边来表示。在构建完知识图谱后,我们将它赋予实际的语义,覆盖在业务的本体之上。通过这种方法,你可以结合自己领域的知识,使用各类的图算法来使得知识图谱生成新的数据或知识,最终实现图谱与实际应用的紧密结合的目的。知识图谱带来的另一个好处在于你的下游应用会更加轻量化,这是因为原先很多需要处理的逻辑交给了知识图谱进行解析。

知识图谱由两部分组成。首先,知识图谱中存在大量数据。其次,知识图谱中包含很多显式的知识,它可以使用现有数据来生成新知识或者新数据。知识可以有多种存在形式,如本体、分类、算法、Cypher规则等。总的来说,数据和知识的组合形成了“智慧”的知识图谱,而知识图谱保证了知识和数据可以更加容易地进行存取操作。
02
知识图谱在技能发现中的应用

很多著名分析家,如Gardner强调了技能发现的重要性。他指出超过53%的公司“技能发现”的短板阻碍了业务转型,因为他们无法识别新业务中员工所必需的技能,从而无法有效利用公司中的人力资源。Neo4j曾经与DAIMLER合作,使用知识图谱成功地将技能发现运用于公司员工中。具体地,他们想要找到公司在哪些技能方向上缺少足够的优质员工,并试图在公司内部找到最能胜任那些空缺职位的员工。此外,他们还想要为公司员工制定一套最佳的职业规划路线,使得员工可以最大化地激发自己的潜能并合理地运用自身所含技能。
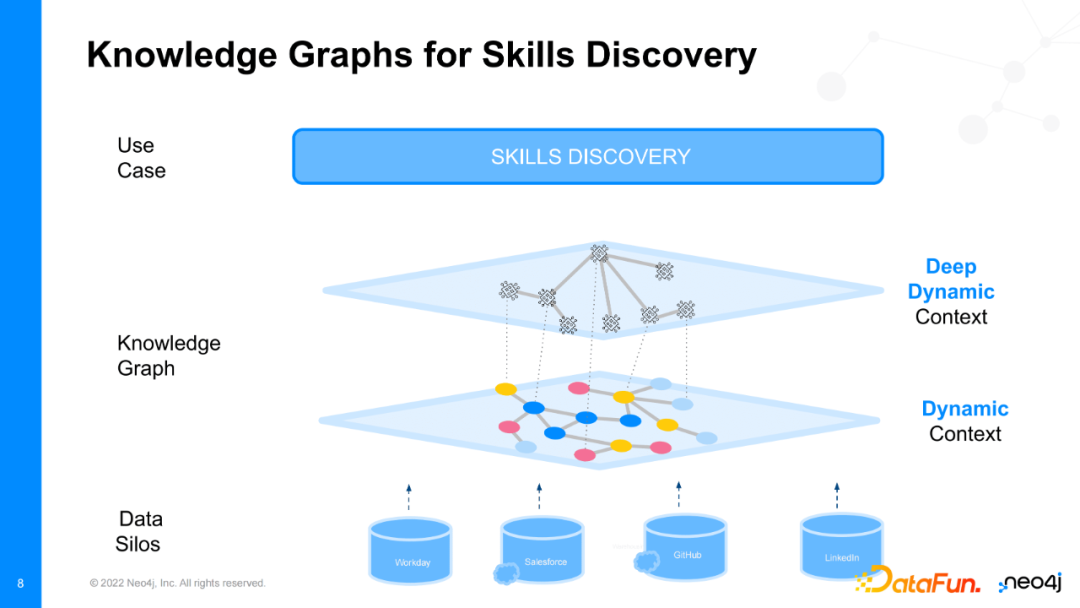
