大连理工本科生顶会连刷SOTA被爆作弊!AAAI 2022接收后又面临撤稿,一作仍未发声
![]()
新智元报道

新智元报道
编辑:好困 LRS
【新智元导读】AAAI 2022刚要落下帷幕就又被掀起来了!大连理工本科生一作论文中稿,本该是件值得庆祝的事,但有网友发现了论文中的致命漏洞:声称的无监督方法竟然引入了标签!这让无数被拒的论文情何以堪?导师及二作都出面澄清将会补充实验,但一作仍未公开发声。




啥是行人重识别?

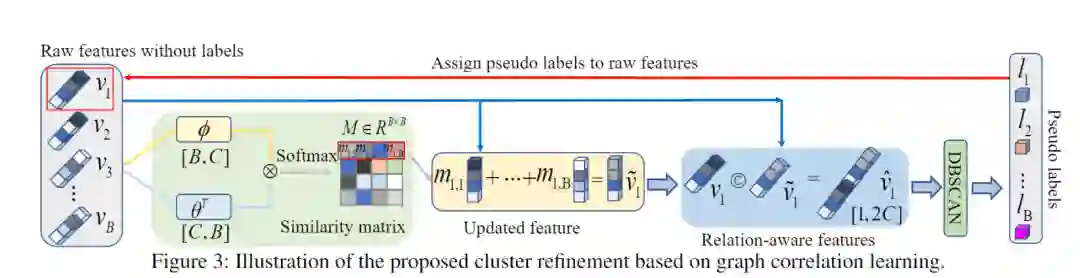
Mind Your Clever Neighbours
特征提取,在每一个epoch开始的时候,通过网络将训练数据集中图片的特征都提取出来。
聚类,通过传统的聚类方法如DBScan, KNN通过特征把图片聚成不同的类别,每个类别给一个标签,就是用来训练的伪标签。一开始的伪标签是很不准的,在训练的过程中,随着网络的精度越来越高,伪标签也会越来越接近真实标签。
图片特征的存储和更新,在网络训练的过程中,随着网络参数的变化,图片的特征也需要进行对应的更新。





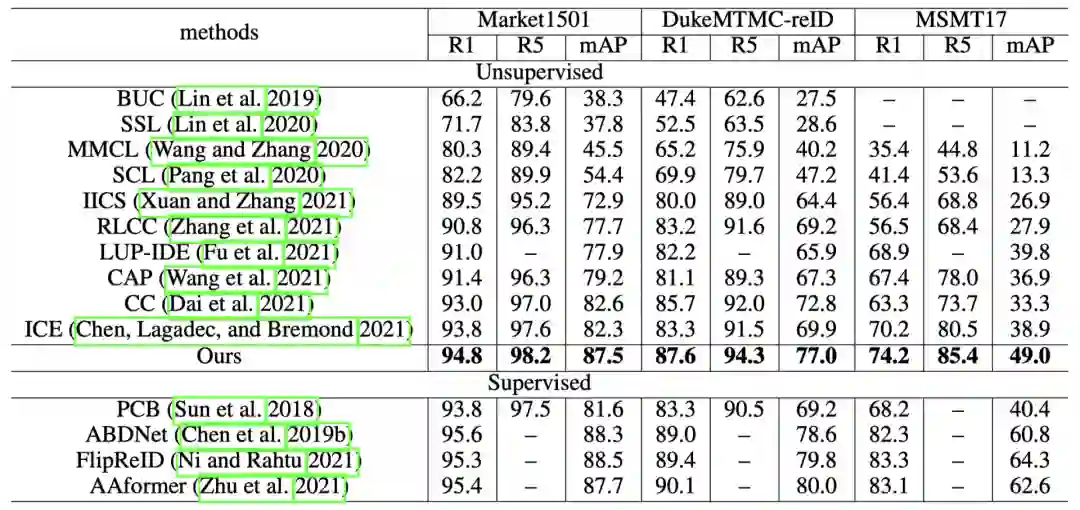
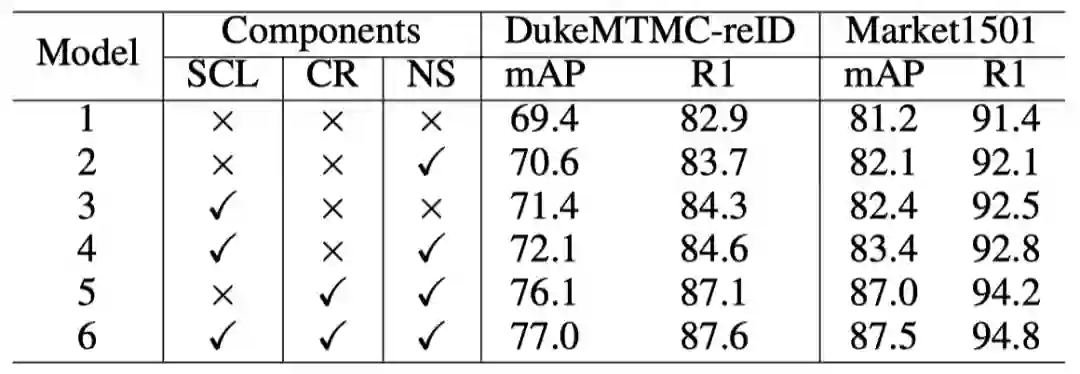
好到不真实的结果
二作和导师回应

-
论文投稿和rebuttal经过学生已在(https://www.zhihu.com/question/504163027/answer/2261562294)中回复,arXiv论文是投稿版本,并未包含rebuttal补充的修改与实验;
-
正在全面的做random shuffle setting的实验,将在第一时间(不晚于12月18日)做好实验说明和分析再来更新答复;
-
完成相关试验后,在camera-ready截止日期前根据新的结论和rebuttal阶段的讨论内容跟AAAI主席沟通是否撤稿。

网友评论



本科生参与科研是对是错?
参考资料:

登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月18日
Arxiv
0+阅读 · 2022年4月15日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月18日
Arxiv
0+阅读 · 2022年4月15日