DeepMind推出「控制套件」:为「强化学习智能体」提供性能基准
来源:arxiv
作者:Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez,Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel,Andrew Lefrancq, Timothy Lillicrap, Martin Riedmiller
「雷克世界」编译:嗯~阿童木呀、KABUDA

DeepMind Control Suite是一组连续的控制任务,具有标准化的结构和可解释性的奖励,旨在作为强化学习智能体的性能基准。这些任务是用Python编写的,由MuJoCo物理引擎驱动,从而使得它们易于使用和修改。我们这里涵盖了几个学习算法的基准。你如果对这方面比较感兴趣,可以在github.com/deepmind/dm_control上获得公开的控制套件(Control Suite),而所有任务的相关视频总结等可在youtu.be/rAai4QzcYbs上获得。
可以这样说,控制物质世界是通用智能一个不可分割的组成部分,也可以说是通用智能的一个先决条件。事实上,唯一已知的通用智能的例子就是灵长类动物,他们操纵这个世界已经有数百万年的时间了。
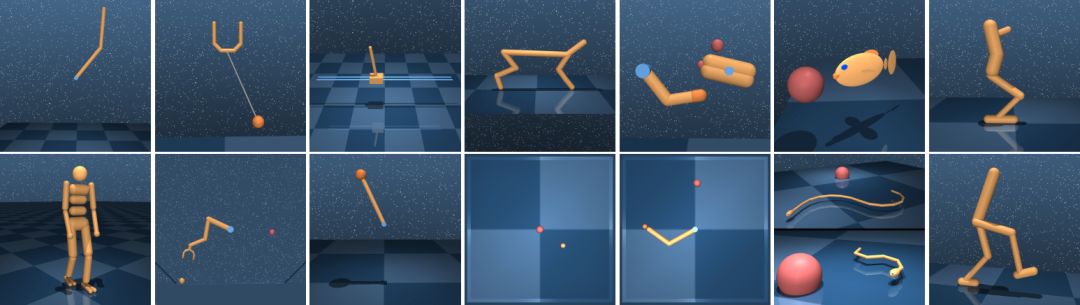
基准测试领域。顶端:机器人、球杯、卡杆、猎豹、,手指、鱼、单足跳者。底部:人形机器人、操纵器、钟摆、质点、Reacher、游泳运动员(6和15个连接点)、行走者。
物理控制任务有许多共同的属性,而且,将它们视为一类独特的行为问题是一种明智的选择。与棋盘游戏、语言和其他符号域不同的是,物理任务在状态、时间和行为上是基本连续的。它们的动力学受二阶运动方程的影响,而这意味着基础状态是由类似位置和类速度的变量组成的,而状态导数则类似于加速度。感官信号(Sensory signals)(即观察)通常携带有意义的物理单位,并且在相应的时间尺度上发生变化。
在这十年中,在诸如视频游戏这样的困难问题领域中,强化学习(RL)技术的应用取得了快速的进展。Arcade学习环境(Arcade Learning Environment,ALE,Bellemare 等人于2012年提出)是这些发展的重要促进因素,为评估和比较学习算法提供了一套标准基准。 DeepMind Control Suite为连续控制问题提供了一组类似的标准基准。
OpenAI Gym(Brockman等人于2016年提出)目前包括一组连续控制域,而且已经成为连续强化学习实际上的基准(Duan 等人于2016年、Henderson等人于2017年提出)。Control Suite也是一组任务,用于对连续的强化学习算法进行基准测试,其中存在着一些显著的差异。我们只专注于连续控制,例如将观察值与相似的单位(位置、速度、力等)分离,而不是将其连接成一个向量。我们统一的奖励结构提供了具有可解释性的学习曲线和综合性适用范围的性能度量。此外,我们强调使用统一设计模式的高质量的完整代码,提供可读、透明和易于扩展的代码库。最后,Control Suite与Gym一样,里面都有相同的域,而且同时增加了更多的域。
DeepMind控制套件是强化学习算法(基于物理控制)的设计和性能比较的起点。它提供了各种各样的任务(从几乎微不足道的任务到相当困难的任务)。统一的奖励结构可以实现对套件整体性能的评估。
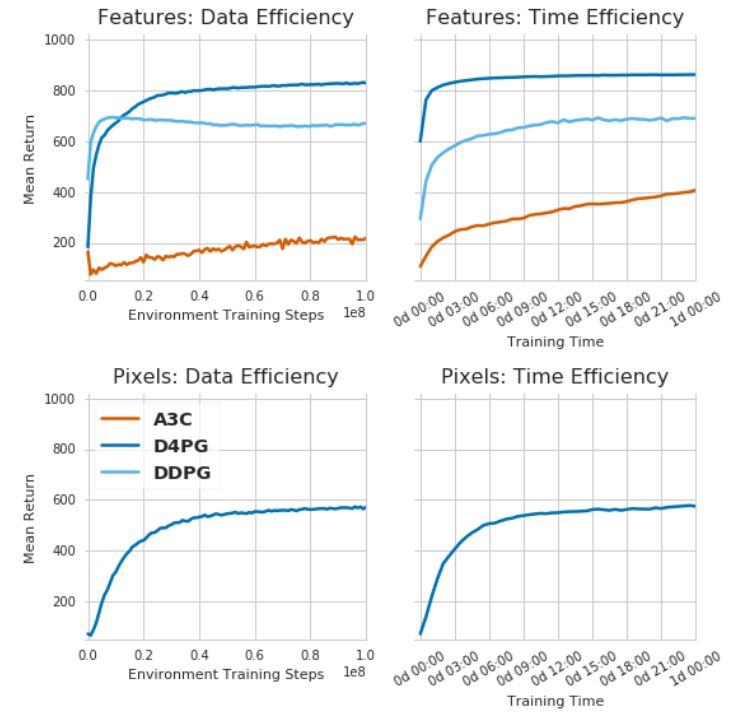
Control Suite中所有任务的标注为数据(第一列)和挂钟时间(第二列)对比的平均返回值。 第一行显示使用低维特征作为输入的任务中的A3C、DDPG和D4PG的性能表现。第二行显示了D4PG在仅使用原始像素作为输入的任务上的性能表现。
这里展示的A3C、DDP和D4pg的结果组成的基线,是通过运用我们提出的理论,对这些算法进行良好的执行得到的。同时,我们强调,学习曲线不是基于穷举的超参数优化,并且对于给定的算法,在控制套件的所有任务中都使用相同的超参数。因此,我们期望能够获得更好的性能或数据效率,特别是在每个任务的基础上。
我们很乐意与更多的社区分享控制套件,并且希望有更多人能够注意到它的作用,我们期待着能够对套件进行多样化研究,并将社区所做出的贡献整合到未来发布的版本中。
未来研究方向
对于Control Suite的当前版本来说,里面还缺少一些元素。
有一些特征,比如缺乏丰富的任务,这是在设计中没有考虑到的。该套件,尤其是基准测试任务,旨在成为一个稳定、简单的学习控制起点。像复杂地形中的完全操纵和运动的任务类别需要对任务和模型的分布进行推理,而不仅仅是对初始状态进行操作。而所有这些都需要更为强大的工具,我们希望未来在不同的分支机构中能够进行共享。
