GraphSAGE+FM+Transformer强强联手:评微信的GraphTR模型

今天点评微信团队发表的CIKM '20的最新论文《Graph Neural Network for Tag Ranking in Tag-enhanced Video Recommendation》。推荐这篇论文的原因有二:
-
微信团队实际上面临的是一个“ 迁移学习+多任务”的场景。但是,微信团队的解决方案并不是传统常见的 multi-task learning、soft/hard parameter sharing那一套。而是通过将不同领域的节点、关系都建模在一幅图中,通过图卷积,完成知识从数据丰富的领域向数据稀疏领域的迁移,并兼顾两个领域的指标。所以, 本文展现了GNN在迁移学习、多任务学习方面的强大能力,为我们解决类似问题提供了全新的思路。 -
如上所述,微信团队需要在包含多 域信息的异构图上完成图卷积,每个节点要聚合来自多个领域的异构消息。之前传统的聚合方式,如mean/max pooling,矩阵相乘,可能带来异构消息相互抵销而引入信息损失。为此微信团队采用了GraphSAGE+FM+Transformer多种手段, 从不同粒度来交叉、聚合消息,极大提升了模型的表示能力,这种新的消息聚合方式值得借鉴。
接下来,我们先看一下文章所描绘的场景和难点,"设身处地"想一下:如果让你解决这一问题,你会采取什么样的方案?然后再对照文章中所提供的方案,才能体会出作者的"匠心独具",才能真正有所收获,而不是被动填鸭式地等作者把方案扔到你脸上。
场景与难点
微信团队面临的场景是:
-
每个视频都打有若干tag(人工标注或由内容理解算法打上的) -
用户观看视频时,需要有算法从这个视频自带的tag中挑选出与当前用户最相关的若干个tag,展示在视频的下方。 -
用户点击某个tag,会进入一个沉浸式频道,其中展现的全部是与该tag相关的视频
这个场景对于算法的要求
-
推荐出来的tag必须是个性化的。比如对于“小美女的东京美食攻略”这样的视频,对于吃货用户,应该把“美食”排在第一位;对于旅游达人,应该把“日本”排在第一位;对于宅男,则应该把“美女”排在第一位。唯有如此,才能吸引用户进入相应的频道,观看更多同类型的视频。 -
推荐的结果,既要吸引用户点击tag,但是最终目标是为了提升用户的观看时长
而这个问题的难点在于:用户点击视频的行为比较丰富,但是用户点击tag的行为比较稀疏,训练数据不足。
第一个方案:只考虑tag-video的相关性
描述完场景,请你"设身处地"地想一下,如果是你领受到了这个任务,你该如何去做?
如果是我,第一个进入我脑海中的方案,就是训练一个模型,输入视频的多模态信息(标题、封面图、关键帧),输出是与这个视频最match的tag。训练时,拿人工打标的结果作为label。线上serving时,将预测出来的top-K个标签,展示在视频的下方。
这个方案可行,但是其只利用了视频的静态属性,没有用户的信息,所以推荐出来的tag只有与视频在语义上的相关性,完全没有针对当前用户的个性化,不满足业务需求。
第二个方案:引入用户行为
为了克服第一个方案没有使用用户行为的缺陷,我想出第二个方案
-
假设我们已经有了tag embedding -
用户的embedding是其过去有过"正交互"的tag embedding的pooling -
所谓“正交互”,可以是用户过去一段时间内点击过的tag -
但是考虑到user-tag的交互太稀疏,因此可以选用户过去点击过视频所携带的tag -
pooling时,也可以考虑进播放完成度、时间衰减等因素,进行加权平均。 -
线上serving时,拿user embedding在当前视频所携带的tag embedding中寻找Top-K近邻,展示在视频下方。
但是还遗留一个问题,就是第1步中怎么才能得到tag embedding? 我能想到的第一个方案就是用tag的word embedding。
怎么评价这一方案:
-
这个方案,考虑了用户的历史,应该比第一个只考虑tag-video相关性的方案,有更强的个性化。 -
但是拿word embedding做tag embedding,仍然只考虑了tag的语义信息。根据我的经验,也正如文中所说, 用户行为蕴含的信息,要比语义信息,更加重要 -
但是,用户与tag的交互行为太少了,很难在“用户点击tag的序列”上套用word2vec来学习到tag embedding
看GraphTR如何得到优质的tag embedding
讲到这里,终于引出微信的GraphTR模型的思路:
-
GraphTR是为了要学习优质tag embedding,为此要注重利用用户的行为信息 -
但是由于user-tag的行为太稀疏,因此GraphTR需要通过user-video的行为学习到tag embedding
要达成以上目标,也有多种作法。而GraphTR的做法是:
-
将user, video, tag(还加上video的来源media)都放入一个大的异构图 -
通过图卷积,学习到video embedding,再建模video与video之间的相关性(比如在同一个session中播放过) -
因为video embedding融合了tag embedding,因此在优化目标达成之后, 一个优质的副产品就是得到tag embedding
接下来,让我们看看,GraphTR是如何构建这个异构图的?如何传递、融合图上异构节点的信息?如何定义loss?
