137% YOLOv3加速、10倍搜索性能提升!这样的惊喜,最新版PaddleSlim有10个
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

允中 发自 凹非寺
本文转载自:量子位(QbitAI)
深度学习模型压缩,又有利器问世。
最新消息,历经一年四个版本打磨之后,百度推出最新深度学习模型压缩工具PaddleSlim1.0。
不仅囊括了深度学习模型压缩中常用的量化、剪裁、蒸馏、模型结构搜索、模型硬件搜索等方法。
还应用到百度人脸SDK中,能够实现在嵌入式设备上,0.3秒内完成人脸检测、跟踪、活体检测、识别等全流程操作。
△ 图1 百度壁虎人脸识别终端
对于将功能强大的深度神经网络部署到移动嵌入式设备端上,以及各种工业场景来说,如此特性都提供了极大的助益,也是当前工业界应用深度学习算法核心需求。
但对于PaddleSlim1.0来说,这只是其最新特性之一。
与2019年第一季度初次发布相比,PaddleSlim在易用性、模型适配、端侧部署、性能提升等方面都有了显著提升。
最核心的体现,在于以下的十个特性。
飞桨PaddleSlimV1.0项目地址:https://github.com/PaddlePaddle/PaddleSlim
一、定制YOLO蒸馏方案,刷新COCO检测任务精度
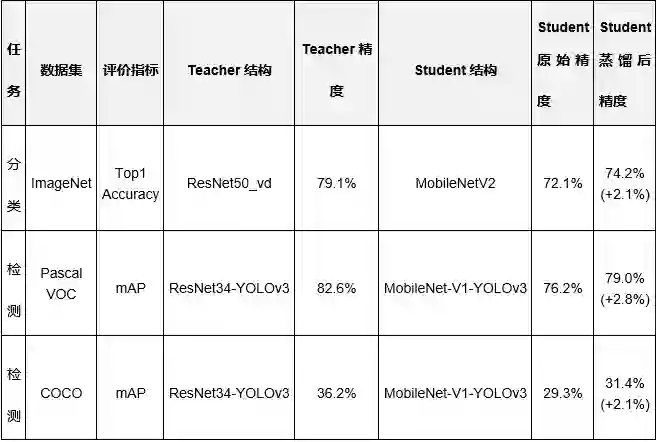
模型蒸馏是将复杂网络中的有用信息提取出来,迁移到一个更小的网络中去,从而达到节省计算资源的目的。PaddleSlim1.0在支持传统蒸馏方法和基于 FSP(Flow of Solution Procedure)蒸馏方法的同时,还支持针对不同的任务,自定义Loss的蒸馏策略。
在ImageNet分类任务上,将MobileNetV2精度进一步提升了2.1%,此外PaddleSlim1.0还联合Paddle Detection开发了针对YOLO系列模型的蒸馏方案,在COCO目标检测数据集上精度提高2%以上。
表 1 蒸馏策略部分实验结果
二、基于敏感度无损剪裁目标检测模型,裁剪后精度不降反增
为了最大化模型剪枝效果,PaddleSlim在之前的版本中实现了基于网络结构敏感度进行剪枝的方案,PaddleSlim1.0支持模型敏感度的多机、多线程并行加速计算。用户可以根据计算结果绘制要裁剪模型的敏感度折线图,然后从中选取一组合适的剪裁率,或者直接调用PaddleSlim提供的接口自动生成一组合适的剪裁率。
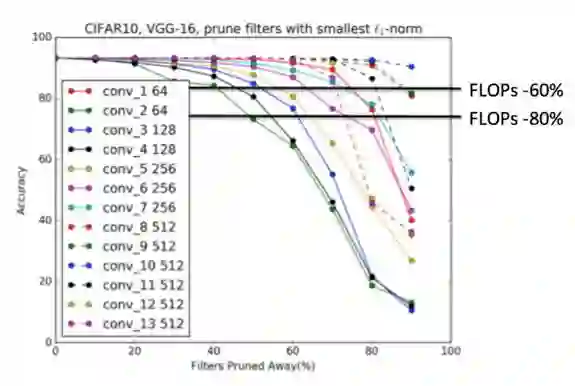