当然,他们最初没有足够的能力去找到这些问题的答案。所以,他们决定使用知识图谱的方法,在更高的维度收集员工数据,并构建一张图。知识图谱中覆盖在图上,包含领域知识信息如领域内技能的分类等。通过将知识融入图结构的做法,我们可以回答之前无法解答的复杂问题,如技能发现。
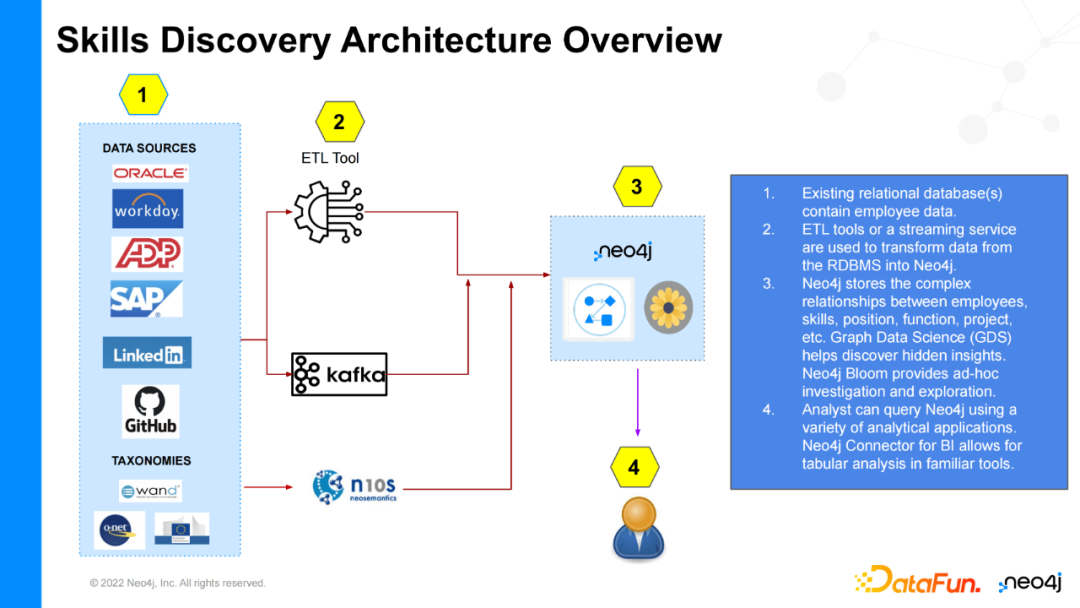
具体地,我们首先在很多平台中收集如员工信息、员工劳动力信息、资源管理信息、HR平台、员工培训信息等数据。Neo4j根据数据的动态属性使用传统的ETL工具、最近很流行的kafka流式数据处理中间件来处理、构造知识图谱。进一步,知识图谱可以根据实时更新的数据动态地调整图结构,并将产出的知识图谱显式地覆盖在领域的本体上。此外,Neo4j支持owl、rdfs等各种语言,将关系型数据库中的数据融入Neo4j框架中。最终,通过构建的知识图谱与企业自身设定的模式,我们就可以回答如元数据相关或者数据的知识相关的查询、推荐问题。
03
知识图谱在元数据管理中的应用
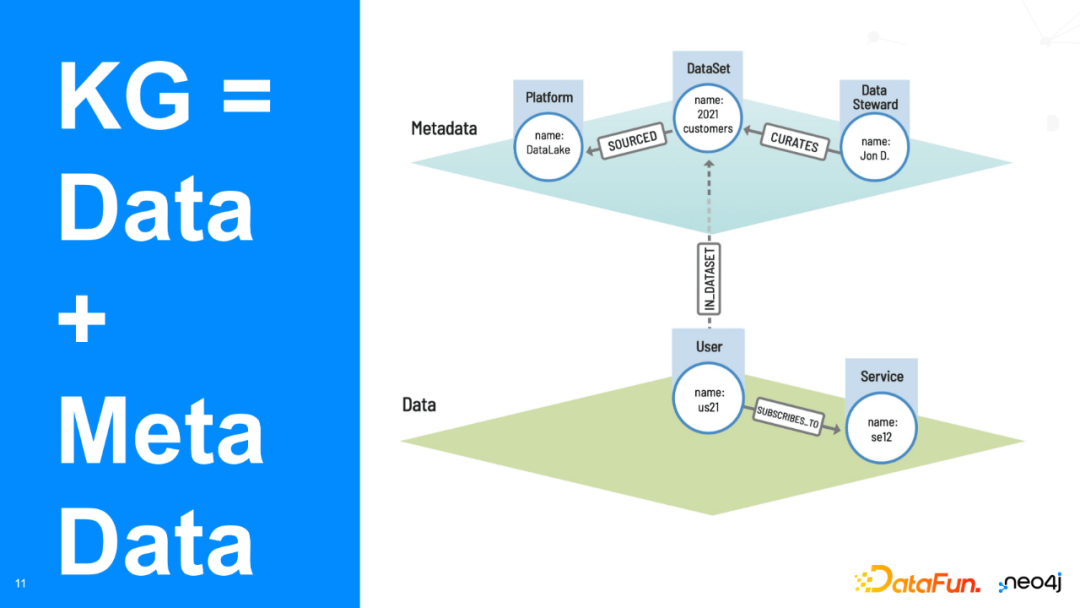
第二个案例是关于知识图谱在元数据管理中的应用。元数据不仅包含数据本身的信息,还包括了如数据集的来源、数据源所在平台等上层信息。所以,元数据信息相当于为数据加上额外一层血缘关系,是“数据的数据”。当我们想要将数据展示给潜在数据消费者,如一个团队的新成员时,那么元数据这类包含数据类型、数据最近版本的信息就变得极为重要。
