CVPR2018最佳论文演讲:研究任务之间的联系才是做迁移学习的正确姿势
来源:AI科技评论
编者按:能不能迁移、如何迁移、迁移以后表现好不好,一个完全量化的方法出现了。

今年 CVPR 2018 最佳论文《Taskonomy: Disentangling Task Transfer Learning》(任务学:任务迁移学习的解耦)研究了一个非常新颖的课题,那就是研究视觉任务之间的关系,根据得出的关系可以帮助在不同任务之间做迁移学习。相比于我们看惯了的在为各种任务刷分的研究,这篇论文可谓是一股计算机视觉领域的春风。
CVPR 2018 期间 AI 科技评论作为唯一注册媒体进行现场报道,也参加聆听了这篇论文的现场演讲。演讲者为论文第一作者 Amir R. Zamir,他是斯坦福和 UC 伯克利大学的博士后研究员。当他还博士在读时也凭借论文《Structural-RNN: Deep Learning on Spatio-Temporal Graphs》(http://arxiv.org/abs/1511.05298)获得了 CVPR 2016 的最佳学生论文奖。
以下为演讲听译图文全文。

Amir R. Zamir:大家早上好,我介绍一下我们的论文《Taskonomy: Disentangling Task Transfer Learning》,这篇论文是我与 Alexander Sax、William Shen、Leonidas Guibas、Jitendra Malik 以及 Silvio Savarese 共同完成的。

我们首先提出了一个问题,视觉任务之间有什么关系吗?还是说它们都是各自独立的。比如深度估计和表面法线预测之间,或者对象识别以及室内布局识别之间,有没有什么关系。我们觉得答案是肯定的,不管是从我们的直觉上还是借助一些知识。比如我们知道表面法线预测模型、深度预测模型或者室内布局模型都可以为物体识别带来不小的帮助。所以任务之间肯定是有一些关系的。
那么这些关系有哪些影响?它们又会有什么重要作用呢?这就是我今天要讲给大家的。

我要介绍这四个要点:
任务之间的关系是存在的
这些关系可以通过计算性的方式得到,不需要我们作为人类的知识参与
各种任务属于一个有结构的空间,而不是一些各自独立的概念
它可以为我们提供一个用于迁移学习的统一化的模型

刚才我展示的例子只是许多视觉任务中的几种。任选一些任务出来我们都可以问这样的问题:它们之间有没有关系、有多大关系。为了回答这些问题,我们要对任务之间的关系、任务之间的冗余有一个全局的认识,我们需要把任务作为一个集体来看待,而不是作为单个单个的任务。我们利用它们之间的关系和冗余度达到更高的效率。
其中有一个非常令人感兴趣的值得提高效率的方面就是监督的效率,就是我们希望用更少的标注数据来解决问题,我们这项研究的关注点也就在这里。许许多多的研究论文都讨论了如何减少模型对标注数据的需求,现在也有自我监督学习、无监督学习、元学习、任务适配等方法,以及在 ImageNet 上学到的特征基础上做精细调节,现在这都已经成了一种惯用做法了。
实际上,迁移学习之所以可行就是因为任务间的这些关系。从高抽象层次上讲,如果能够迁移或者翻译一个模型学到的内部状态,这就有可能会对学习解决别的任务起到帮助 —— 如果这两个任务之间存在某种关系的话。下面我详细讲讲这部分。