GraphTR 第1步 :构建异构图
图上要包括:user, video, tag, media (视频来源)这 4类节点。因为用户数目太多,而每个用户的行为相对稀疏,GraphTR将用户按照gender-age-location分成84000组,用user group替代user,在图中建模。
而图上要包括以下5类边(这一版本暂时不考虑边上的权重):
-
video-video:同属一个观看session中的两video之间有边 -
user-video:某视频被某user group一周观看超过3次。 -
因为user-tag行为稀疏,因此图中没有user-tag的边 -
video-tag:video和其携带的tag -
video-media:video和其来源 -
tag-tag:两个 tag属于同一个视频
GraphTR 第2步:聚合异构节点
为了完成user, video, tag, media这四类节点的信息融合,GraphTR设计了3层卷积结构,称为Heterogeneous field interaction network (HFIN)。
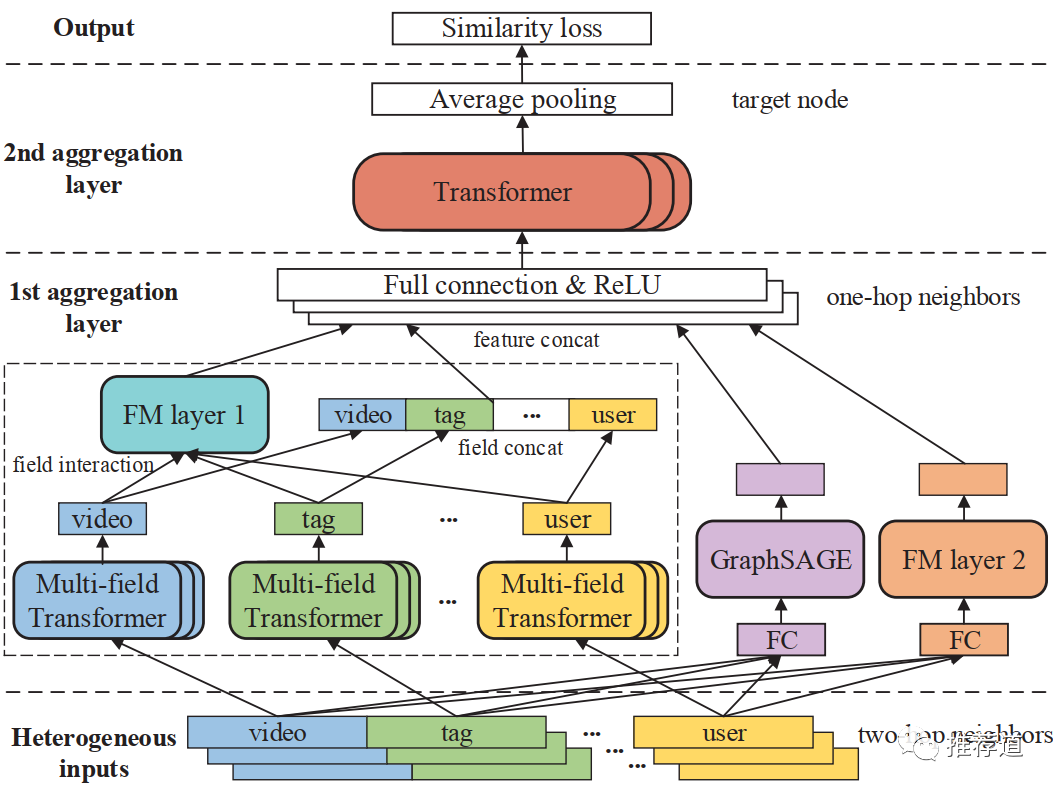
最底层:Heterogeneous Feature Layer
其作用是由3-hop的邻居,聚合生成2-hop邻居上的信息。将2-hop邻居的embedding分为4个域,user/video/tag/media域的特征,分别由节点类型为user/video/tag/media的3-hop的邻居的embedding相加而成。
3-hop的节点的embedding如何而来? 每种类型的节点定义一个embedding矩阵,3-hop的节点embedding从相应类型的embedding矩阵映射得到。
中间层:Multi-field Interaction Layer
这一层的任务是由2-hop邻居的embedding,聚合生成1-hop邻居的embedding。而HFIN采用了GraphSAGE+FM+Transformer三种方式,粒度上从由粗到细,完成聚合。
GraphSAGE聚合
最传统,也是最粗粒度的一种聚合方式。从Heterogeneous Feature Layer可以看到,每个2-hop邻居的embedding,由 (video)、 (tag)、 (media)、 (user)4个域组成。而GraphSAGE不区分各域,而是将所有域拼接成一个大向量 ,拿 在邻居之间传递、聚合。
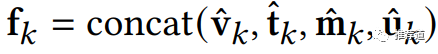
而聚合方式就是标准的GraphSAGE GCN Aggregator。其中 就是destination node自身; 代表destination node的n个邻居之一; 是由GraphSAGE方式聚合得到的1-hop节点embedding。
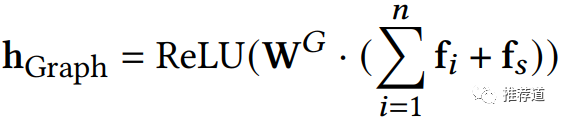
FM聚合
上述GraphSAGE聚合,不区别各域,粒度较粗。而FM聚合,区分各域,因此粒度更细一些。
-