模型裁剪最大的难题是准确找出网络中所有与被剪卷积相关的节点,通常做法是以全局视角进行遍历,但可扩展性不强。PaddleSlim1.0采用以网络节点为视角进行遍历,找出所有与被剪卷积相关的节点,相当于把复杂网络的遍历任务分摊给了各个类型的网络节点,从而提升了可扩展性,在理论上可以支持任意复杂的网络。
在目标检测任务中,可以在不降低模型精度的情况下,进行大比例的剪枝,个别任务剪枝后精度反而有所提升。
表2 基于敏感度的剪裁方法部分实验结果
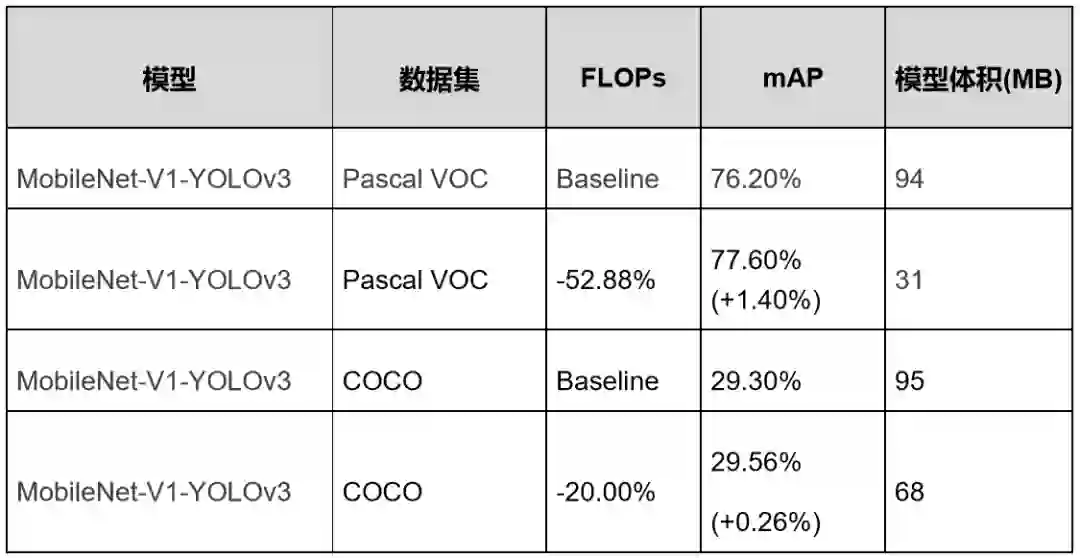
三、支持网络可配置量化,新增离线量化,模型预测速度成倍数提升
定点量化的目的是将神经网络前向过程中浮点数运算(float32)量化为整数(int8)运算,以达到计算加速的目的。PaddleSlim1.0在定点量化的功能上,还支持了网络可配置量化,可以对用户指定的局部网络进行量化,即敏感层继续用浮点数进行计算,以减小精度损失。
为了减少量化训练的开销,PaddleSlim1.0还新增了离线量化功能,大部分任务在不进行re-train的情况下也能达到较高的量化的精度。
PaddleSlim1.0支持对卷积层、全连接层、激活层、BIAS层和其它无权重的层量化。实验证明,定点量化最高可以使模型减小到原来的约1/4,基于Paddle Lite预测部署框架,不同模型可实现1.7倍~2.2倍的加速。