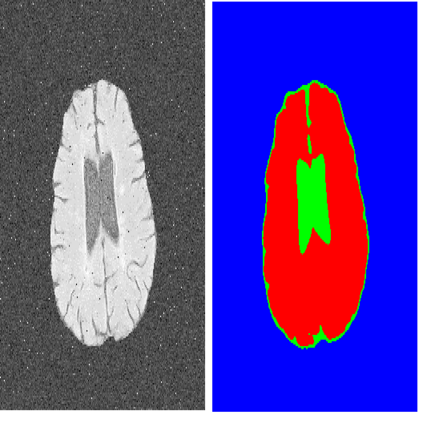
以表面法线预测任务(surface normal)为例,我们专门训练一个神经网络预测图像中的平面的法线,显然效果是不错的。如果我们只用 2% 的训练数据训练网络,就会得到左下角这样的结果,显然我们都能猜到结果会很糟糕。
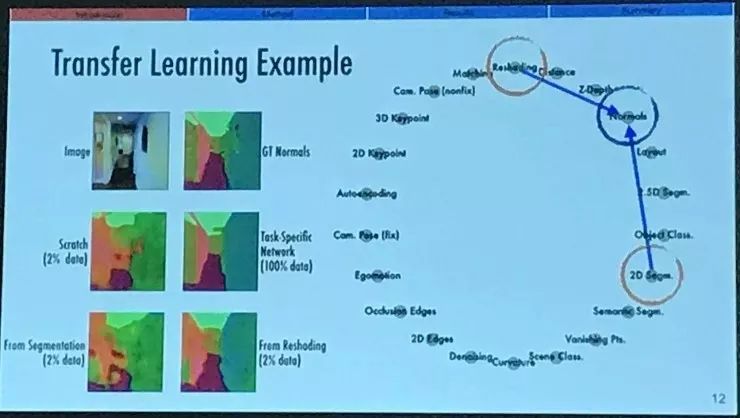
然后我们从两个其它的任务,图像重整(reshading)以及图像分割(segmentation)的模型做迁移。迁移的时候都是在一个小的复制网络上用刚才同样的 2% 的数据做训练。
可以看到,图像分割模型迁移后的表现并不好,但是图像重整模型的表面法线预测表现就不错。这就表明了,图像重整和表面法线预测之间的关系要比图像分割与表面法线预测之间的关系更强、更紧密。直觉上这还挺合理的,我们会觉得对场景做重整的时候就是会与平面的法线有不少联系;相比之下法线预测与图像分割之间,我就想不到会有什么关系,也可能是真的没有什么关系吧。所以我们观察到,对于互相之间有关系的任务,我们只需要一点点额外的信息就可以帮助一个任务的模型解决另一个任务。
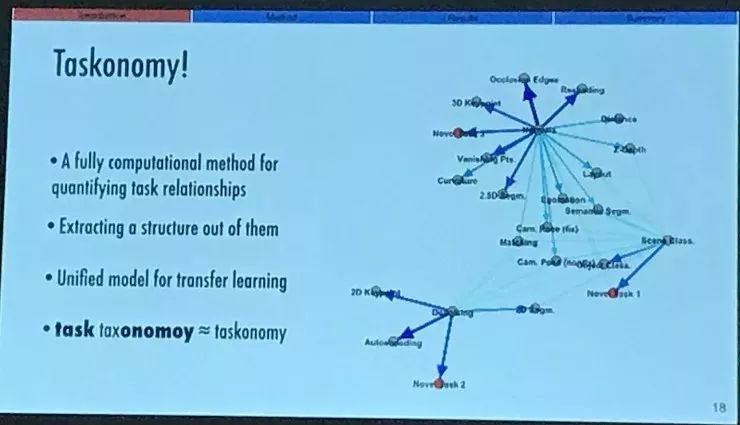
如果你能有一些方法,把大量任意给定的任务之间的关系进行量化,我们就可以得到一个完整的图结构。这就是我们期待的那种可以理解不同任务之间的冗余度的一个全局窗口。比如它可以利用我们前面提到的任务之间的冗余度解决一系列监督学习任务,可以只用一点点资源就把旧任务迁移到新任务上;或者解决一个全新的任务,我们几乎没有这个任务所需的标注数据。那么现在学习解决新任务就变成了向原有的结构中增加一些内容,而无需从零开始。
这就是我们的「Taskonomy」的目的,这是一种完全计算化的方法,可以量化计算大量任务之间的关系,从它们之间提出统一的结构,并把它作为迁移学习的模型。我们把它称作「Taskonomy」,也就是 task 任务 和 taxonomony 分类学 两个词的组合,就是意味着要学到一个分类学角度出发的迁移策略。

