深度推荐系统之序列化建模2019最新进展
作者:Dylan
来源:https://zhuanlan.zhihu.com/
p/93467919
整理:深度传送门
背景
传统推荐系统从content-based和social-based等基本模式所衍生出的多种多样的方法,都是将user-item所产生的behavior作为独立信息看待。然而现实生活中,用户的行为前后都存在极强的关联性甚至因果性。典型的在电商推荐场景,当用户买了一款手机之后,接下来如果推荐手机周边配件等物品则显得更合理一点,基于用户历史行为的序列化建模可以很好的解决这类问题。
写在前面
1. 本文重点将放在这些方法设计思路的一些亮点上,诸如Transformer、Bi-LSTM等基本概念的理论细节不再涉及并默认大家都已经了解;
2. 从最初的MC+MF方法,到后来深度学习兴起后的RNN-Based,再到近两年Google发表 ‘Attention is All You Need’后,Attention-Based的铺天盖地。经典paper的演进之路,在时间上反映了技术方法的革新与流行。不过我们真正要在进行业务实践时,不妨做一些更全面的考量和尝试;
3. 混合结构模型实际上是“领域信息”的先验带入,“mlp可以拟合任意函数”仅仅是理论理想主义的一种表达。不过当我们要在业务上尝试应用这些复杂模型的时候,对业务场景和工具的深入理解变的至关重要。
2015 GRU4REC:Session-based Recommendations with Recurrent Neural Networks
背景与动机
传统序列化推荐方法只考虑了用户的last behavior,没有使用到完整的session行为序列信息,作者引入RNN-based方法直接解决这个问题。
模型与特点
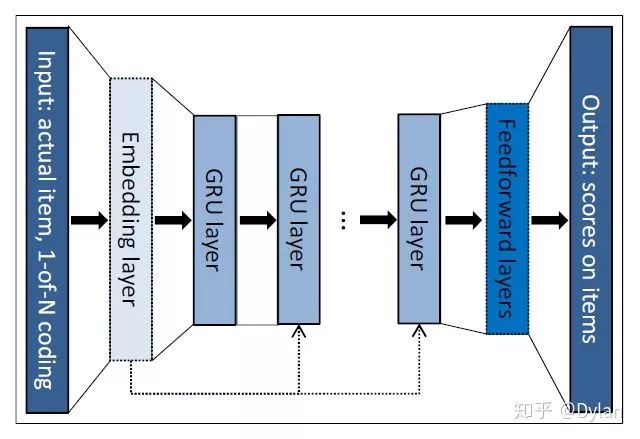
GRU4REC是一个单纯基于GRU的session sequence->next step的序列化预测模型(不同于sequence->target类型的序列化建模),每一个step 的输入经过embedding layer给到GRU,得到next step的预测。
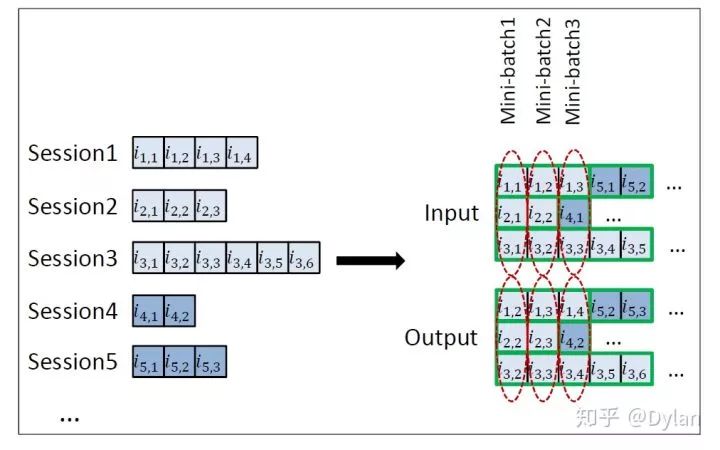
文章提出了一种Session-parallel mini-batch的方法,通过session粒度的并行极大加快了RNN-based模型的训练。这个工程层面的优化很巧妙,相当于将session样本分别放入BatchSize个队列中,step-by-step的进行训练。任意一个队列中出现session切换时,相应的GRU state将会被重置然后重新从序列起始开始训练(训练时构建BatchSize个GRU单元,每条队列对应的GRU有自己的hidden state,共享W/b网络参数)。
每个step作为新的input,next batch step作为target,batch中其他session的target作为当前session的负样本。这种处理方式,既兼顾到效率(batch loss的计算转换为了一次矩阵乘法),同时也达到了从高流行度物品集中进行负采样的效果。
文章指出pointwise的方式并不是最适合推荐ranking这种场景,提出了BPR和TOP1两种pairwise的loss。这里注意下,对于我们做推荐的同学应该都知道pointwise、pairwise和listwise这三种LTR的范式,在需要做ranking的场景我们并不需要对item做出一个准确的score预估,只要能得到尽可能好的排序顺序即可。Pairwise的loss function往往具有平坦底部,能够显著减低推荐排序模型的学习难度,建议多考虑。
小结
GRU4Rec算是开创了RNN-based的session行为推荐方法,相比较于未来混合结构的序列模型,单一RNN的结构就比较简单。但是其在工程实践方面的优化以及loss的思考上确实很不错,开阔大家的思路。
2018 SASRec:Self-Attentive Sequential Recommendation
背景与动机
传统MC方法仅考虑用户last behavior的影响,模型简单在稀疏数据场景效果更好。RNN-based的方法,能够处理长的用户行为序列,模型复杂在数据丰富并且支持复杂计算的场景更好。SASRec作为Attention-based方法,在两类方法之间做到一定的兼顾和平衡。
