IMDB、烂番茄...哪家网站的电影评分更靠谱?(过年囤片清单)

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
我们在选择看哪一部电影时,通常会考虑很多个因素,比如导演是谁、演员是谁,或者电影的预算是多少。大部分人都是基于影评、预告片做出决定,或者直接根据电影的评分来决定。
出于某些原因,有些人不愿意看影评或预告片,尽管它们比评分提供了更多的信息。
首先,他们不想被剧透,哪怕是只有一点点的剧透也不行。
其次,他们不希望观影体验受到任何影响。因为影评里通常会包含剧照,这些剧照一旦映入人类的大脑中,他们就很难做到在观影时不受任何影响。
另外,有些人可能很忙或者很累,不想看任何影评,哪怕是 2 分钟的预告片也不想看。
所以,在大多数情况下,电影评分对于很多人来说似乎是最好的方案。
这篇文章旨在为大家推荐一个网站,能够准确、快速地获得电影评分,而且背后有强大的数据做支撑。
我们要做的就是以某些标准为基础,向大家推荐“能够获得电影评分最好的网站”,比如什么样的可以称得上“更好”,什么样的算“更差”或“最差”,什么样的是“最好”。在我看来,唯一可用的标准就是正态分布。
好的电影评分网站应该接近于正态分布,也就是说:在某段时间内给定一组值,大部分值位于中间,少部分值处于两极。正态分布(也叫高斯分布)看起来是这样的:
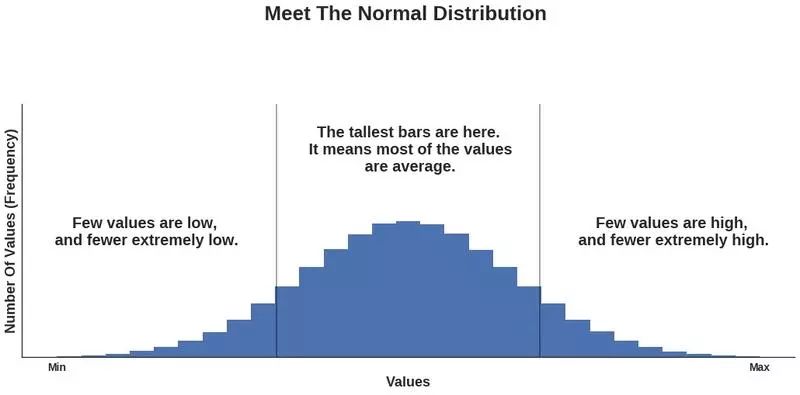
大部分评分处于平均区间,少部分很高或很低,这样的评分才符合正态分布。
这一标准背后的原理是什么呢?我看过几百部电影:
有些电影非常好,我看了好几遍。
有些电影很糟糕,我后悔花时间看它们。
大部分的电影处于平均水平,我甚至已经想不起它们的情节。
我相信大部分人——不管是影评家、影迷或者普通观影者——都有类似的经历。
如果说电影评分确实能够反映电影的质量,那么电影评分也应该符合正态分布。
既然我们看过的电影中大部分都处于平均水平,那么在分析电影评分时,也应该出现相同的模式。
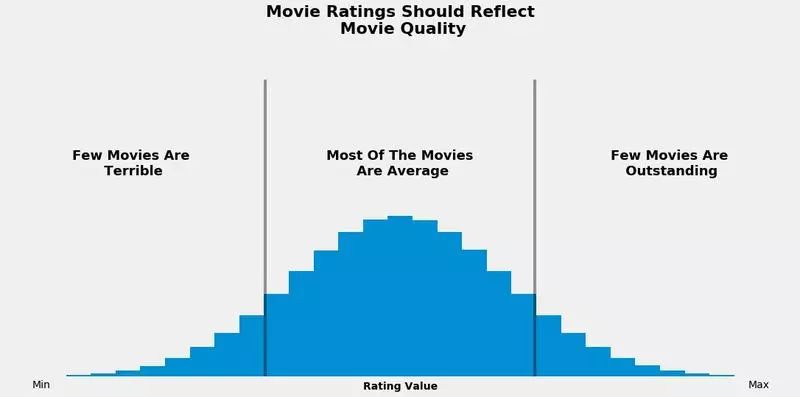
这里的每个长条与一个评分对应,长条越长表示电影评分越高。
如果你还不接受这两种模式之间的相似性,可以想想单部电影评分的分布情况。有很多人会对电影进行评分,而在大多数情况下,他们会做出类似的选择。他们要么觉得电影很差,要么一般,要么很好。
如果对单部电影的评分进行可视化,我们极有可能看到评分聚集在以下三个区域中的某一个:低分、平均分或高分。
因为大部分电影都处于平均水平,所以聚集在平均区域的可能性最大。