我们具体是这样做的。首先我们找到了一组一共 26 个任务,包括语义、 2D、2.5D、3D 任务。我们并没有细致全面地选择更多的各种视觉任务,这些只是我们演示方法用的一组样本;稍后我还会再谈到参与计算的任务列表的选择。我们收集了大约 400 万张室内物品的照片,然后每一张照片都为这全部 26 种任务做了准备。这些图像全部都是真实的,不是生成的;对于 3D 视觉任务,我们用结构光传感器扫描出了相应的室内场景结构,这样我们也可以更容易地为这些任务获得真实值。

接下来我们为任务列表里的这 26 个任务分别训练了 26 个任务专用神经网络,这些画面就是这 26 个任务的输出。3D 任务比如曲率预测,语意任务比如物体识别;也有一些任务是自监督的,比如着色。
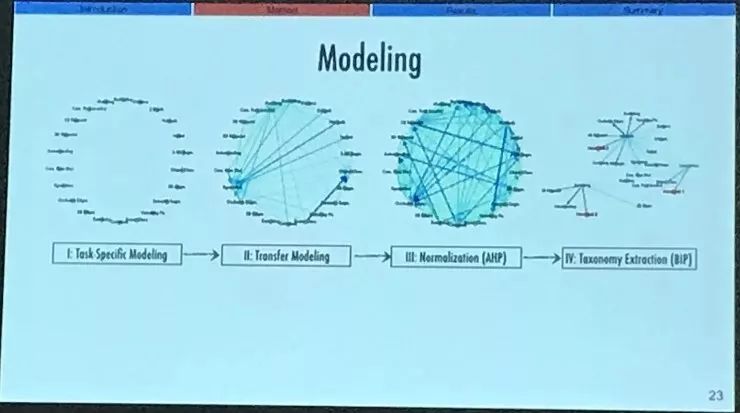
我们的任务学模型有四个主要步骤,第一步就是训练这 26 个任务专用网络,然后把权值锁定下来;这时候每一个任务就都有一个专门为了它训练的神经网络。