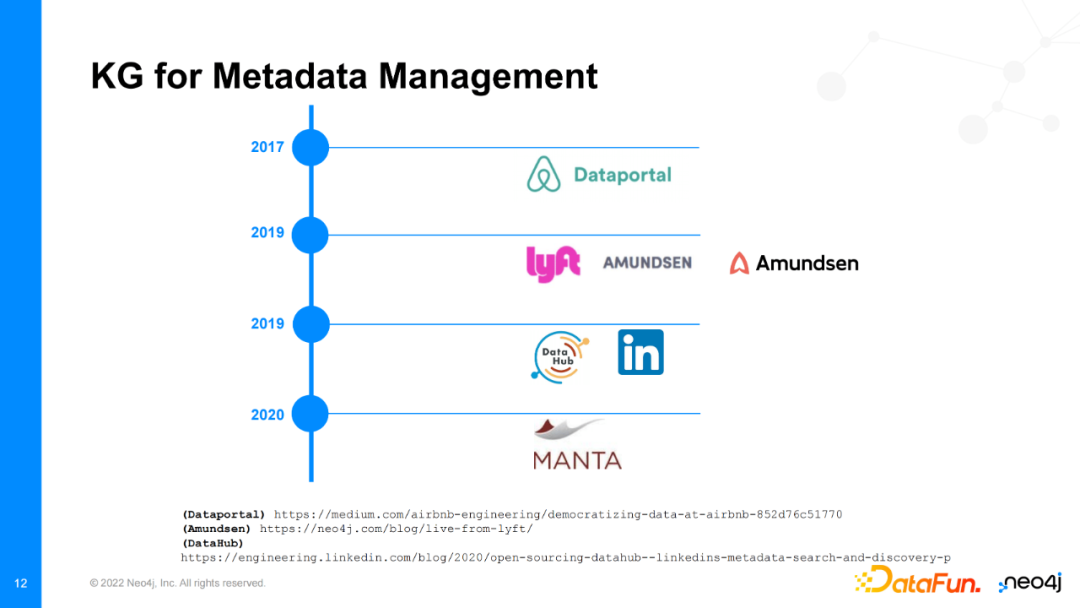
很多大公司慢慢意识到元数据管理可以使用知识图谱来解决。他们近年来都在Neo4j图数据库的基础上构建了自己的元数据管理平台。最初,Dataportal率先搭建了自己的datahub,后续如lyft、Amundsen、LinkedIn和最近的Manta都创建了自己的常用知识图谱元数据管理工具。
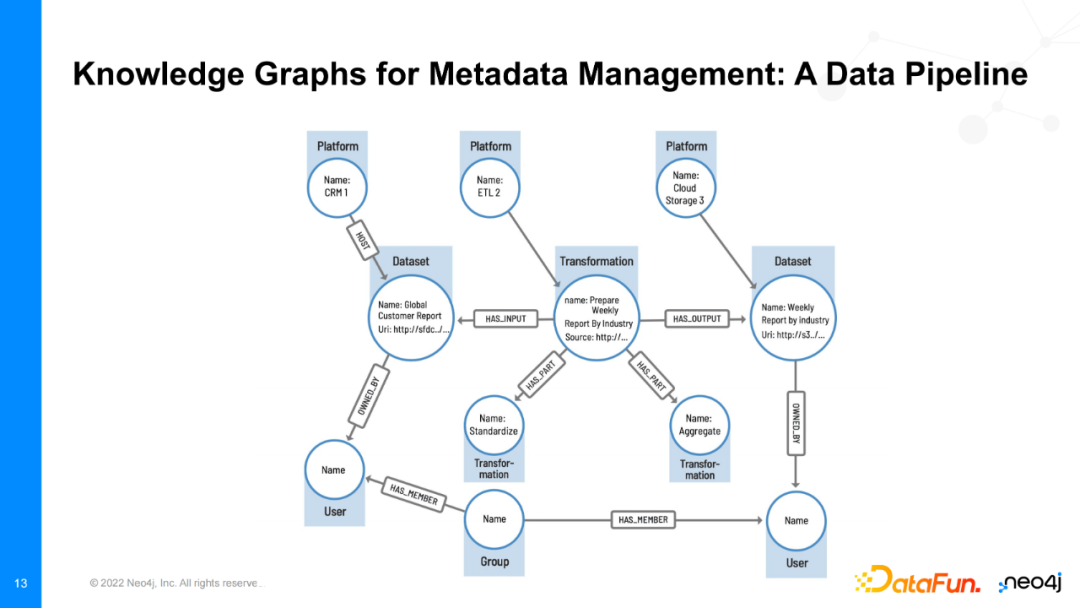
元数据管理的维护依赖数据处理pipeline,它不仅建模数据本身,还建模数据的变换方式、使用方式等。具体地,元数据管理可以让我们查看一组数据在处理pipeline中是如何通过一系列数据变换如聚合、组合等,生成一组输出数据。数据本身与很多实体相连接,例如它们所在的数据平台,数据变换的创建者、维护者,数据的时间信息,数据的最近修改时间、数据的使用频率等。每个部门都可以建立并维护自己的数据pipeline。最终,当我们将元数据知识图谱构建完毕后,我们就可以处理如数据pipeline出现故障时的问题排查,因为我们可以通过检查pipeline中数据的处理流程中可能受故障影响的环节来达到目的。总而言之,只要你能将元数据信息构建成一张知识图谱,你就有能力使用如Cypher等语言回答各种复杂问题。
04
知识图谱在语义搜索中的应用

