智源大会自然语言处理论坛精华观点 | 刘群、陶建华、刘挺、黄萱菁、刘洋等解读NLP最新趋势
预训练之后,哪些NLP问题仍待解决?情感计算是如何应用于抑郁线索分析?如何处理NLP中的可解释性问题?在本次智源大会自然语言处理专题论坛上,清华大学教授刘洋,华为语音语义首席科学家刘群,中国科学院自动化研究所研究员陶建华,哈尔滨工业大学教授刘挺,复旦大学教授黄萱菁等就领域内关键技术和问题进行了深入解读。
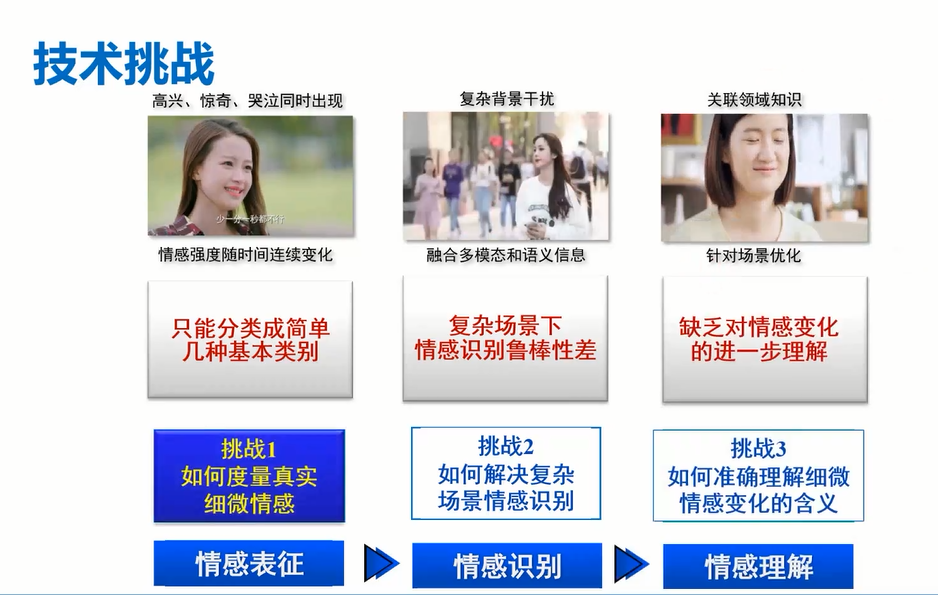
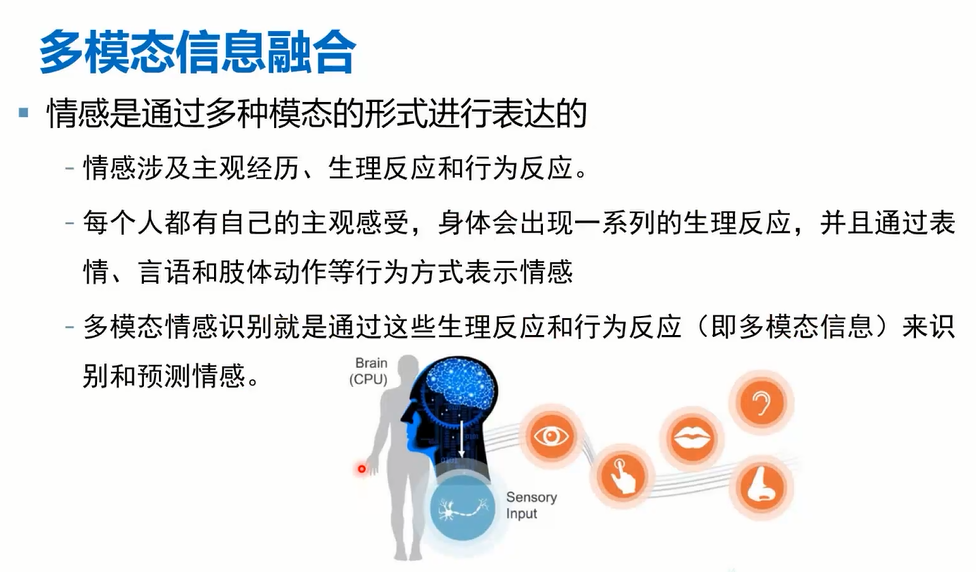
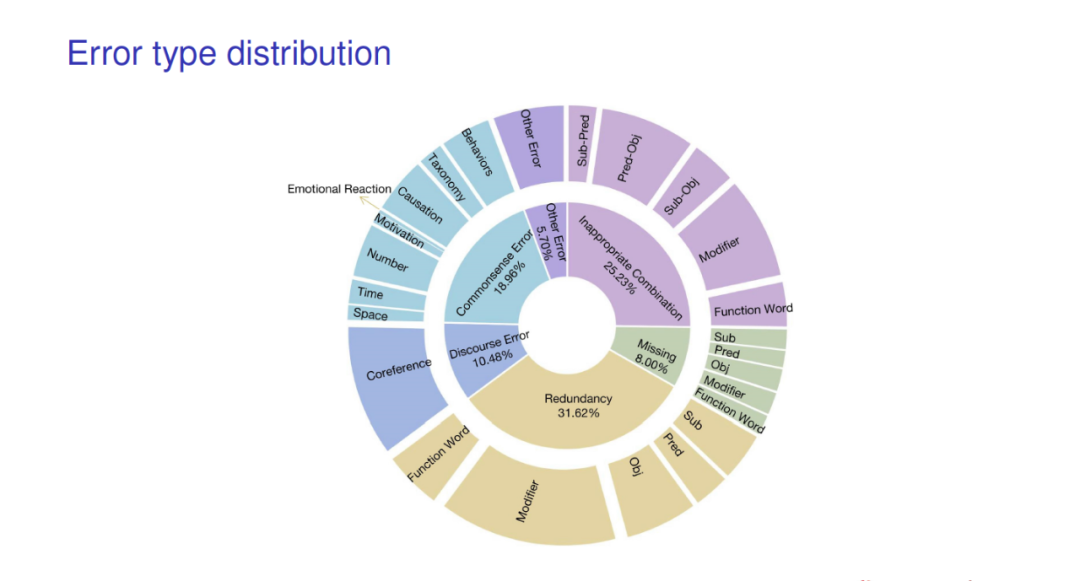



