ICCV2021 | 参数量仅为原来1%,北邮等利用超分算法提出高性能视频传输方法
机器之心专栏
北京邮电大学-模式识别与智能系统实验室
来自北京邮电大学和英特尔中国研究院的研究团队创新性地利用超分辩率算法定义了网络视频传输任务,减小了网络视频传输的带宽压力。
互联网视频在过去几年发生了爆发式增长,这给视频传输基础设施带来了巨大的负担。网络视频传输系统的质量很大程度上取决于网络带宽。受客户端 / 服务器日益增长的计算能力和深度学习的最新进展的启发,一些工作提出将深度神经网络 (DNN) 应用于视频传输系统的工作,以提高视频传输质量。这些 DNN 的方法将一整个视频平均分成一些视频段,然后传输低分辨率的视频段和其对应的 context-aware 模型到客户端,客户端用这些训练好的模型推理对应的低分辨率视频段。通过这种方式,可以在有限的互联网带宽下获得更好的用户体验质量 (QoE)。其中,传输一段长视频需要同时传输多个超分辨率模型。
近日,来自北京邮电大学和英特尔中国研究院的研究者首先探索了不同视频段所对应的不同模型间的关系,然后设计了一种引入内容感知特征调制(Content-aware Feature Modulation,CaFM)模块的联合训练框架,用来压缩视频传输中所需传输的模型大小。该研究的方法让每一个视频段只需传输原模型参数量的 1%,同时还达到了更好的超分效果。该研究进行了大量的实验在多种超分辨率 backbone、视频时长和超分缩放因子上展现了该方法的优势和通用性。另外,该方法也可以被看作是一种新的视频编解码方式。在相同的带宽压缩下,该方法的性能(PSNR)优于商用的 H.264 和 H.265,体现了在行业应用中的潜能。

论文链接:http://arxiv.org/abs/2108.08202
GitHub 地址:https://github.com/Neural-video-delivery/CaFM-Pytorch-ICCV2021
与当前单图像超分辨率 (SISR)和视频超分辨率 (VSR)的方法相比,内容感知 DNN 利用神经网络的过拟合特性和训练策略来实现更高的性能。具体来说,首先将一个视频分成几段,然后为每段视频训练一个单独的 DNN。低分辨率视频段和对应的模型通过网络传输给客户端。不同的 backbone 都可以作为每个视频段的模型。与 WebRTC 等商业视频传输技术相比,这种基于 DNN 的视频传输系统取得了更好的性能。
尽管将 DNN 应用于视频传输很有前景,但现有方法仍然存在一些局限性。一个主要的限制是它们需要为每个视频段训练一个 DNN,从而导致一个长视频有大量单独的模型。这为实际的视频传输系统带来了额外的存储和带宽成本。在本文中,研究者首先仔细研究了不同视频段的模型之间的关系。尽管这些模型在不同的视频段上实现了过拟合,但该研究观察到它们的特征图之间存在线性关系,并且可以通过内容感知特征调制(CaFM)模块进行建模。这促使研究者设计了一种方法,使得模型可以共享大部分参数并仅为每个视频段保留私有的 CaFM 层。然而,与单独训练的模型相比,直接微调私有参数无法获得有竞争力的性能。因此,研究者进一步设计了一个巧妙的联合训练框架,该框架同时训练所有视频段的共享参数和私有参数。通过这种方式,与单独训练的多个模型相比,该方法可以获得相对更好的性能。
该研究的主要贡献包括:
提出了一种新颖的内容感知特征调制(CaFM)模块的联合训练框架,用于网络间的视频传输;
对各种超分辨率 backbone、视频时间长度和缩放因子进行了广泛的实验,证明了该方法的优势和通用性;
在相同的带宽压缩下,与商业 H.264 和 H.265 标准进行比较,由于过度拟合的特性,该方法展示了更有潜力的结果。
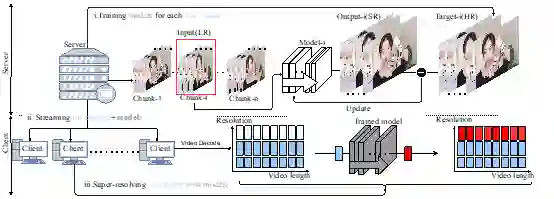
图 1
方法
神经网络视频传输是在传输互联网视频时利用 DNN 来节省带宽。与传统的视频传输系统不同,它们用低分辩率视频和内容感知模型取代了高分辨率视频。如上图所示,整个过程包括三个阶段:(i)在服务器上对每个视频段的模型进行训练;(ii) 将低分辨率视频段与内容感知模型一起从服务器传送到客户端;(iii) 客户端上对低分辨率视频进行超分工作。但是,该过程需要为每个视频段传输一个模型,从而导致额外的带宽成本。所以该研究提出了一种压缩方法,利用 CaFM 模块结合联合训练的方式,将模型参数压缩为原本的 1%。
动机和发现