首先,所有2-hop邻居按域平均,再线性变换至统一的维度。以video域 为例,一共1+n个节点,n个邻居 ,1个节点自身
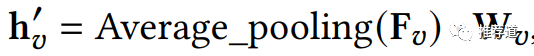
-
然后再拿4个域的平均向量,两两交叉, 让不同域的信息充分融合。 代表element-wise product。 得到的代表由FM方式聚合得到的1-hop节点的embedding
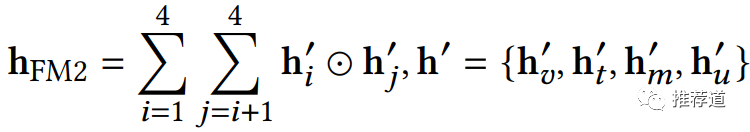
Transformer聚合
这是最细粒度的聚合方式,也是最复杂的。但是,原文中还将它放在第一个讲,让人摸不着头脑,感觉come from nowhere。其实如果把它放到FM聚合后面,就变得清晰了,可以发现Transformer聚合是FM聚合的升级版本。
GraphTR觉得FM聚合时,各域节点(即各域特征)交叉得还不够
-
FM聚合,只有在第2步才做域与域之间的交叉。 -
而在一个域内部,这n+1个特征之间,只有简单pooling,不存在交叉。 -
FM聚合的第1步,每个域average pooling的是,这1+n个节点的原始特征。
Transformer聚合,希望增强各域节点(即各域特征)的交叉
-
第2步,基于FM的域与域之间的两两交叉,还保留 -
Transformer决定在第1步引入交叉。具体方式就是,在一个域的1+n个节点之间进行Transformer变换,重新生成1+n个向量,每个新向量是老向量的加权平均,权重是当前老向量相对于其他老向量的attention score。(一套attention恐怕没有代表性,还引入多头机制) -
再拿生成的1+n个新向量,做average pooling

然后,第2步与FM聚合一样,做不同域之间的两两交叉,最后将“域间交叉结果”与"域内交叉结果"拼接在一起返回 ,作为由Transformer聚合得到的1-hop邻居的embedding。论文的实验结果证明,这个最复杂、最细粒度的聚合,对于模型性能的提升也最大。
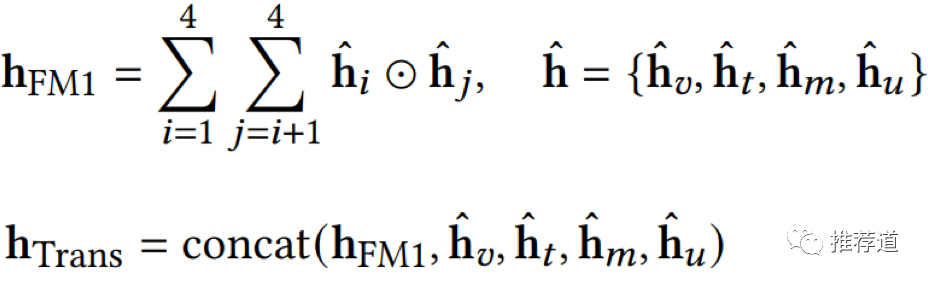
最后1-hop邻居节点的embedding
三种聚合方式,从三种不同粒度对于不同类型的邻居节点上的信息进行聚合
-
GraphSAGE聚合,最粗,不区分域 -
FM聚合,细致一些 ,考虑了不同域之间的两两交叉 -
Transformer聚合,最细,不仅考虑了不同域之间的交叉,还考虑了一个域内部多个特征(异构节点)之间的交叉
1-hop邻居的最终embedding,是这三种聚合结果的拼接
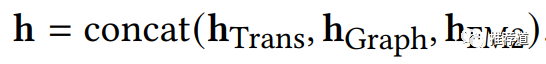
最上层:The Second Aggregation Layer
这一层负责由1-hop邻居节点(1个target node自身,m个邻居节点,一共1+m个)的embedding(下边公式中的矩阵H),生成target node上的embedding。聚合方式也是基于Transformer的,
-
根据1+m个原向量,生成1+m个新向量,每个新向量是所有老向量的加权平均,权重是当前原向量与其他原向量的attention score -