最后,我来介绍一下知识图谱领域最被广泛使用的应用:基于知识图谱的语义搜索。很久之前,我们在网站进行搜索时,我们只是寻找与query匹配的关键词所在的文章或网页。现在,我们要求搜索引擎可以理解query的语义信息。
之前NASA也遇到了这类问题,因为它们的数据库中包含海量的文档、报告、项目数据、经验教训、研究成果等。之前,NASA的搜索方式使用关键词匹配,而这类忽略上下文信息与语义信息的搜索方法十分低效。

NASA的解决方案是利用知识图谱与自然语言处理技术来处理这些海量文档。首先,自然语言处理中的实体抽取任务可以将实体表示为知识图谱上一个显式的图节点。当我们建模文档中的所有实体,并结合元数据信息以及领域先验知识如领域分类信息、领域知识表达等,我们可以将实体节点按照自己的范式进行连接,构成一张包含丰富领域知识的图谱,进而使得我们可以从一个节点游走到另一个节点,从语义层面回答query。
例如,你想要查询自己感兴趣的话题,那么通过知识图谱上的游走我们就可以找到与话题语义相关的多个文档,并将这些你可能感兴趣的文章推荐给你。
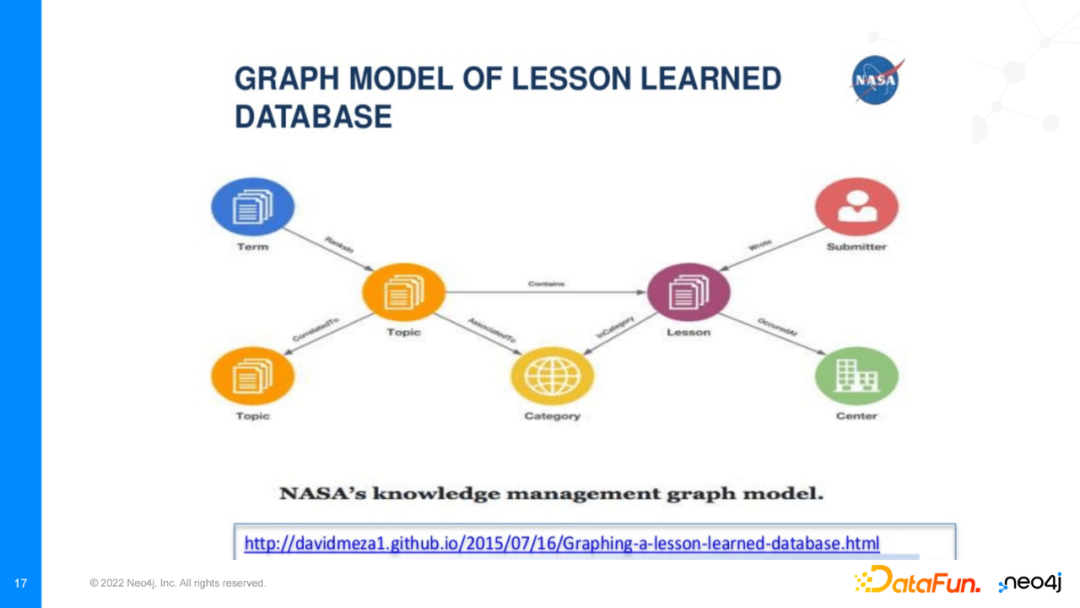
具体地,NASA不仅将经验教训、文档、URL等映射为知识图谱上的节点,还使用表示学习将文档的主题、实体词建模并映射至知识图谱中,并将它们与对应的文档相连。通过这一做法,query查询可以充分利用语义相关信息,使得搜索更加高效。
05
总结

最后,我对今天的分享进行总结。
