没有模型如何进行强化学习——蒙特卡洛方法
产业 学术 趣玩
每周推送原创潮流机器人资讯
我们获得授权翻译CMU课程 10703 Deep Reinforcement Learning & Control,这是第四讲。
感谢Katerina Fragkiadaki教授的支持。
翻译贡献者:
李飞腾,HFUT,Mechatronics (1-9)
李政锴,HIT,CSE (10-16)
王馨,CUHK, rehabilitation robotics (17-21, 39-41)
曹瑾,SJTU,Robotics (22-28)
刘乃龙,SIA, Robotics (29-38)
组长&校对:李宏坤
「机器人学家」授权翻译
本讲
概要
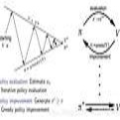
本讲介绍强化学习中的蒙特卡洛方法,即通过试验采样来估计策略优劣。不同于上节课的精确求解法,蒙特卡洛方法并不要求模型已知,因而有更灵活的应用。
应用蒙特卡洛方法的很重要一点是要保证探索性(exploration),为此在训练时往往需要牺牲最优策略,而采用次优但能保证探索的策略。此时我们的策略衡量(Policy Evaluation)得到的不是最优策略的值(value),这是一个值得注意的问题。
如何能一边用次优的策略进行探索,一边计算着最优策略的value?这就是本讲介绍的第二个主题——借助统计学上的重要性采样(importance sampling)来直接衡量最优策略的“异策略方法(off-policy methods)”。
目录
Contents

文档
下载
请在后台回复"10703"获取完整文档下载链接。

总结
Summary
MC 相对于DP(Dynamic Programming, 动态规划)具有很多优点:
可以直接从环境交互中学习(interaction with environment)
不需要完整的模型
不需要学习所有的状态(即不需要引导(bootstrapping))
能较少地受到违背了马尔科夫特性(Markov property,之后会讲)带来的影响
MC方法提供了一种交替策略评估过程(alternate policy evaluation process)
需要注意的一个问题: 需维持足够的探索(maintaining sufficient exploration):为了让策略评估能效力于动作值(action value),我们必须确保连续的探索,以上两者都是以这个为前提的。
英文原版课件下载:请在后台回复“10703”获取下载链接。
本文由微信公众号 机器人学家 编译+整理成文。
转载请联系我们获得许可即可,不尊重作者劳动成果的行为会被举报。
手机长按下图二维码即可关注。