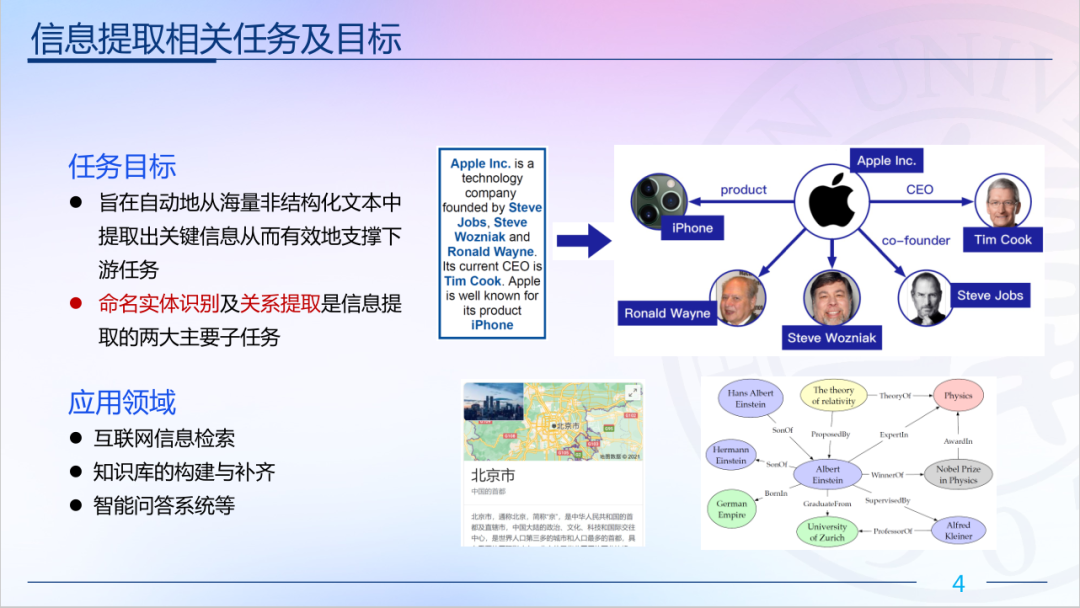
陶建华认为,大模型隐知识、可解释性方面有较大进展与更大突破。刘挺老师认为是谷歌提出的Pathways的通用 AI 架构大模型,还有openAI是2021年推出的文本图像生成模型。DeepMind提出的AlphaCode模型。产业化方面,Hugging Face公司的崛起是工程+产业结合新的突破。
刘挺认为,应该多向神经语言学、心理语言学学习,从这些领域中得到借鉴。陶建华老师认为在不同领域尤其在工业当中有很多研究的内容需要借助于自然语言处理方式,比如大量知识的融入,解决相应工业的问题。
刘群认为是量子计算,也许量子计算哪天真正成为现实,自然语言处理会有一个突破。