不出现聚集的情况是很少见的,也就是说评分在这三个区域平均分布。
因此,具有大量样本的电影评分的分布应该接近于正态分布,也就是平均区域出现聚集,两边的条形长度越来越低,最后收敛。
如果这些难以理解,可以看下面这张图:
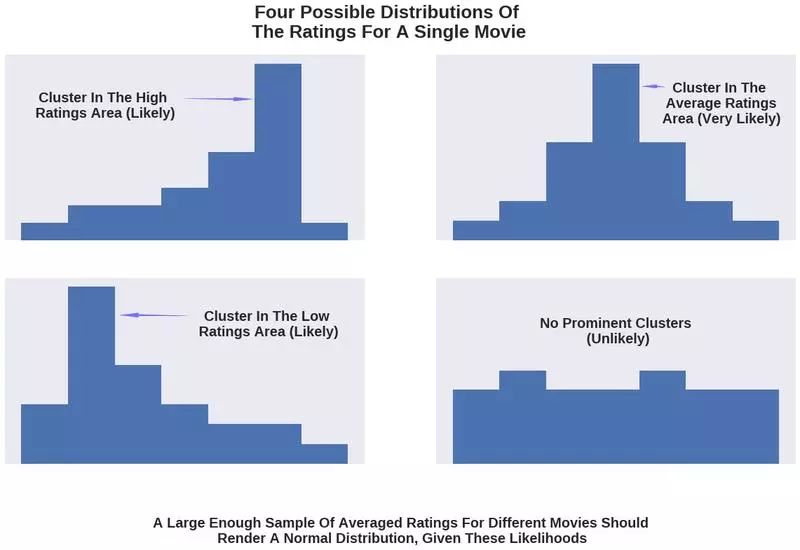
请注意“likely”和“very likely”之间的区别
在给定了标准之后,我们开始进入数据环节。
有很多网站提供了自己的电影评分。我根据它们的知名度从中选出了 4 个网站,分别是
IMDB(http://www.imdb.com/)
Fandango(http://www.fandango.com/)、
RottenTomatoes(https://rottentomatoes.com/)
Metacritic(http://www.metacritic.com/)。
对于后面两个网站,我主要使用它们的标志性评分——tomatometer 和 metascore,主要是因为它们对于用户来说具有更高的可见性(也就是说用户更容易看到它们)。这两种评分也会分享在另外两个网站上(IMDB 上有 metascore,Fandango 上有 tomatometer)。
我收集了在 2016 年和 2017 年拥有评论最多的电影,总共 214 部,可以从
GitHub(https://github.com/mircealex/Movie_ratings_2016_17)
上下载这些数据集。
我没有收集 2016 年之前的电影,因为 Fandango 的评分系统在 Walt Hickey 提出质疑之后做了些许改动,我会在后面做出说明。
首先,让我们来定义质量分数:从 1 到 10,0 到 3 分表示电影不好,3 到 7 分表示电影一般,7 到 10 分表示电影很好。
要注意质量和数量之间的差别。为了保持可辨识度,我把数量评级分为低、平均和高,而电影的质量用坏、平均和好来表示。
现在让我们来看一下分布情况:
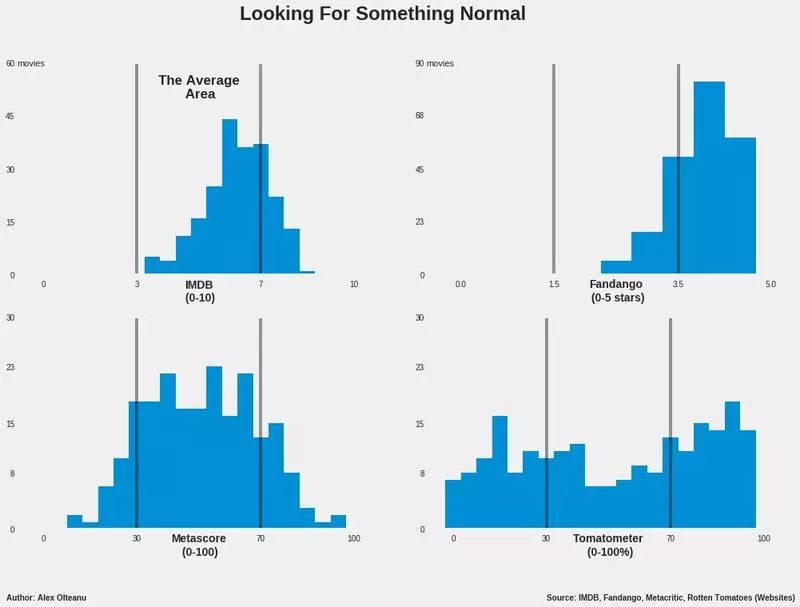
每一种评分都有其独特的地方。对于 IMDB 和 Fandango 来说,每条长条之间的相隔 0.5,而其他两个每条长条间隔 5。
乍一看,metascore 的柱状图更接近于正态分布,它的平均区域聚集了大部分的长条,这些长条的高度是不规则的,让整个图的顶部看起来既不钝也不尖。
不过,中间部分比两边高,而且比两边多,长条的高度向两边逐渐降低。也就是说,metascore 的大部分值处于平均范围,正是我们想要的类型。