表 3 int8部分定点量化训练实验结果
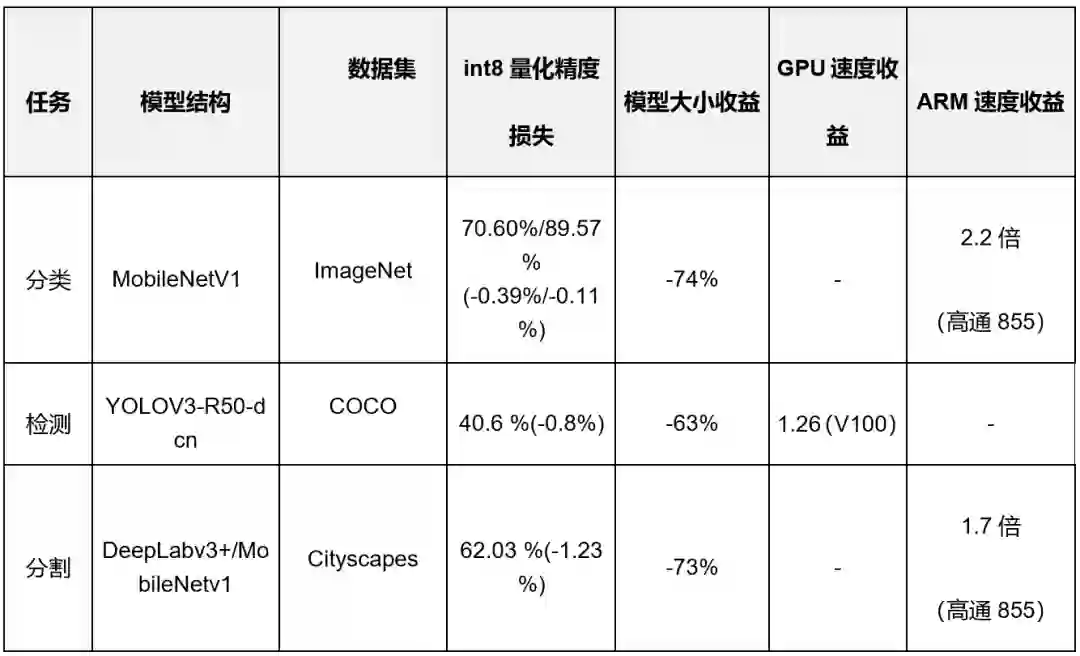
四、全新的NAS架构,搜索更快速、结构更灵活
PaddleSlim1.0开放了更加灵活的NAS API,预定义了更丰富的搜索策略和搜索空间。将搜索空间和搜索策略完全解耦,方便用户扩展搜索策略和搜索空间。
在搜索策略层面,之前版本已经支持模拟退火(Simulated Annealing, 简称SA)算法,相比传统RL算法,收敛速度更快,迭代步骤更少。支持分布式SA搜索策略,确保40GPU卡以内搜索速度线性加速。
本次升级新增了目前热门的基于超网络(HyperNet)的One-Shot NAS自动搜索方法,One-Shot NAS将超网络训练与搜索完全解耦,可以灵活的适用于不同的约束条件,超网络训练过程中显存占用低,所有结构共享超网络权重,搜索耗时加速显著,同时还研发了基于自监督的排序一致性算法,以确保超网络性能与模型最终性能的一致性。
在搜索空间层面,新增对MobileNet、ResNet、Inception等多种类型的搜索空间,同时还支持多个不同类型的搜索空间堆叠进行搜索,用户也可自定义搜索空间。

