工程师在 AI 实践的路上,可能会踩到这些坑——前 Amazon 中国研发中心架构师蔡超演讲

蔡超,移动营销平台 Mobvista 汇量科技技术副总裁,前亚马逊中国研发中心架构师,拥有 15 年软件开发经验,其中 9 年任世界级 IT 公司软件架构师 / 首席软件架构师,曾领导开发了亚马逊全球新外部直运平台,亚马逊物流 + 系统及基于机器学习的亚马逊全球客服系统智能化项目。
此文为蔡超在全球人工智能与机器学习技术大会(AICon)上演讲, AI 研习社做了不影响原意的编辑。

以下为 AI 研习社整理的演讲全文:
有很多工程师想要投入到人工智能的实践中,最常见的学习过程大概有两种:一种是看到很多的公式就一头扎进去,花时间去研究每一条公式;二是把人工智能看成一个黑盒,就像全自动洗衣机一样,将数据或者一些 csv 文件放到黑盒里面,然后就等结果出来。基本上常见的学习方式就是这两种。
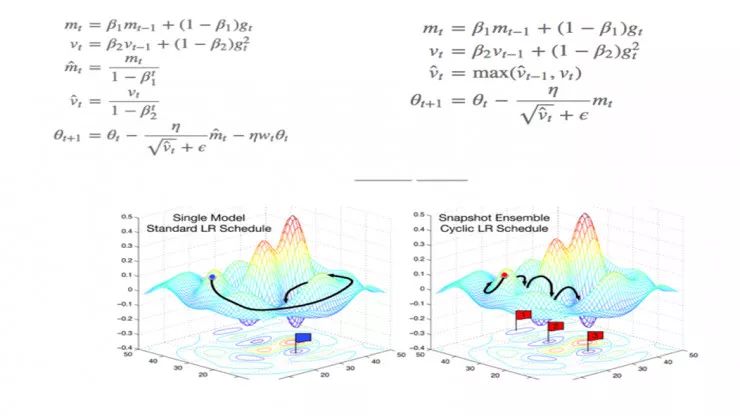
那么我们到底应该怎样学习人工智能?我们先来看看人工智能学习和时间过程中的一些陷阱。

第一,大家一直比较强调模型的 accuracy,初学者认为,准确性可能是一个非常重要的 metric。这里我有个例子,这个模型能够预测未来两周里购买商品的人数。它的准确性有多高呢?经过简短的训练可以达到 98%。我觉得很纳闷,因为这个数据其实并不是这么容易就能预测的。
后来我把他们的数据找出来看了一下,通过两周的历史数据预测,我们发现在一百万的抽样人群里,会有两千人会购买。那么我们来看一下,如果一百万人里面只有两千人会在未来两周购买商品的话,即使你永远回答 no,永远不会购买,你的准确性都有 99.8%,大于它摸索训练出来的 98%。

有意思吗?这只是一个小例子,这样的事情经常发生,在统计学上,这样的数据叫做 no information rate。如果你希望你的模型有意义,那么它的 accuracy 应该大于 no information rate,对吧?
当然,衡量我们机器学习模型的 metric 有很多,accuracy 只是其中一个方面,我们在判断模型好坏的时候不要陷入到这个误区当中,应该根据我们自己的 case 寻找合适的 metrics。

第二个误区,是数据和模型之间的关系。很多初学者对模型有中天生的热爱,他们喜欢学习各种 fanshion 的模型,拿到一些数据之后,他们就找特定的模型来训练,比如最近流行的 Xgboost,反正很多人参加比赛都是用 Xgboost 赢的。
大家在试完一个模型之后看看结果行不行,不行的话再换一个模型试试。每个模型有很多的参数,在加上模型本身,就会形成很多 combination,很多人每天就在浩瀚无边的模型和参数的 combination 里游弋,最终也不一定能够得到一个很好的结果。
很多初学者一开始最常犯的错误是认为模型是第一位的。下面我们通过一个实际的案例来看看到底是数据重要还是模型重要。
这个例子来源于我做过的一个真实项目。亚马逊的用户不论是给亚马逊哪个 site 发邮件,亚马逊的 custom service 都会自动回复一封非常制式的邮件。你也许会觉得,它就是一个邮件模板,通过修改部分用户信息而生成。其实全球亚马逊有 10 万个这样的邮件模板,亚马逊总能在这 10 万份邮件模板中找合适的模板来处理你的 case,但这也是件很麻烦的事,因为很难找到合适的模板。
有人会认为这又什么难的,Google 上有成千上万条信息,用户只要搜索关键词就能 match 到想要的信息。但亚马逊不一样,亚马逊的业务只涉及很少的几件事,可是有 10 万个模板,当你输入一个关键字时,相近的模板会全搜索出来。我们全球亚马逊的客服人员平均工作年限是七个月,所以说大部分都是新手,对于他们来讲,筛选这些模板非常困难。
有开发者会想,这不就是分类问题吗?我们找一个分类的模型把这些事办了不就行了?我不知道大家是否有共识,就是大家在看吴恩达的机器学习课程或者网上的分类问题例子,都是在讲患者是否得癌症,明天的天气怎样,分类数比较少,甚至是二分类。
其实有句话是这样说的:只要能把一个问题抽象成二分类的问题,那么基本上就胜利了一半。我们刚才谈到,我们有十万个模板,那就是十万分类问题,或者说你想要缩小范围,比如十个模板分一类,那也有一万个分类,这处理起来也是非常困难的。
回到这些模板的使用数据上,我们发现 TOP 10% 的模板其实能够 cover 到 80% 的 case,甚至是 80% 以上的 case。那么我们后来怎么做的呢?我们用上周 TOP 10 的模板为下周做推荐,这样的准确率能到 56%。后来我们在此基础上叠加一些学习算法做更有效的筛选,最终的准确性能够提高到 80%,这是一个非常不错的成绩。
通过这个例子可以看到,我们并没有去寻找 fanshion 的模型,而是从数据出发,通过数据就能解决很多问题。在现在这个大数据机器学习的时代,大多数情况下,你都会发现数据远比模型重要得多。