刘挺认为,高校的优势是可持续性,专注性研究。工业界一般没有太超前的去布局,高校应该做更超前的研究工作。高校重点是基础性和理论性工作,而且高校探索成本低。
更多推荐
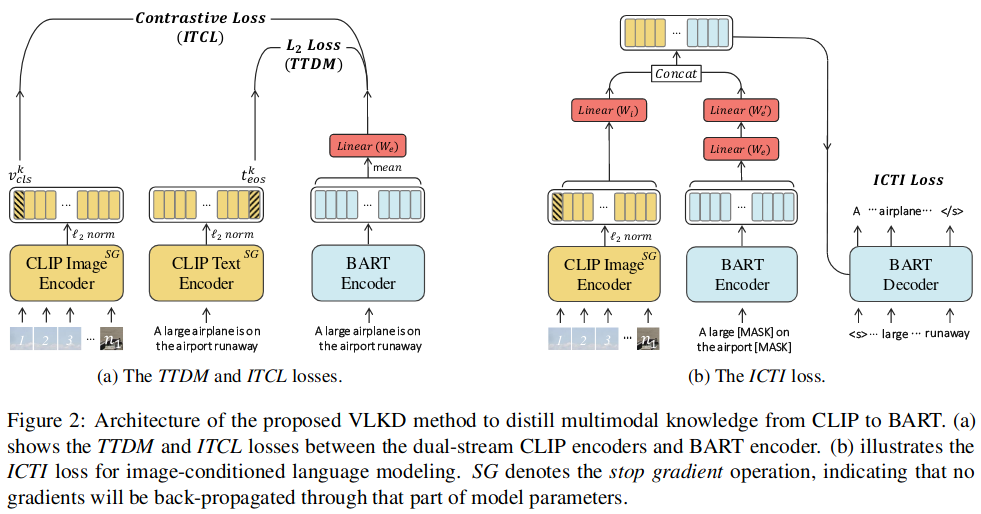
十篇文章速览多模态语言生成的研究进展
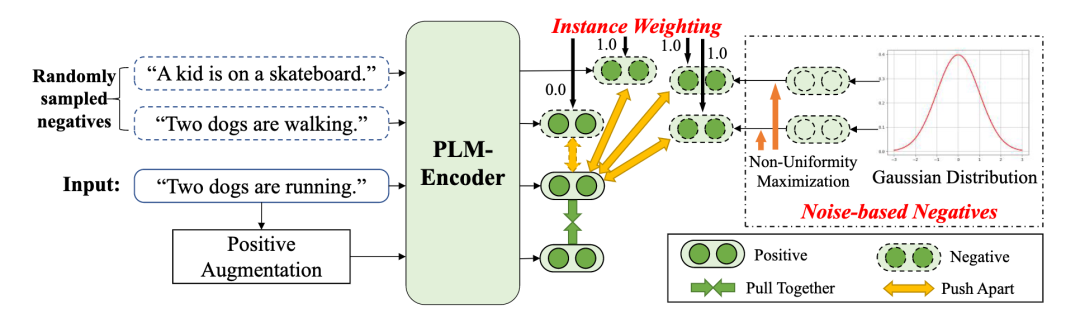
ACL 2022 | 无监督句表示的去偏对比学习
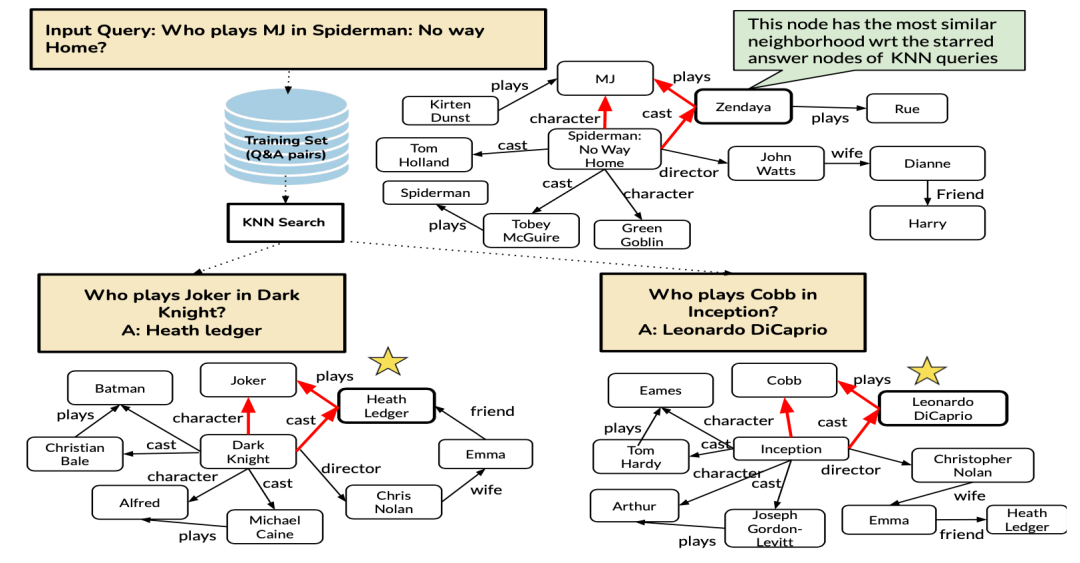
举一反三:示例增强的(example augmented)自然语言处理

登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文