首先,知识图谱可以使得我们的数据根据我们的下游应用变得更加“聪明”,进而使得数据和应用的联系更加紧密。它可以根据我们使用数据的目的来构建合适的、包含语义信息和知识信息的图结构,覆盖在原有数据之上。应用知识图谱的最佳实践是:找到自己应用数据的目的,构建正确的语义知识图谱,从小型图谱开始逐渐扩大图的规模。
总而言之,由于GraphQL只是一个数据接口语言,它无法进行复杂的图查询,因此Cypher更适用于图遍历和复杂图查询的场景(它和图数据库结合得更紧密),而GraphQL适用于存取数据。
06
Q&A
Q:GraphQL和Cypher分别在什么情况下使用是最好的?它们可以一起进行使用吗?
A:GraphQL提供了标准的图数据库接口。如果前端的开发和数据库管理人员想要进行解耦,那么GraphQL是一个不错的选择,因为它可以建立自己的API,使得后端的任何变动都不会影响前端的业务开发。Cypher需要嵌入图数据库中,它适用于当图数据库需要进行大幅度的升级的情况,这时内部的Cypher代码需要进行相应的调整。总而言之,Cypher更适用于遍历的场景(因为它和数据库结合得更紧密),而GraphQL适用于存取数据。另外,由于GraphQL是一个图数据库的接口语言,它无法像Cypher一样进行复杂的图数据查询。
分享嘉宾:


OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。