另外,还有一个误区,大家在训练模型的时候喜欢找很多的 feature。大家总以为 feature 越多越好,把 feature 之间的组合关系做得非常巨大。我在网上找了一个广告的数据集,这个数据集很多书籍都在用,那我通过这个数据集来告诉大家, feature 和模型优劣的关系,是不是 feature 越多你的模型就会越好呢?
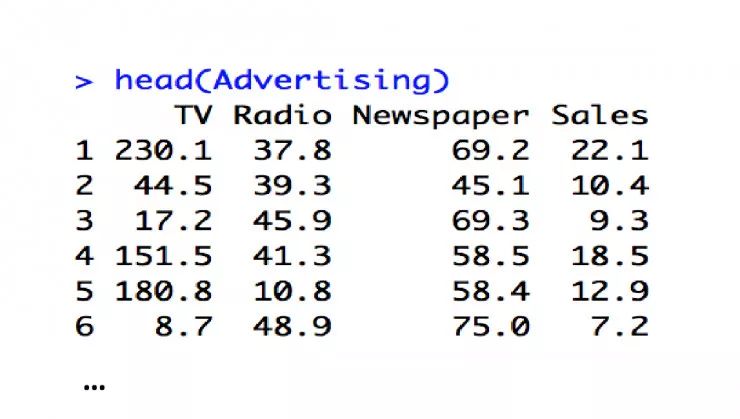
这个数据显示的是在电视、收音机、报纸上投放的广告 sales 的预测。你们可以看到第一个 sales 就到代表我利用的所有 feature。那么做完之后,我们看到 PPT 的下脚,它的均方根误差 RMSE 是 1.723615。那 Rsquared 是什么呢?我简单解释下,它是用来标识这个模型的拟合程度,取值在 0 和 1 之间,越接近于 1,拟合程度越高。

当我们把 newspaper 的 feature 去掉的时候,我们发现 RMSE 从 1.723615 降到了 1.676055,Rsquared 也得到了一个提升,变成了 0.8975927。所以说,我们在减少 feature 的情况下有时候会得到更好的效果。

另外一个误区,很多人在学习机器学习之后,认为机器学习都应该是监督学习,而第一件是就是要找标注好的数据。其实机器学习本质上来将就是从数据中找出 pattern,并不是所有的问题都适合用监督学习解决。Cluster,聚类,就是非常重要的一种学习方式,其实还有关联关系等,在这里我们简单介绍下聚类。

