最近,百度 ERNIE 再升级,发布持续学习语义理解框架 ERNIE 2.0,该模型在共计 16 个中英文任务上超越了 BERT 和 XLNet,取得了 SOTA 效果。在ERNIE 2.0 预训练模型耀眼光环背后的神助攻,正是源于飞桨(PaddlePaddle)长期产业实践积累的高效率GPU分布式训练能力。
![]()
(图片来自网络)
ERNIE 连续获得业界 SOTA 效果,离不开飞桨高性能分布式训练引擎提供的强大支撑。举例来说,在计算复杂度较高的深层 Multi Head Self-Attention 结构和成本较低的海量无监督的中文预训练语料,数据量和算力需求都是超乎想象的,不仅要求我们拥有大量高性能计算芯片,还要有非常强大的分布式训练能力。
1. 分布式训练的本质目的:
提高迭代效率与降低训练成本
深度学习模型的效果迭代对训练速度非常敏感,能够带来高性能并行训练的深度学习框架是实际开发和应用的刚需。
相同的硬件设备数,高效率的分布式训练,可以大大缩短产品迭代周期。而在受限的时间要求下,高效率的平台型工具也可以显著减少硬件需求。时间的节省和成本的降低,毫无疑问值得企业重点关注。
飞桨,源于产业实践的深度学习平台,既是来源于产业实践,又是服务于产业实践。
一方面,从实际业务需求出发,面向百度海量的业务数据进行深入优化,并做通用化设计嵌入框架。经过百度大量业务场景的反复打磨,形成一套满足工业级业务需求的深度学习框架。
另一方面,在已有业务实践的基础上,飞桨又会进一步服务于新的业务以及人工智能前沿领域的探索中,不断优化整体研发速度。ERNIE 的不断创新与多机多卡训练的迭代效率密切相关,相关的基础能力正是源于飞桨对于自然语言处理或视觉任务高效支持的积累。
当前,Paddle Fluid 1.5 版本面向开发者开放更多更强大分布式训练能力:包括通用场景下的高扩展性并行组件,以及面向特殊场景的定制化并行训练组件,并通过 High Level API Fleet 面向社区用户提供分布式训练方法。
2019 年 7 月,飞桨发布了 Paddle Fluid 1.5 版本,面向通用 GPU 多机多卡场景的训练,为用户带来了更多新的特性,训练效率相比 1.4 版本有了大幅度提升。截至目前,飞桨团队在通信拓扑、通信内容、通信并发等方面实现了多项业界主流的加速技术,并形成灵活可配置的 Operator。开发者可以通过多种不同 Operator 的组合形成组合优势,全面提升并行训练的加速能力。
(1)多种通信拓扑的支持:(Ring-Topo、H-Topo)
支持多种通信拓扑结构,ring based allreduce,hierachical allreduce 等,在不同的节点范围,用户可以定制不同的通信拓扑,灵活提升性能。
(2)通信内容智能聚合:(G-Fuse、Auto-Fuse)
通过对模型参数梯度尺寸的分析,启发式地将梯度进行合理的聚合,可以使训练过程中遇到的较小的梯度进行汇聚,用相同的延时完成多个碎片梯度的通信。
(3)灵活可配置的通信并发:(Multi-Comm(Mc))
支持多流通信技术,能够将通信相关的 Operator 进行并发,进一步减小通信的整体时间。在计算与通信并发方面,通过在编译期对用户定义的计算图拓扑进行分析,可以找到通信 Operator 调度的合适时机,使通信与计算能够最大限度地重叠,从而提升 GPU 的整体利用率。
(4)组件化的 Collective Opeartor 设计
通过将通信组件 Operator 化,并在不同的并行算法下将用户定义的 Program 进行转译,插入合适的通信组件,使得用户、开发者和框架设计都得到了极大的自由度。
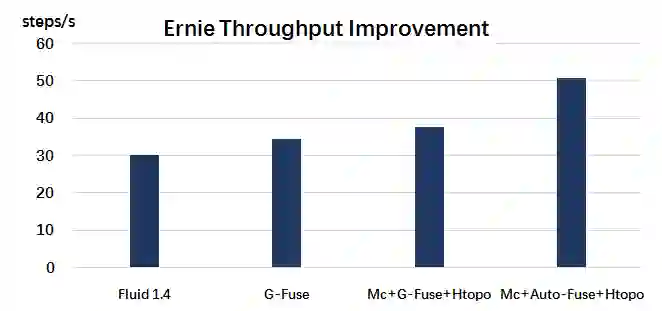
下图中比较了不同的优化方案组合给 ERNIE 带来的训练性能的提升,相比与 Paddle Fluid 1.4 版本没有增加优化策略的基线,可以看到多种扩展性优化策略的组合带来的性能提升是十分显著的。
![]()
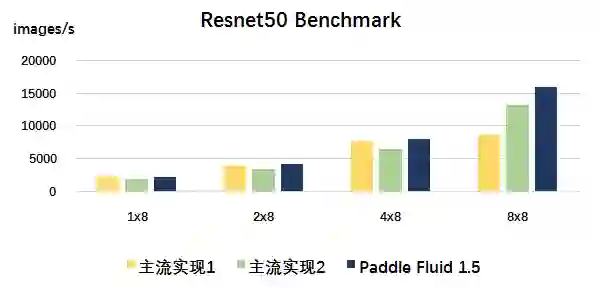
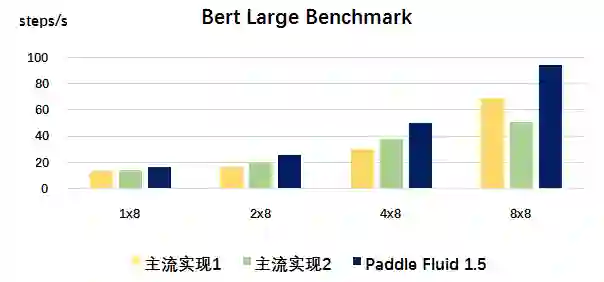
此外,基于最优优化策略的组合,我们以自然语言处理和计算机视觉两个领域公开可获取的经典预训练模型作为 Benchmark 进行对比。在扩展性方面,从结果可以看出,随着节点数目的增加,Paddle Fluid 1.5 在吞吐方面优势更加明显。在 8x8 v100 硬件条件下,Paddle Fluid 1.5 在不同任务下相比其他主流实现可以获得 20%-100% 的速度提升。
![]()
![]()
![]()
![]()
Paddle Fluid 1.5 除了面向一般场景提供的通用并行能力外,还针对特殊场景研发内建(Built-in)并行能力。
在公有云场景下,GPU 资源非常昂贵,如果用户的计算量很大,可以选择多机训练。但公有云环境 GPU 节点之间,由于调度或者资源碎片等问题通常会造成网络互联不是最优状态,网络的带宽相比大公司定制化的训练集群会有一定折扣。
针对这种高性能计算硬件、低配置网络环境的公有云场景,飞桨团队在 Paddle Fluid 1.4 版本就推出了以稀疏通信技术为主的并行训练方法,通过不断的累计本地梯度,同步最有代表性的少量梯度,在保证模型收敛的前提下可以将通信量减小为原始通信量的 1% 以内,大大降低了网络通信负载。