IMDB 的大部分长条也分布在平均区域,但很明显向高区域倾斜,而低区域几乎是空的,所以这样的结果需要打个问号了。
一开始我把这种结果归咎于样本数据量太少,以为更多的样本可以让 IMDB 的结果更准确些。所幸的是,我在 Kaggle 网站上找到了一个数据集 (https://www.kaggle.com/deepmatrix/imdb-5000-movie-dataset),里面包含了 IMDB 网站 4917 部电影的评分。使用这个数据集得出的结果如下图所示:
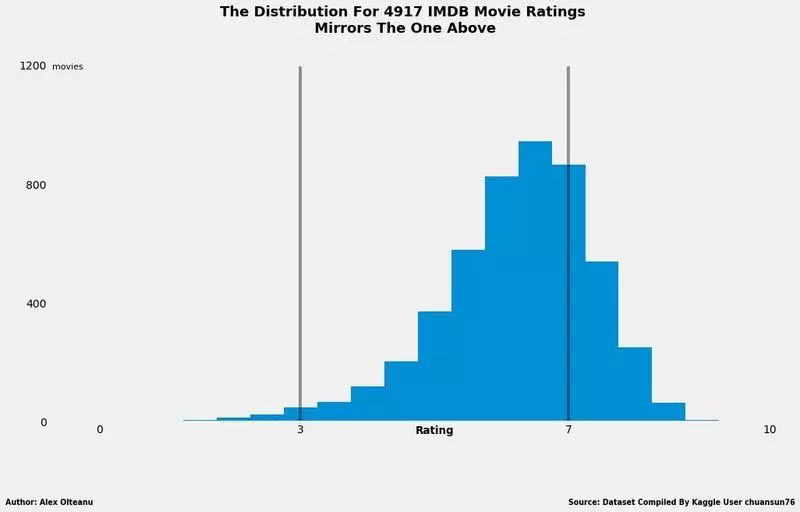
结果与小样本数据量极为相似
大数据量的分布情况与小数据量的分布情况几乎一样,只是在低区域出现了少量的长条(只有 46 部电影,相比 4917 的总量相去甚远)。大部分的值仍然处于平均区域,所以 IMDB 还是有一定的参考价值,但因为出现了倾斜,还是无法与 metascore 的结果相提并论。
不管怎样,我们可以得到一个结论,就是完全可以基于我所给出的 214 部电影评分样本来分析整体的分布情况。换言之,我们有理由相信,基于少量样本得出的分析结果与基于这四个网站所有电影评分得出的分析结果是一样的——至少是相似的。
既然如此,接下来让我们来分析一下 Fandango 的数据分布情况。数据仍然向高区域倾斜,平均区域的左半部分几乎是空的,低区域也是空的。可见,它的分布情况与我们的标准差距太大。所以,我不推荐 Fandango。
tomatometer 的数据分布很平坦,与其他三个网站的不太一样。tomatometer 的评分体系也很独特,它表示的是评论者给出正面评价的百分比,所以很难用“差、平均、好”这样的标准来衡量,它对应的评价结果要么是好,要么是不好。
不管怎样,我猜想它的最终结果仍然会接近于正态分布,大部分电影的正面评价和负面评价的数量差距很有限,只有少部分电影之间的评价差距比较大。
但从 tomatometer 的分布图来看,它并不符合我们的要求。或许使用大数据量可以让其结果更有说服力,但即使是这样,我仍然不推荐它,因为它的评价系统只能分出好与不好。
综上所述,从分布情况来看,我推荐的是 metascore。
不过,如果对低、平均、高这三个区域稍作调整,IMDB 的结果也是可以考虑的。如果是这样的话,那么仅通过数量分布图就得出应该推荐 metascore 的结论就不是很有说服力了。
因此,我决定使用“质量”来区分二者。
我的想法是这样的:使用 Fandango 的变量作为负参考,然后看看 IMDB 和 metascore 哪个变量与之具有最小的相关性(我之所以把它们叫作变量,因为它们的值是可变的——例如,metascore 的值根据不同的电影会有所变化)。