表 4 ImageNet任务上One-Shot搜索加速收益
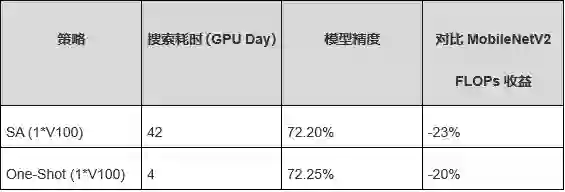
实验结果表明,对比单卡SA搜索策略,单卡One-Shot策略实现搜索速度加快10倍以上。
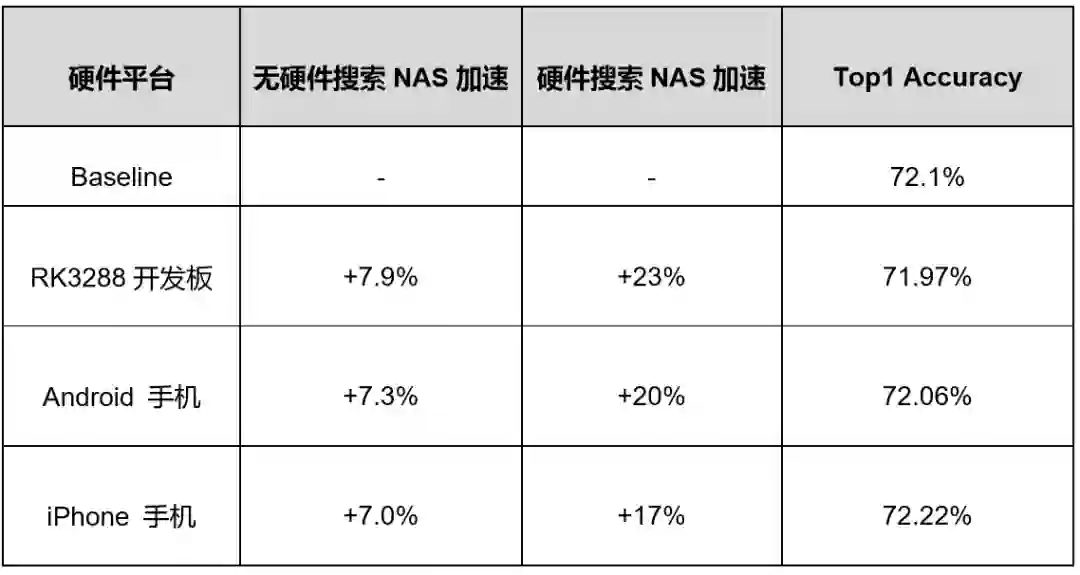
五、创新的硬件搜索技术,为不同硬件自动匹配最优模型
由于不同硬件架构的差异,需要人工进行繁琐的硬件适配工作,硬件搜索就是要解决在硬件适配过程中,为特定硬件定制最优模型结构的问题。
在搜索最优模型结构的过程中,如何快速获得模型在硬件上的实际性能是首先需要解决的问题,传统的FLOPs无法准确表示模型在真实硬件环境上的性能,PaddleSlim1.0支持基于Operator查表进行网络延时预估的方法。
用户只需在硬件上建立Operator延时表,并在网络生成后基于Operator延时表、网络延时评估器、网络结构即可快速获得网络在硬件上的延时情况。
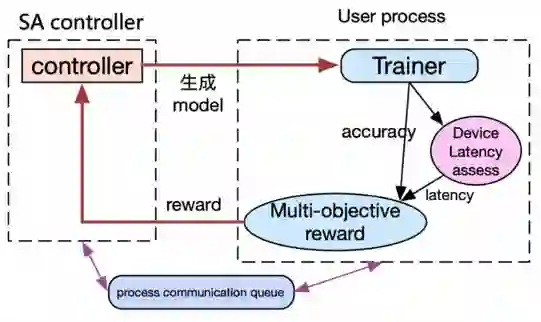
△ 图4 SANAS硬件搜索原理及过程
表5 各硬件平台使用硬件搜索加速后收益(ImageNet任务上相比MobileNetV2)
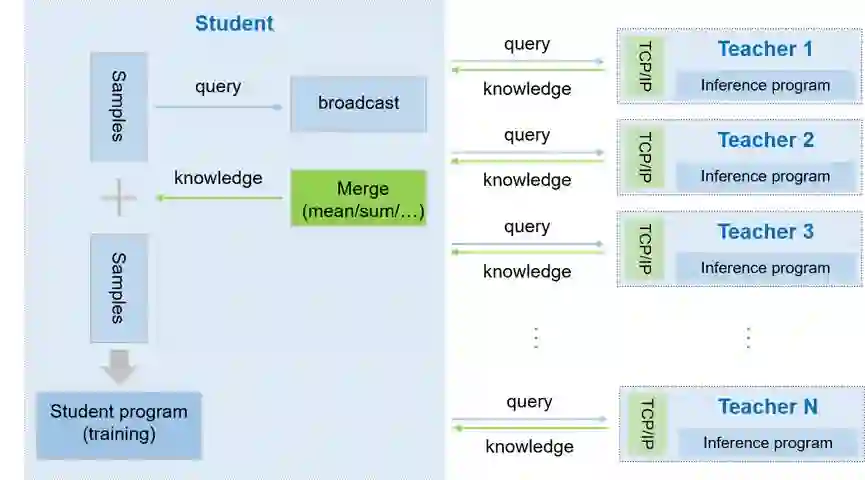