再拿这1+m个新向量,取平均,得到target node上的最终向量表示
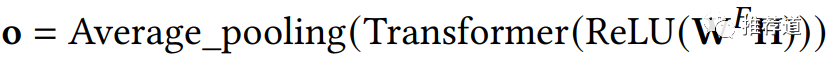
GraphTR 第3步:建模节点间的相关性
通过以上三层卷积,就能够给图上所有类型的所有节点,都产生一个embedding。接下来的问题就是,如何定义优化目标,使这些节点的embedding得到优化?
这一部分的解决方案比较常规,无非就是建模节点之间的相关性,可以有选择是:
-
建模user-tag之间的相关性,user与点击过的tag之间的距离要尽可能小。但是user-tag之间交互的数据太少。 -
建模user-video之间的相关性,user与点击过的视频之间,距离应该较近。但是图上建模的不是单个user而是user group,一个user group包含的用户兴趣太复杂,拿user-goup与video训练,可能噪声比较大。 -
建模video-video之间的相关性, 在同一个session被观看的视频之间,距离要尽可能小。因为video的点击行为比较多,这方面的数据比较丰富,文中采用的是这种方案。
接下来Loss的设计就比较常规了,照搬word2vec,也就是:节点 与其相关节点 的点积大,与随机节点 的点积小。
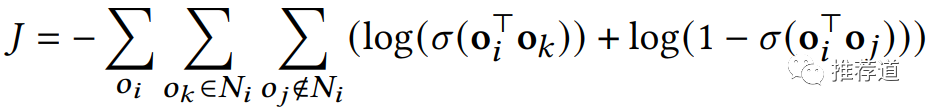
尽管这个训练目标中的 都是video节点上的embedding,但是由于在生成 的过程中,也聚合了tag的embedding,因此待以上目标优化达成后,得到tag embedding也是最优的。
将这些tag emedding代入上文的"第二个方案",即拿用户观看过视频携带的tag的embedding加权平均得到user embedding,再拿这个user embedding在当前视频所携带的tag的embedding中寻找出距离最近的top-k个tag,作为推荐结果显示在视频的下方。因为这些tag embedding蕴含了丰富的user-video行为信息,不仅有助于提升用户对tag的点击率,也有助于提升进入沉浸式tag频道后的观看时长。
总结
至此,微信的GraphTR模型就解读完毕,总结一下这个模型的两个亮点:
-
微信团队面临的是, 数据少的领域如何借力于数据多的领域,同时要兼顾两个领域的优化目标。而他们没有采取传统的“迁移+多目标”的方式,而是通过将不同领域的不同节点、关系建立在一张异构图上, 通过图卷积,使得每个节点的embedding都浓缩了多个领域的知识,达成了“知识迁移+目标兼顾”。GraphTR在微信这种大规模推荐场景下的成功运用,展现了 GNN在迁移学习、多任务学习方面的强大能力,为我们解决类似问题提供了全新的思路。 -
GraphTR采用了GraphSAGE+FM+Transformer多种手段, 粒度上从粗到细,交叉、聚合来自不同领域的异构消息,相比于mean/max pooling、浅层FC等传统聚合方式,极大提升了模型的表达能力,值得借鉴。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