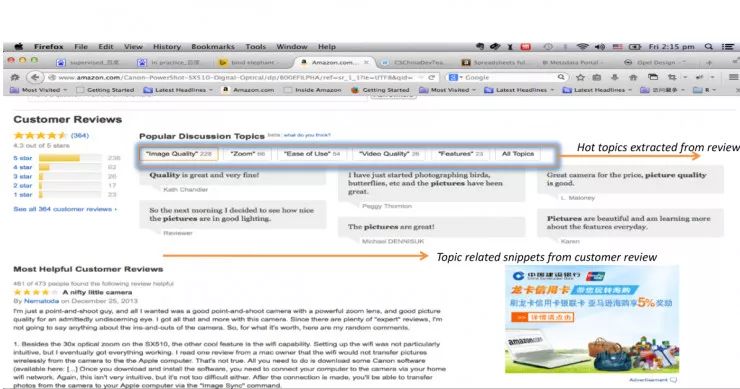
这是亚马逊网站上的客户反馈,通常情况下,不同的人对于各个商品有不同的关注度,比如说买相机,有人关注镜头,有人关注成像质量。那么每个人在挑选相机的时候就会有不同的侧重,关注点会不一样。
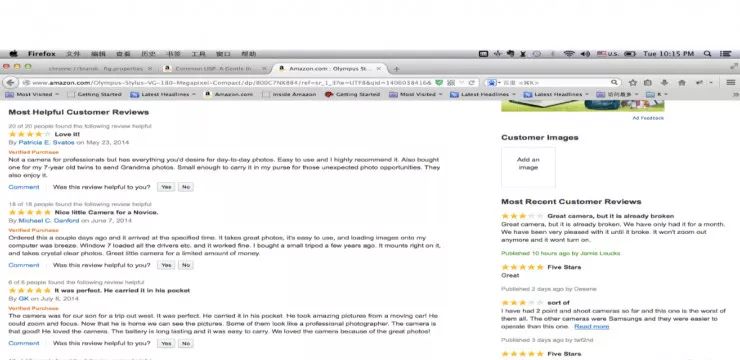
大家可以看看,下面这个页面和前一个页面有一点点不同,橘黄色框选中的地方是 Topic 栏,系统会自动 extract 你关注的 topic,上面列出来的也是跟所关注的 topic 相关的。这是通过聚类的方式完成的,聚类是机器学习的一种,但不是监督学习。
OK,下面我们来讲一讲机器学习应用和实践中的一些挑战。

第一个是比较常见的挑战,我相信很多人都遇到过这个问题,比如你要做一个异常检测,监测每个应用系统是否发生了异常,那么在 99% 的情况下,甚至是 99.99% 的情况下,这些系统都不应该有异常。如果,50% 的系统有异常的话,那该系统根本就没法上线。那你知道的,我们一般用 imbalance data 去训练的时候,都会呈现出我们刚才所说的,类似 accuracy 那样的情况。
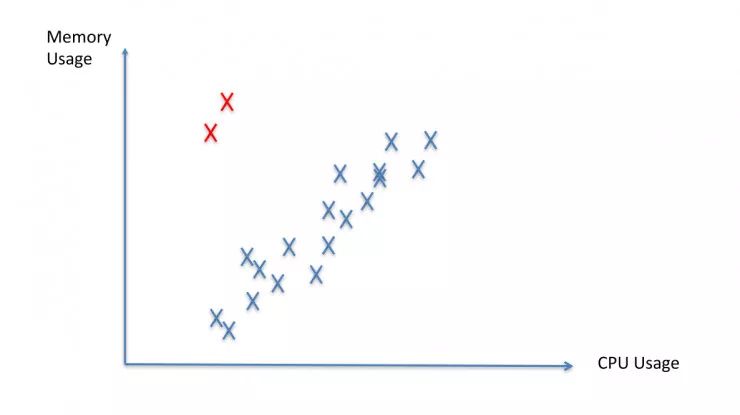
开发者训练一个模型,从整体上来看会倾向于获得高 accuracy,在这样的情况下你的模型就没法获取你想要看到的那个异常,这种模型非常难训练。在一般情况下,开发者会采用 scale up 或者 scale down 的方法,就是说我去将这个问题的数量复制一下,或者是生成一些重要的调档。有个数据是 1:5 或者 1:3,我问西雅图的同时为什么是这个数据?他们说:「It's 啊 magic number」,没有证据证明为什么,但是这个数据总能获得成功。但整体而言,这个问题都是非常困难的,以 scale down 为例,你 scale down 的时候会失去大量的数据。

接下来我们在看看,有时候我们并不需要用传统的监督学习来解决问题,有种技术叫做 Anomaly Detection。
CPU 或者是 Memory 利率的分布有可能是一个正态分布,或者经过 log 变换后变成一个正态分布。正态分布一个很大的特点就是两个方差之外的可能性只有 5%,你可以认为这个 5% 就是异常点,甚至你可以将两边扩展到三个方差,进一步缩减异常点的范围。如果你们的 CPU 和 Memory 是独立变换的话,你只要把它们相乘就行了,这是非常简单的。
当你有大量的数据,数据集的正样本数和负样本数悬殊很大的时候,应该考虑下研究它们的分布,看看能不能用 Anomaly Detection 分布既简单又高效地解决问题。