模型与特点
因为self-attention model没有任何关于序列的结构化信息,所以SASRec在embedding layer加入position embedding,给模型引入了结构信息。
“We modify the attention by forbidding all links between Qi and Kj (j > i) ”。整体结构脱胎于Transformer,不同点在于在Self Attention Layer保证了left-to-right unidirectional architectures,进行一层Mask处理就好了。
小结
Transformer在序列化推荐上的应用,对于Self Attention的改造值得学习。
2018 DIEN: Deep Interest Evolution Network for Click-Through Rate Prediction
背景与动机
这篇文章是阿里DIN的升级版,提出一个观点是用户兴趣是随时间而发生变化的。
模型与特点
Behavior Layer,behavior序列/category特征做embedding。
Interest Extractor Layer,区别于一般的直接用behavior embedding表达兴趣(类似DIN),这里使用GRU来提取用户的潜在兴趣表达&行为之间的依赖。然而GRU的hidden state只能捕捉行为间的依赖,不能有效的表达兴趣。所以论文提出auxiliary loss,使用t+1时刻的behavior embedding bt+1去监督ht(计算loss),除了用next behavior作为正例,从item集合中抽样非next behavior作为负例(模型图左侧示意) 。增加auxiliary loss后,有以下几个好处:
GRU hidden state ht可以有效表达用户兴趣
降低了GRU模型长序列BP的难度
使用embedding layer学到更多语义信息,得到更好的embedding矩阵。
Interest Evolving Layer,用户在行为序列上表达出的兴趣表现出兴趣迁移的特性。在GRU的每一步引入local activation,强化target相关兴趣的影响力,弱化不相关的部分。
文章提到3种Attention和GRU结合的方式AIGRU/AGRU/AUGRU,AIGRU通过attention score at标量乘法直接弱化hidden state ht的影响,但input 0也能影响到GRU的hidden state;AGRU用attention score替换了GRU的update gate,也是at标量乘法直接弱化hidden state ht的影响,但是失去了分布式表达不同维度差异化的表达;AUGRU能够减弱兴趣漂移的干扰,让相关性高的兴趣能平滑的evolve,最后采用了AUGRU。
小结
DIEN对attention和GRU的结合做了比较多的工作,这篇文章值得仔细学习和参考。
2018 Caser:Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
背景与动机
主要还是解决MC类方法,只考虑last behavior而没有考虑序列pattern的问题。虽然RNN-Based和Attention-Based方法一定程度上能够解决这类问题,但文章提出的基于CNN思路很不错值得学习下。
模型与特点
在用户行为序列上滑窗产生样本,前L个行为作为input,接下来T个行为作为target。
L个input行为经过embedding layer得到L*d的矩阵(d是latent dimension size),将其看做一张二维图像,分别用水平和垂直两个convolution kernel来捕捉用户行为序列里面的结构信息。
最后和user representation concat到一起全连接,预测next T-targets。
小结
没有直接作为典型的left-to-right unidirectional 结构来处理,而是整个作为结构化的信息交给CNN来进行特征提取。CNN-Based的序列化建模方法,个人认为是一个很不错的尝试,值得在应用中考虑。