图 2
 ,其中 i 表示第 i 个模型,j 表示第 j 个 通道,k 表示 SR 模型 的第 k 层卷积。对于随机选择的图像,可以计算
,其中 i 表示第 i 个模型,j 表示第 j 个 通道,k 表示 SR 模型 的第 k 层卷积。对于随机选择的图像,可以计算
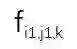 和
和
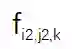 之间的余弦距离,来衡量这两组特征图之间的相似度。对于图 2 中的特征图,该研究计算了
之间的余弦距离,来衡量这两组特征图之间的相似度。对于图 2 中的特征图,该研究计算了
 ,
,
 和
和
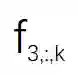 之间的余弦距离矩阵。如图 3 所示,研究者观察到虽然 S1 , S2 ...Sn 是在不同的视频段上训练的,但根据图 3 中矩阵的对角线值可以看出“对应通道之间的余弦距离非常小”。该研究计算了 S1、S2 和 S3 之间所有层的余弦距离的平均值,结果分别约为 0.16 和 0.04。这表明虽然在不同视频段上训练得到了不同的 SR 模型,但是
之间的余弦距离矩阵。如图 3 所示,研究者观察到虽然 S1 , S2 ...Sn 是在不同的视频段上训练的,但根据图 3 中矩阵的对角线值可以看出“对应通道之间的余弦距离非常小”。该研究计算了 S1、S2 和 S3 之间所有层的余弦距离的平均值,结果分别约为 0.16 和 0.04。这表明虽然在不同视频段上训练得到了不同的 SR 模型,但是
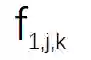 和
和
 之间的关系可以通过线性函数近似建模。这也是该研究提出 Ca
FM 模块的动机。
之间的关系可以通过线性函数近似建模。这也是该研究提出 Ca
FM 模块的动机。

图 3
内容感知特征调制模块(CaFM)
该研究将内容感知特征调制 (CaFM) 模块引入基线模型(EDSR),以私有化每个视频段的 SR 模型。整体框架如图 4 所示。正如上文动机中提到的,CaFM 的目的是操纵特征图并使模型去拟合不同的视频段。因此,不同段的模型可以共享大部分参数。该研究将 CaFM 表示为 channel-wise 线性函数:

其中 x_j 是第 j 个输入特征图,C 是特征通道的数量,a_j 和 b_j 分别是 channel-wise 的缩放和偏置参数。该研究添加 CaFM 来调制基线模型的每个卷积层的输出特征。以 EDSR 为例,CaFM 的参数约占 EDSR 的 0.6%。因此,对于具有 n 个段的视频,可以将模型的大小从 n 个 EDSR 减少到 1 个共享 EDSR 和 n 个私有 CaFM 模块。因此,与基线方法相比,该方法可以显著降低带宽和存储成本。