如下图所示,在带宽压缩到 1Gb/s 的情况下,通用的多机多卡并行训练方法的吞吐能力已经趋近于 0,而 Paddle Fluid 1.5 基于稀疏通信的并行训练方法依然可以保持较高的吞吐量
![]()
![]()
![]()
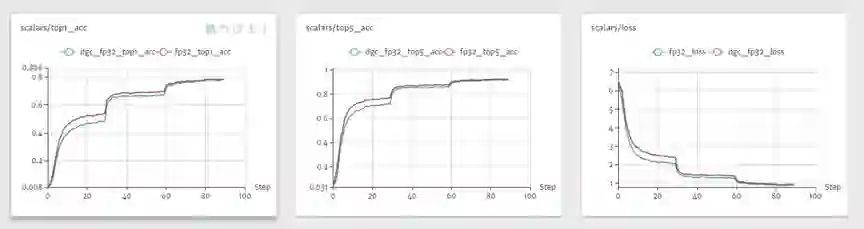
收敛效果:基于 Imagenet 数据集,Resnet50 模型的收敛效果在稀疏通信下与常规的并行训练方法没有损失,证明了稀疏通信训练方法的有效性。
![]()
2.3 简单易用的 High Level API——Fleet
从 Paddle Fluid 1.5.1 开始,针对分布式训练的易用性问题,飞桨团队推出 Fleet API 作为分布式训练的统一方式。Fleet 的命名出自于 PaddlePaddle,象征一个舰队中的多只双桨船协同工作。Fleet 的设计在易用性和算法可扩展性方面做出了很好的折衷权衡。用户可以很容易从单机版的训练程序,通过添加几行代码切换到分布式训练程序。此外,分布式训练的算法也可以通过 Fleet API 接口灵活定义。下面给出一个极简示例,方便读者感受一下 Fleet API 的易用性。
import paddle.fluid as fluid
def mlp(input_x, input_y, hid_dim=128, label_dim=2):
fc_1 = fluid.layers.fc(input=input_x, size=hid_dim, act='tanh')
fc_2 = fluid.layers.fc(input=fc_1, size=hid_dim, act='tanh')
prediction = fluid.layers.fc(input=[fc_2], size=label_dim, act='softmax')
cost = fluid.layers.cross_entropy(input=prediction, label=input_y)
avg_cost = fluid.layers.
(2)定义一个在内存生成数据的 Reader 如下:
import numpy as np
def gen_data():
return {"x": np.random.random(size=(128,32)).astype('float32'),
"y": np.random.randint(2, size=(128,1)).astype('int64')}
Collective Training 通常在 GPU 多机多卡训练中使用,一般在复杂模型的训练中⽐较常见,我们基于上面的单机模型定义给出使用 Collective 方法进⾏分布式训练的示例如下:
import paddle.fluid as fluid
from nets import mlp
from paddle.fluid.incubate.fleet.collective import fleet
from paddle.fluid.incubate.fleet.base import role_maker
from utils import gen_data
input_x = fluid.layers.data(name="x", shape=[32], dtype='float32')
input_y = fluid.layers.data(name="y", shape=[1], dtype='int64')
cost = mlp(input_x, input_y)
optimizer = fluid.optimizer.SGD(learning_rate=0.01)
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)
optimizer = fleet.distributed_optimizer(optimizer)
optimizer.minimize(cost)
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
step = 1001
for i in range(step):
cost_val = exe.run(program=fluid.default_main_program(), feed=gen_data(), fetch_list=[cost.name])
print("worker_index: %d, step%d cost = %f"% (fleet.worker_index(), i, cost_val[0]))
python -m paddle.distributed.launch collective_train.py
如果您想详细了解更多飞桨的相关内容,请参阅以下文档或点击
阅读原文
。
官网地址:https://www.paddlepaddle.org.cn/?fr=jqzx4
想与更多的深度学习开发者交流,请加入飞桨官方 QQ 群:
432676488
最后给大家推荐一个 GPU 福利 - Tesla V100 免费算力!配合 PaddleHub 能让模型原地起飞,扫描下方二维码申请~
![]()
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com