如果样本数相差不太大的情况下,当然,我们可以尝试使用传统的监督学习。
还有一个对初学者常见的挑战,我们找一个模型并不难,有很多现成的模型可用,甚至我们可以借鉴别人训练好的模型权值,但是对于一个初学者来讲,困难的是 feature 的预处理。
当我们拿到 feature 的时候要把它中心化、缩放,我们刚才也谈到了,feature 不是越多越好,我们要选择有效的 feature,将这些 feature 组合在一起。更常见的是一些异常值和丢失数据的处理,这些需要很高的处理技巧。
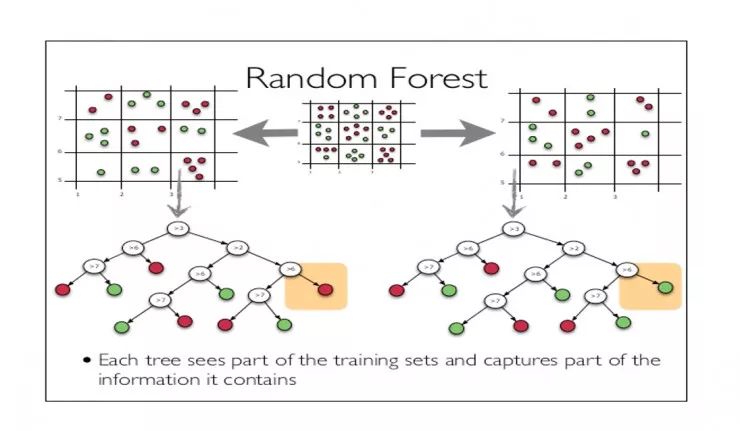
这里我给大家一个小小的建议,当你想快速实验一个不太拿手的模型时,我建议使用树模型,尤其是 Random Forest 模型。Random Forest 能够自动帮你筛选这些 feature,而且会告诉你 feature importance。
好,下面我们谈一些更具挑战性的问题,我会用实际项目给大家解释这些挑战。

第一, 有些图片在某些国家和地区是不能出现的,比如在有的地方展示内衣时,是不能穿在人身上的。面对这样的情况,我们可以对图像做变形、模糊化等处理,由一个样子变成多个样子。

另外一个挑战是什么呢?你的标注数据较少,没办法做更多的实验,目前来说有没有深度学习网络的 bible 或者是一种 pattern 来告诉你最佳的结构是什么。只是大家不断地在探索。

相关的 paper 有很多,大家随便拿一份 paper 来看,讲的都是作者用一个数据集的时候取得了一个非常好的效果,然后把这个 structure 粘贴上来,但是并不知道其中的原理。这样的 paper 非常多,昨天我听一个老师说,现在高中生都能写一篇论文发表,我看也有这个趋势,因为大家都不太追求解释这个 Why。
那么在这样的情况下可以使用一些现成的,良好的模型,一方面可以弥补训练数据的缺少,另一方面可以弥补在模型构建上经验的缺失。
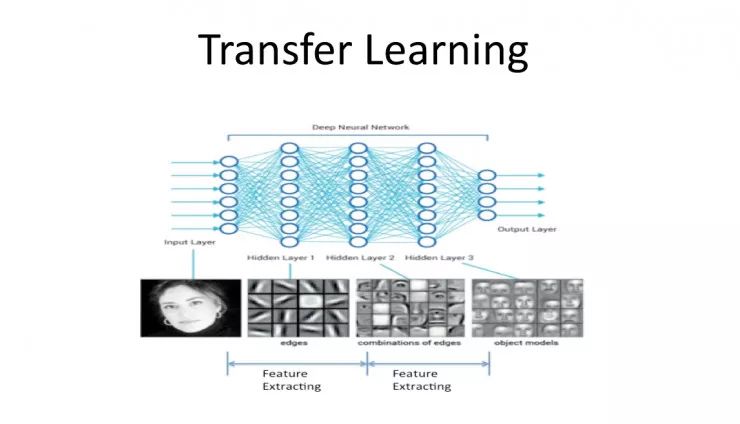
迁移学习是另一种机器学习的方式。它会找到一个现成的模型,在深度学习里较低层模型把 feature extract 出来后,高层的模型可以从较低层的 feature 里把 high level 的 feature 一点一点的 extract 出来。我们可以看到上面这张图片变成 pixel 的 RGB 值之后呢,它的边会被 extract 出来,然后上面会是一些边的组合。
那么最后我来给大家总结一下,如何学习和实践机器学习:我们要从具体问题开始,从数据开始,不要从模型开始,另外,在选择模型时,要从简单的开始。比如现在很多人倾向从深度的神经网络开始学习,而深度神经网络涉及到的权值非常多,你的训练周期会很长,调节的时间甚至是放弃的时间也会更长,会经过非常多的迭代,训练成本也会大好多,所以一定要从简单的开始。

CCF ADL 系列又一诚意课程
两位全球计算机领域 Top 10 大神加盟
——韩家炜 & Philip S Yu
共 13 位专家,覆盖计算机学科研究热点
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
一次 PyTorch 的踩坑经历,以及如何避免梯度成为 NaN
▼▼▼