图 4
联合训练
正如上文中所介绍的,该研究可以利用 CaFM 去替换每个视频段的 SR 模型。但是通过在一个 SR 模型上微调n 个 CaFM 模块的方式很难将精度提升到直接训练 n 个 SR 模型的 PSNR。因此该研究提出了一种联合训练的框架,该框架可以同时训练 n 个视频段。公式可以表示为:
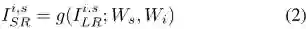
对于 SR 图片
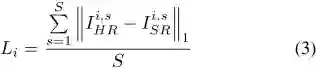
在训练过程中,该研究从视频段中统一采样图像来构建训练数据。所有图像用于更新共享参数 W_s,而第 i 个视频段的图像用于更新相应的 CaFM 参数 W_i。
VSD4K 数据集
Vimeo-90K 和 REDS 等公共视频超分数据集仅包含相邻帧序列(时常太短),不适用于视频传输任务。因此,该研究收集了多个 4K 视频来模拟实际的视频传输场景。该研究使用标准的双三次插值来生成低分辨率视频。研究者选择了六个流行的视频类别来构建 VSD4K,其中包括: 游戏、vlog、采访、体育竞技、舞蹈、城市风景等。每个类别由不同的视频长度组成,包括:15 秒、30 秒、45 秒、1 分钟、2 分钟、5 分钟等。VSD4K 数据集的详细信息可在论文的 Appendix 中阅读,同时 VSD4K 数据集已在github项目中公开。
定性 & 定量分析
主实验对比
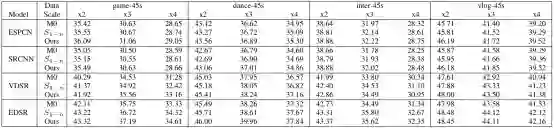
根据上表可以清晰地看到,在不同的视频和超分尺度上该方法 (Ours) 不仅可以追赶上训练 n 个模型 (S1-n) 的精度,并且可以在峰值信噪比上实现精度超越。注:M0 表示不对长视频进行分段,在整段视频上只训练一个模型。
VS codec
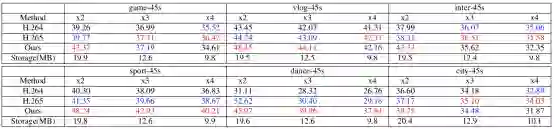
该部分实验对本文提出的方法和传统 codec 方法 (调低码率做压缩) 进行了定量比较。根据上表可以清晰地看到 (红色表示第一名,蓝色表示第二名),在相同的传输大小下(Storage),该方法(Ours) 在大多数情况下可以超越 H264 和 H265。同时视频的长度越长,SR 模型所占传输大小的比例越小,该方法的优势越明显。
定性比较
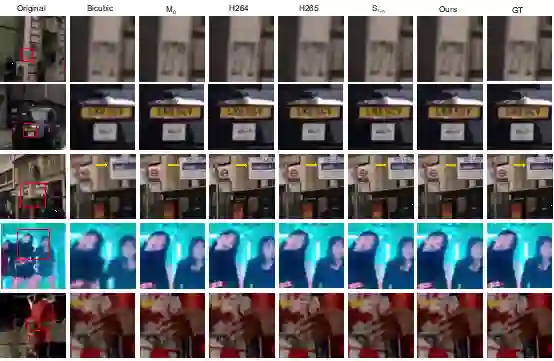
总体而言,该论文创新性地利用超分辩率算法定义网络视频传输任务,目的是减少网络视频传输的带宽压力。利用内容感知特征调制 (CaFM) 模块结合联合训练的方式,对每个视频段对应的模型参数量进行压缩(1%)。为后续的研究者,提供了新的研究方向。
与吴恩达共话ML未来发展,2021亚马逊云科技中国峰会可「玩」可「学」
2021亚马逊云科技中国峰会「第二站」将于9月9日-9月14日全程在线上举办。对于AI开发者来说,9月14日举办的「人工智能和机器学习峰会」最值得关注。
当天上午,亚马逊云科技人工智能与机器学习副总裁Swami Sivasubramanian 博士与 AI 领域著名学者、Landing AI 创始人吴恩达(Andrew Ng )博士展开一场「炉边谈话」。
不仅如此,「人工智能和机器学习峰会」还设置了四大分论坛,分别为「机器学习科学」、「机器学习的影响」、「无需依赖专业知识的机器学习实践」和「机器学习如何落地」,从技术原理、实际场景中的应用落地以及对行业领域的影响等多个方面详细阐述了机器学习的发展。
点击阅读原文,立即报名。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