下一步是量化不同任务之间的关系。比如以计算法线估计和曲率估计之间的关系为例,我们用锁定了权值的法线估计模型训练一个小的复制模型,这个小模型从法线估计模型的表征中尝试计算曲率。然后我们就用新的测试数据评估小模型的表现。这个表现就是评估具体这两个任务之间的直接迁移关系的依据。
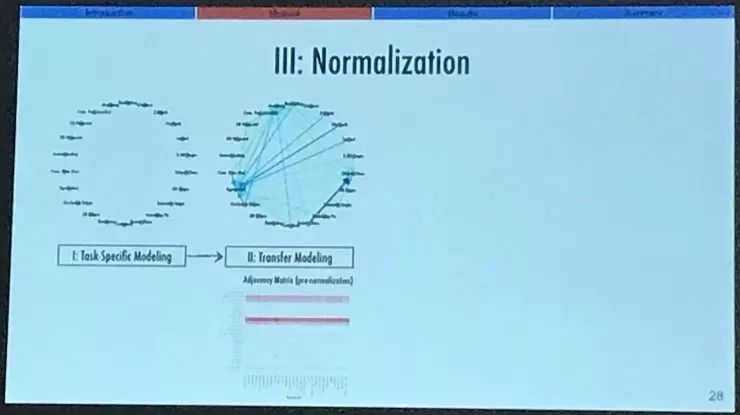
那么,含有 26 个任务的清单,一共有 26 x 25 中组合方式,我们把它们全都做了这样的训练和评估。这样就得到了我们想要的完整的任务关系图结构。不过,节点之间的值还需要标准化,因为这些任务都是属于各自不同的输出空间的,也有不同的数学性质。对于关系的描述,我们求了这样的整个图结构的邻接矩阵(adjacency matrix),从计算结果可以明显看到其中有一些东西在矩阵中起到了决定性的作用。原因就是因为这些任务存在于不同的输出空间中,我们需要做标准化。
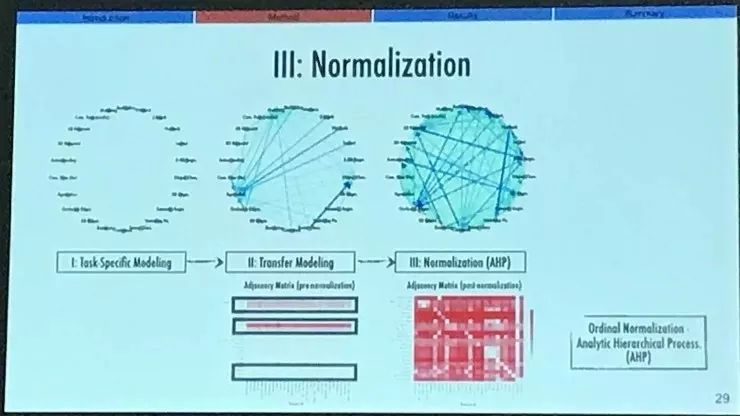
我们对矩阵做标准化的方法是一种名为分析性层次过程(Analytic Hiererchical Proess)的序数方法。在这里我就不详细介绍了,不过简单来说,我们选取了一种序数的模式,因为相比其他的一些分析方法,它对输出空间的数学性质做出的假设对我们来说非常关键。具体内容可以参见我们的论文。
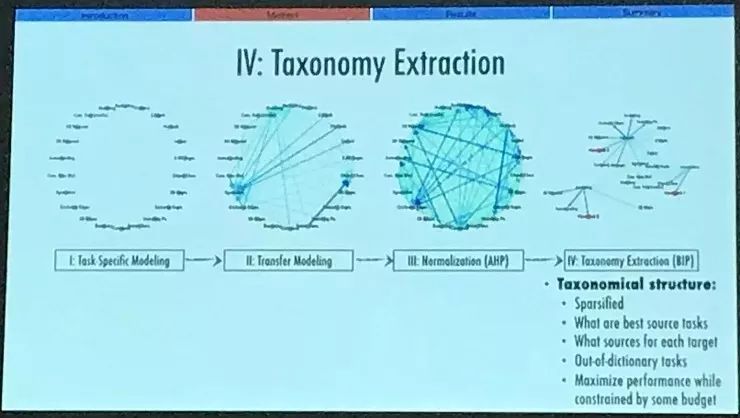
那么, 这个完整的关系图结构已经是完全量化了的,针对一对一对的任务之间,它的取值就是任务迁移的依赖程度。值得注意的是,并不是任意两个任务之间的迁移都有用,有很多任务之间的关系都很弱。但是当然有一些很强的关系,而且有一些明显的模式。
我们就希望从完整的图结构中提取出这种稀疏的关系。对我们来说,提取出的结构能帮助我们最大化原先任务的表现,并且告诉我们如何为新任务选择一个最好的源任务、哪个源任务可以迁移到尽可能多的任务中,以及如何迁移到一个任务清单中不包括的新任务上去。
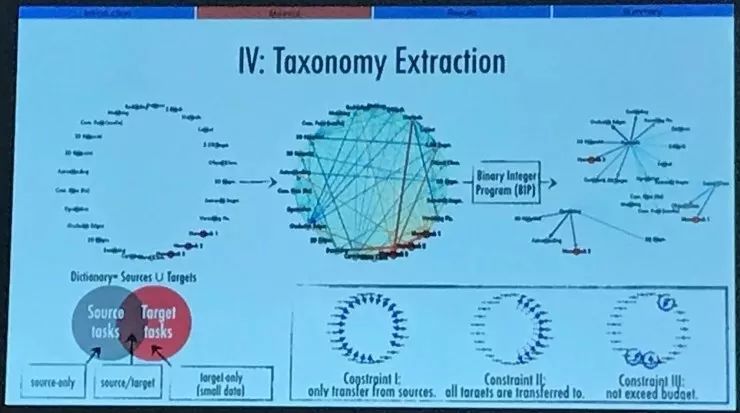
在这一步中我们做的简单来说可以形式化为一个子图选择问题。我们已经定义好了任务清单,之前已经见过的任务用灰色的节点表示,未见过的新任务用红色的节点表示。然后我们设定一些限制,用二进制抽取的方式计算得到最优的子图。计算细节可以看我们的论文或者海报,还挺简单直接的。
子图抽取得到的结果就给我们提供了想要解决每一个任务所需的连接性,包括全新的任务,如何使用有限的资源、不超过用户定义限度的资源来最大化各个任务的表现,而用户定义的资源的数量实际上也决定了源任务的任务清单能够有多大。这也就是我们的目标。
(注:论文中有另一张全过程示意图如下)
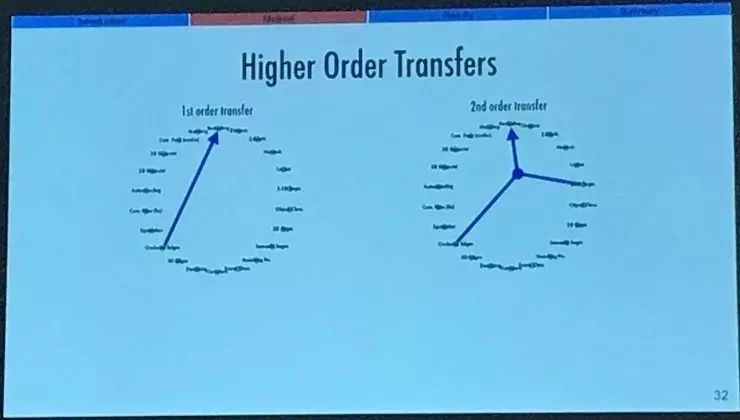
还有一点我没有时间展开讲的是高阶任务迁移,就是 2 个甚至更多的任务可以一起作为源任务和资源开销,在我们的框架内进行计算。那么实际上我们的邻接矩阵也就远大于 26 x 25 ,因为还有多对一的情况。