2019 BERT4Rec:Sequential Recommendation with Bidirectional Encoder Representations from Transformer
背景与动机
这是阿里在电商推荐上对大热BERT的一次尝试。文章挑战了left-to-right unidirectional 结构的表达能力,以及其在实际推荐场景的合理性。Introduction中举了一个例子,用户在浏览多个口红时的顺序并没有太多的作用,作者Bidirectional model更为合适。
模型与特点
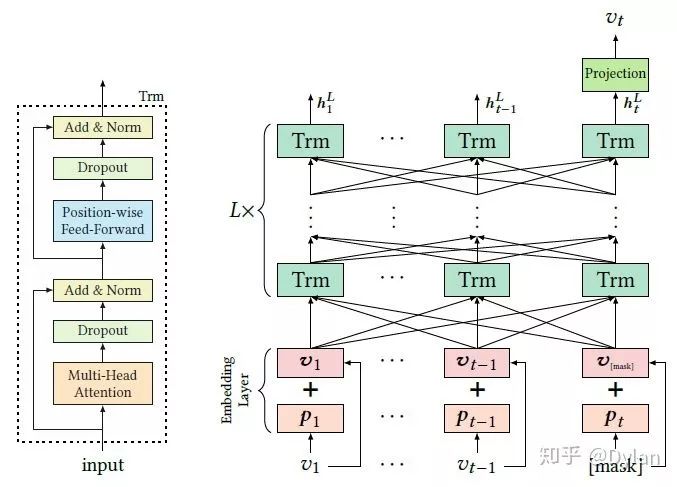
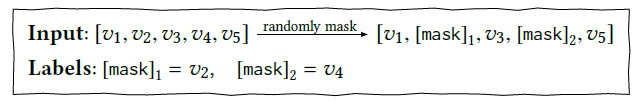
将用户行为序列看做文本序列,但BERT不能直接用双向信息做序列预测(会造成信息泄露),于是在文章中序列化建模的问题转变成了Cloze task。随机mask掉user behavior sequence中部分item,然后基于sequence中的上下文来预测被mask掉的item。Cloze Task随机对sequence mask来构成样本的机制,使得BERT4Rec可以产生大量的样本用于training。
为了training task保持一致,预测时在user behavior sequence最后加上special token [mask],然后进行mask predict即等价于预测next item。为了使得模型更好的match predict task,特意构造出只mask sequence最后一个item这样的样本用于训练。
小结
1. 文章实际上依靠position embedding来产生sequence的信息,bidirectional sequential更多的是基于Transformer的context;
2. 对于序列化建模问题的转换,以及训练样本的处理都很值得借鉴。
2019 BST:Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
背景与动机
文章仍然是Transformer的一个应用,模型简单清晰,部署在TaoBao作为一个排序模型。
模型与特点
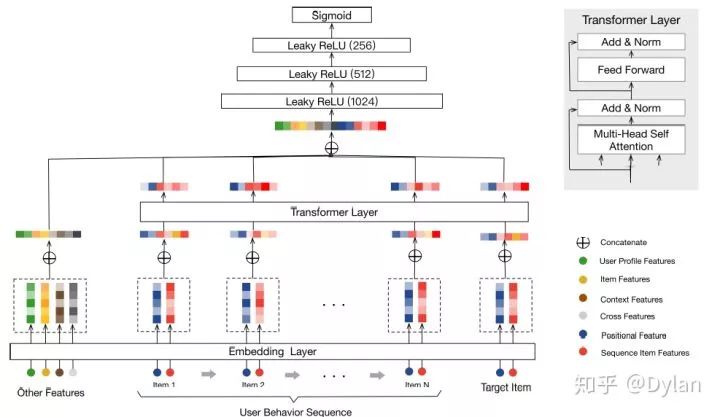
行为时间距离当前时间的diff,作为输入经过embedding layer后和item embedding一起输入到Transformer中,来产生结构化的序列信息。
小结
对Transformer一个直接的应用,通过引入position embedding弥补序列信息缺失的问题,产生再结合other feature做mlp来进行item预测。引入position信息,是Transformer用到序列化推荐时常用的手法,但是是否能够替代掉真正sequence还需要结合应用场景实践分析。
2019 DSIN:Deep Session Interest Network for Click-Through Rate Prediction
背景与动机
用户在session内的行为是内聚的,而跨session的行为会出现显著差异。一般的序列化建模,并不会刻意去区分行为序列中不同session之间的差异。DSIN则是构建了一种session层面的序列模型,意图解决这个问题
模型与特点
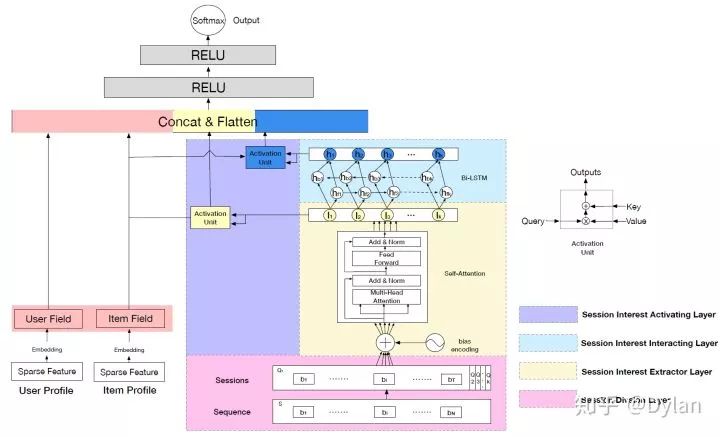
Session Division Layer将用户行为序列切到不同的session中(浅粉色);
紧接着session序列中每个session做一个sum polling,再加上bias encoding输入到Transformer(浅黄色);
Transformer输出的序列,一方面与待预测item通过激活单元做了一个attention的处理(浅紫色),一方面输入到Bi-LSTM(浅蓝色);
经过Bi-LSTM,用户行为才得到真正序列化处理(个人认为transformer处理序列数据,仅仅是将sequence的内聚性做了进一步的加强,所以很多应用还要额外再输入position encoding来强调结构化信息),再和item做activation attention。