我会计算出简单的相关性系数,具有较小值的变量就是我要推荐的了(我会解释这个相关性系数的原理)。不过,在这之前,先让我简单地解释一下为什么要使用 Fandango 的变量作为负参考。
之所以选择 Fandango 作为负参考,是因为它与正态分布差距最大,明显向高区域倾斜。
另一个原因是 Walt Hickey 对 Fandango 提出过质疑 (https://fivethirtyeight.com/features/fandango-movies-ratings/)。2015 年 10 月,Hickey 对类似的分布情况感到很疑惑,最后发现 Fandango 网站总是将评分往更高的值进行四舍五入(例如,4.1 会被四舍五入成 4.5,而不是 4.0)。
Fandango 团队后来对他们的评分系统进行了更正,并告诉 Hickey 说,网站的评分逻辑确实是个 bug,不过移动端不存在这个问题。不过即使经过更正,结果仍然没有太大变化,所以我仍然会把它作为负参考。
更正之后的变化:
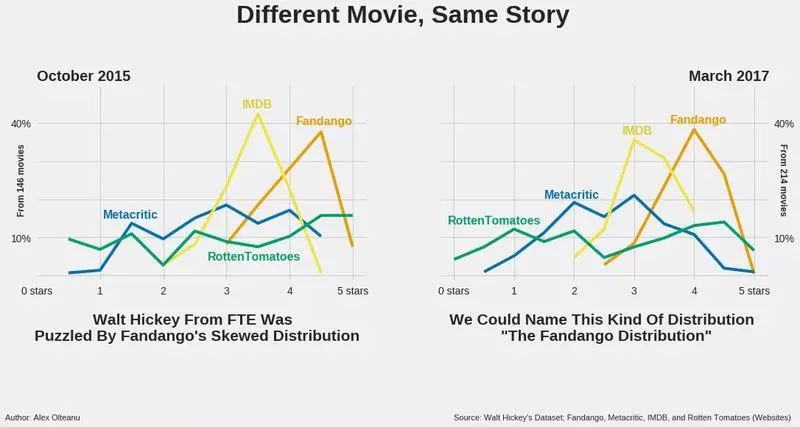
我把其他类型的评分也转成 0 到 5 分的形式,并以 0.5 为基准进行了四舍五入。“FTE”表示 FiveThirtyEight,当时 Hickey 在他的文章中提到了这个缩写。
现在我们进一步查看 Fandango 的分布:
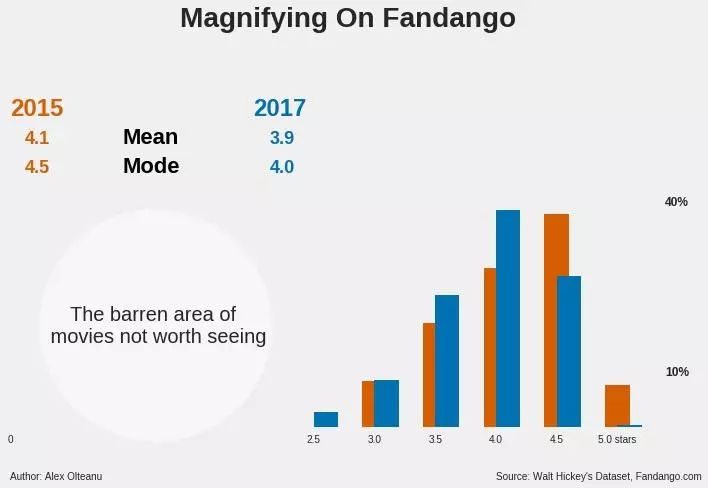
蓝色的长条表示 2017 年的数据,红色表示 2015 年的数据。
结果是 metascore 与 Fandango 具有更低的相关性。它的 Pearson 相关性系数值是 0.38,而 IMDB 是 0.63。
现在让我来解释一下这是怎么回事。
两个变量的值会发生变化,如果在二者之间能够找到某种模式,那么说明它们之间存在一定程度的相关性。所以,衡量相关性就是要看这种模式达到了什么程度。
一种方式是通过 Pearson 相关性系数来衡量。如果系数值是 +1.0,表示具有完美的正相关,而 -1.0 表示完美的负相关。
系数越是接近 0,表示相关性程度越低。
如下图所示:
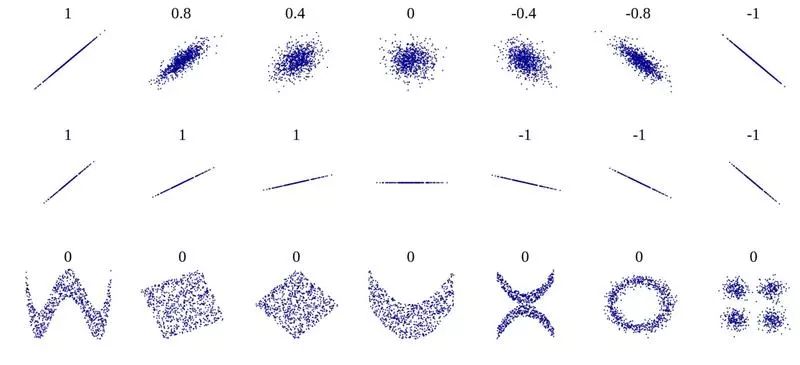
组成各种形状的小点就是指电影的评分变量。
根据上述的相关性系数,Fandango 和 IMDB 之间的模式程度比 Fandango 和 metascore 之间的模式程度更深一些。两个系数都是正数,也就是说,相关性都是正向的,只是 IMDB 比 metascore 更高一些。