下面说一下实验结果。对于 26 个任务的任务清单,一共有 3000 个任务迁移网络,花费了 47829 小时的 GPU 时间。训练模型大概花了我们 4.7 万美元。训练迁移后的模型只用了 1% 的任务专用网络的训练数据。
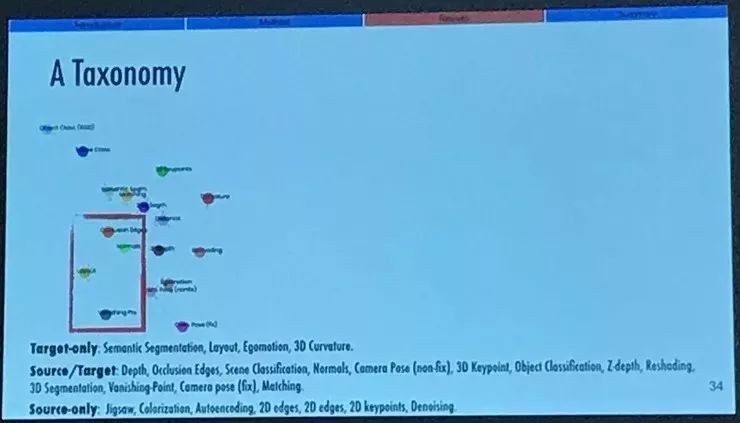
这是一个任务分类结果的例子。这个例子中包含的是我前面说的这 26 个任务,其中有 4 个是作为目标的任务,也就是说它们只有非常少的数据,这些数据刚刚够训练复制的迁移网络,而无法从零训练一个新的网络。查看一下这几个任务的连接性就会直觉上觉得是那么回事,3D 任务和其它的 3D 任务之间有更强的联系,以及和 2D 任务的相似度很低。