小结
在混合复杂模型里面,个人比较喜欢DSIN的整体设计,从motivation上来看更加有的放矢,值得尝试。
参考
1. Rendle S, Freudenthaler C, Schmidtthieme L, et al. Factorizing personalized Markov chains for next-basket recommendation[J]. the web conference, 2010: 811-820.
2. Hidasi B, Karatzoglou A, Baltrunas L, et al. Session-based Recommendations with Recurrent Neural Networks[J]. arXiv: Learning, 2015.
3. Yu F, Liu Q, Wu S, et al. A Dynamic Recurrent Model for Next Basket Recommendation[C]. international acm sigir conference on research and development in information retrieval, 2016: 729-732.
4. Wu C, Ahmed A, Beutel A, et al. Recurrent Recommender Networks[C]. web search and data mining, 2017: 495-503.
5. Kang W, Mcauley J. Self-Attentive Sequential Recommendation[J]. arXiv: Information Retrieval, 2018.
6. Zhou G, Mou N, Fan Y, et al. Deep Interest Evolution Network for Click-Through Rate Prediction[J]. arXiv: Machine Learning, 2018.
7. Tang J, Wang K. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding[C]. web search and data mining, 2018: 565-573.
8. Ni Y, Ou D, Liu S, et al. Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks[C]. knowledge discovery and data mining, 2018: 596-605.
9. Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer.[J]. arXiv: Information Retrieval, 2019.
10. Chen Q, Zhao H, Li W, et al. Behavior Sequence Transformer for E-commerce Recommendation in Alibaba.[J]. arXiv: Information Retrieval, 2019.
11. Feng Y, Lv F, Shen W, et al. Deep Session Interest Network for Click-Through Rate Prediction[J]. arXiv: Information Retrieval, 2019.
12. Lv F, Jin T, Yu C, et al. SDM: Sequential Deep Matching Model for Online Large-scale Recommender System.[J]. arXiv: Information Retrieval, 2019
本文转载自公众号:深度传送门,作者 Dylan
推荐阅读
Google工业风最新论文, Youtube提出双塔结构流式模型进行大规模推荐
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。