换句话说,对于 Fandango 上出现的电影评分,metascore 与之相关性要比 IMDB 低。
综上所述,在选择电影评分时,我建议使用 metascore。
简单地说,metascore 是电影评分的加权平均数。Metacritic 团队根据评论情况为它们赋值,分数在 0 到 100 分之间,然后再根据评论的质量和来源进行加权计算。
不过,metascore 也存在一些不足:
权算法是非公开的,所以我们无法得知权重是如何计算出来的。
Metacritic 是在 1999 年成立的,所以 1999 年以前上映的电影很难找到相应的 metascore。
Metacritic 上不包含一些近几年上映的非英语电影,例如罗马电影《Two Lottery Tickets》(2016 年)和《Eastern Business》(2016 年)。
总的来说,我在这篇文章里为那些需要查看电影评分的人推荐了一个网站。我推荐的是 metascore,因为它的评分分布更接近于正态分布,而且与 Fandango 的评分具有更低的相关性。
本文所有的可视化元素都是使用 Python 生成的,详细信息可参看
https://nbviewer.jupyter.org/github/mircealex/Movie_ratings_2016_17/blob/master/Mv_ratings_project.ipynb 。
查看英文原文:
https://medium.freecodecamp.org/whose-reviews-should-you-trust-imdb-rotten-tomatoes-metacritic-or-fandango-7d1010c6cf19
春节彩蛋!!! 喜欢欧美电影和电视剧的读者有福啦,小编从这篇文章推荐的“最佳”电影评级网站 Metacritic 上找到了一份由该网站 2200+ 用户参与投票评选出的 2017 最佳电影和 2017 最佳电视剧片单,小编将片单整理成了中文版本并贴心附上所有能找到的资源链接(真的很拼了!),还不快来为春节假期多囤几部片?关注 AI 前线,在公众号后台回复关键字“春节囤片”就可以下载这份宝贵的春节囤片指南,祝各位愉快看片、开心过大年!
今日荐文
点击下方图片即可阅读

手机厂商黑莓是百度 Apollo背后的技术支持?没错我们没搞反

人工智能时代已来,什么才是最佳学习路径?
“AI技术内参”将为你系统剖析人工智能核心技术,精讲人工智能国际顶级学术会议核心论文,解读技术发展前沿与最新研究成果,分享数据科学家以及数据科学团队的养成秘笈。

点「阅读原文」,免费试读精品文章