为了评估我们的迁移策略的效果,我们提出了两个评价指标,增益 Gain 以及质量 Quality。增益是指迁移的网络的表现相比用同样的少量数据从零训练的表现的胜率;图中越深的蓝色表示越高的胜率,也就是说迁移的效果总是要更好。质量是指迁移的网络相比用全部数据训练的任务专用网络的胜率,我们可以看到许多情况下都是白色,就是说这些迁移后的模型的表现已经和作为黄金标准的任务专用网络的表现差不多好了。
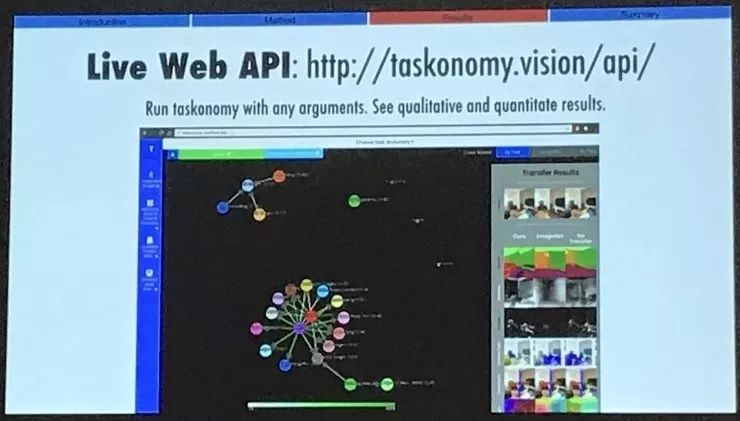
这只是一个分类学的例子,大家可以编写自己的实现,不过最好的方法还是试一试我们的在线实时 API, taskonomy.vision/api,你可以自己设定想要的参数,查看任务分类学的定性以及定量的计算结果。值得一提的是,我们的分类学结果很适合配合 ImageNet 的特征使用,因为它也是目前最常用的特征了。我们也做了一些和 ImageNet 相关的实验,欢迎大家看我们的论文。
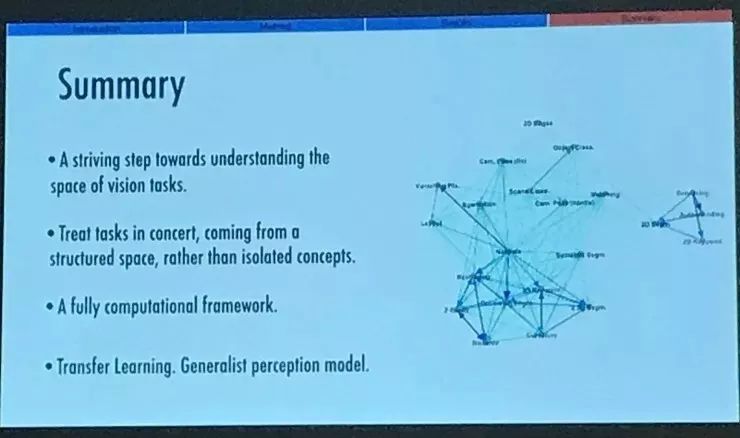
最后总结一下:
我们向着认识视觉任务空间的目标迈出了积极的一步;
我们把任务作为一个结构化空间中的群体,而不是作为单个单个的概念来看待;这里这张图就是根据量化的关系绘制的。
这是一个完全可计算化的框架;
它可以帮助我们做迁移学习,也可以帮助我们寻找通用化的感知模型。
访问我们的网站 http://taskonomy.stanford.edu/ 的话还可以看到一个 YouTube 的介绍视频。谢谢!
(完)
实际上 http://taskonomy.stanford.edu/ 网站上有丰富的研究介绍以及资源,实时演示 demo、用于定制化任务计算的 API、迁移过程的可视化、预训练模型、数据集下载等一应俱全。同作者所说一样,希望了解更多信息的可以阅读论文原文以及访问他们的网站。
论文地址:
http://taskonomy.stanford.edu/taskonomy_CVPR2018.pdf
*推荐文章*
【CVPR 2018最佳论文出炉】斯坦福等名校折桂,何恺明获年轻研究员奖
极市干货|孙书洋 CVPR 2018论文详解:光流导向特征在视频动作识别中的应用
PS.极市平台诚招计算机视觉算法工程师啦~工作要求请关注“极市平台”公众号(id:extrememart),点击菜单加入极市“诚招”栏或直接私信小助手(微信:Extreme-Vision),欢迎大牛来戳~