以下几个特性并没有包含在当前发布的版本中,但我们打算在将来的版本中将其添加在内。 它们包括:一个四足行走的动作任务;一个交互式的可视化程序,用其便可以查看和扰乱模拟;支持C回调和多线程动态;MuJoCo TensorFlow封装器和Windows™支持。
dm_control: DeepMind控制套件和控制包
此软件包含:
一套由MuJoCo物理引擎驱动的Python强化学习环境。
为Mujoco物理引擎提供python绑定的库。
如果你使用此软件包,请引用我们随附的技术报告。
安装要求
请按照以下步骤安装DM_control:
1.从Mujoco网站的下载页面下载Mujoco pro1.50。必须在安装dm_contect之前安装mujoco pro,因为dm_contect的安装脚本由mujoco的头文件生成python ctypes绑定。默认情况下,dm_contect假定mujo COZIP归档文件被提取为~/.mujoCO/mjpro150。
2.通过运行pip install git + git://github.com/deepmind/dm_control.git(PyPI包即将推出)或通过复制存储库并运行pip install / path / to / dm_control /来安装dm_control Python包。在安装时,dm_control在〜/mujoco / mjpro150 / include中查找步骤1中的MuJoCo头文件,然而这个路径可以使用headers-dir命令行参数进行配置。
3.为mujoco安装一个许可密钥,该密钥在运行时由dm_controls命令。有关详细信息,请参阅Mujoco许可密钥页面。默认情况下,dm_contect在~/.mujoco/mjkey.txt处查找mujo co许可密钥文件。
4.如果在非默认路径上安装许可密钥(例如mjkey.txt)或mujocopro提供的共享库(例如libmujoco150.so或libmujoco150.dylib),则分别使用mjkey_jmpATH和libm path指定它们的位置。
关于macOS上的自制软件用户的其他说明
1.只要你使用的是由Homebrew安装的python解释器(而不是系统默认的解释器),那么以上使用pip的说明应该有效。
2.要使Open GL正常工作,请通过运行brew来安装GLFW,然后安装来自Homebrew的GLFW包。
3.在运行之前,需要使用GLFW库的路径更新DYLD_library_path环境变量。这可以通过运行export dyld_library_path=$(brew--prefix)/lib:$dyld_library_path来完成。
控制套件快速入门
from dm_control import suite
# Load one task:
env = suite.load(domain_name="cartpole", task_name="swingup")
# Iterate over a task set:
for domain_name, task_name in suite.BENCHMARKING:
env = suite.load(domain_name, task_name)
# Step through an episode and print out reward, discount and observation.
action_spec = env.action_spec()
time_step = env.reset()
while not time_step.last():
action = np.random.uniform(action_spec.minimum,
action_spec.maximum,
size=action_spec.shape)
time_step = env.step(action)
print(time_step.reward, time_step.discount, time_step.observation)
详情请参阅技术报告:https://github.com/deepmind/dm_control/blob/master/tech_report.pdf
以下是一个已解决的控制套件任务的相关视频(启用了奖励可视化功能)。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”