六、新增大规模可扩展知识蒸馏框架Pantheon
支持分布式蒸馏,实现teacher和student在不同GPU或不同机器上进行蒸馏。避免当teacher和student过大,出现无法运行的情况。在单机图像分类蒸馏任务上,该方法能降低蒸馏耗时约50%。
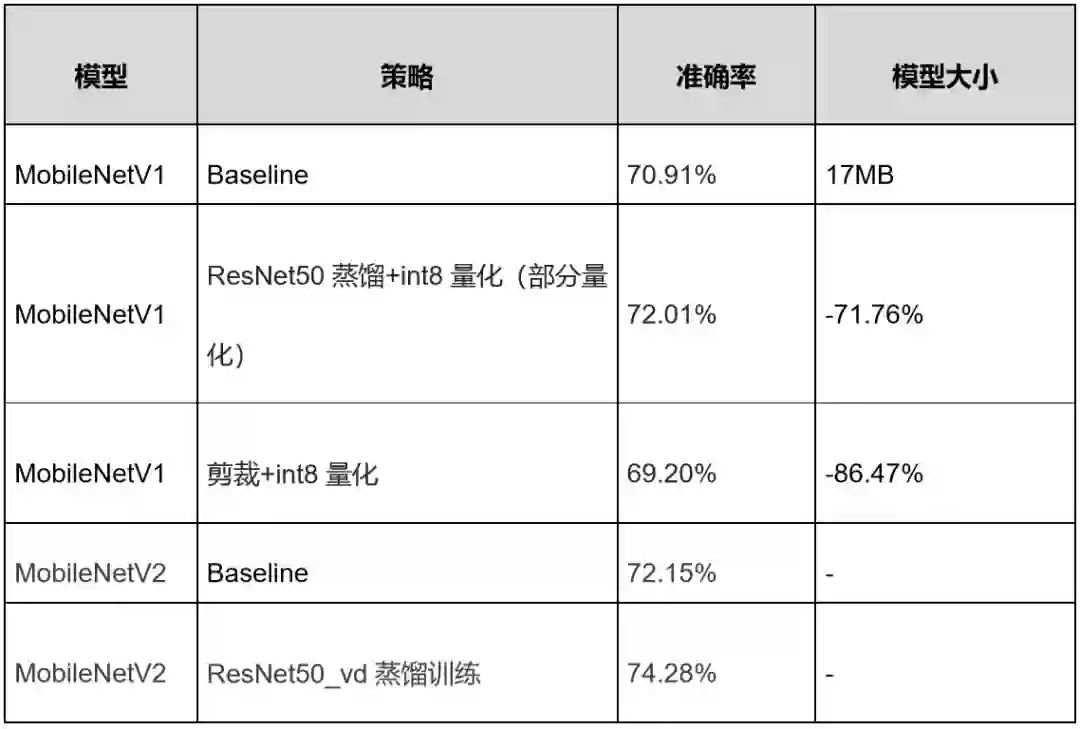
七、支持分类、检测、分割多个场景,多种策略自由组合
PaddleSlim1.0支持多种压缩策略组合使用,以达到最高的压缩比。在分类任务上,实现了模型大小减小70%,准确提升1%。
表6 ImageNet分类任务的部分模型压缩效果
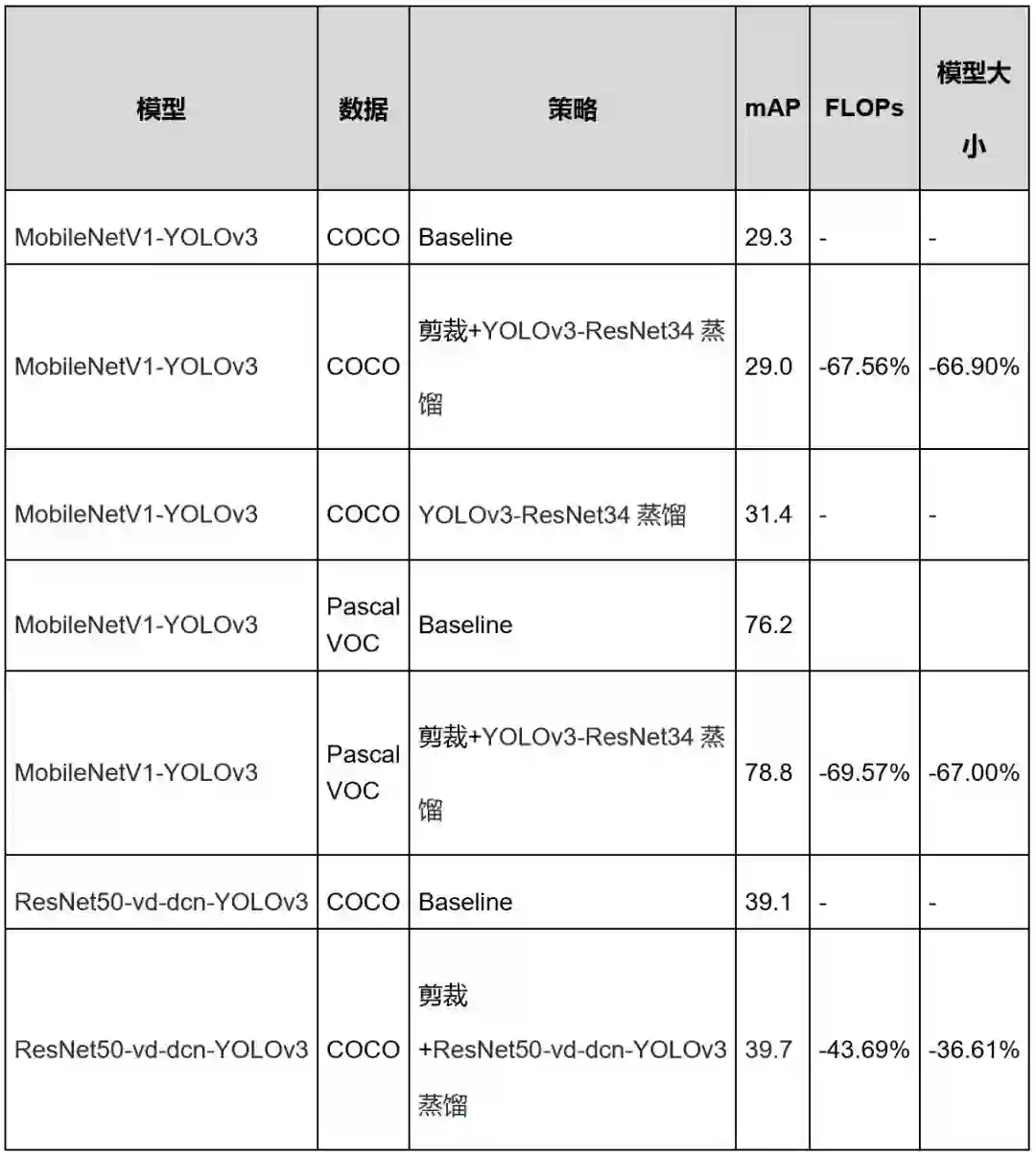
在目标检测任务上,实现了COCO任务提升0.6%,FLOPs减小43%。
表7 目标检测模型部分模型压缩效果
八、实现从“模型训练->模型压缩->预测部署”全流程应用,压缩后的模型可无缝部署到各种硬件场景
PaddleSlim基于飞桨完善的技术生态,实现了从“模型训练->模型压缩->预测部署”的全流程应用,压缩后的模型可无缝落地各种硬件环境。
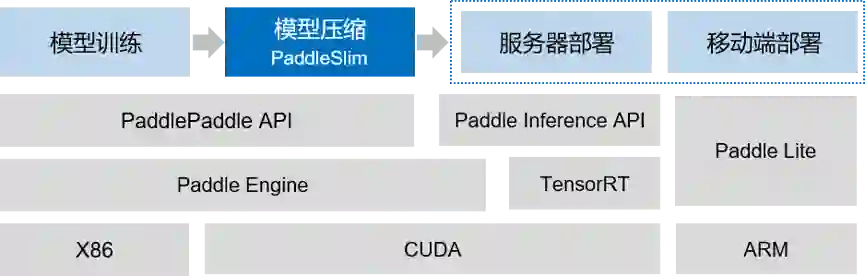
表8 目标检测模型部署在服务端和移动端的耗时数据
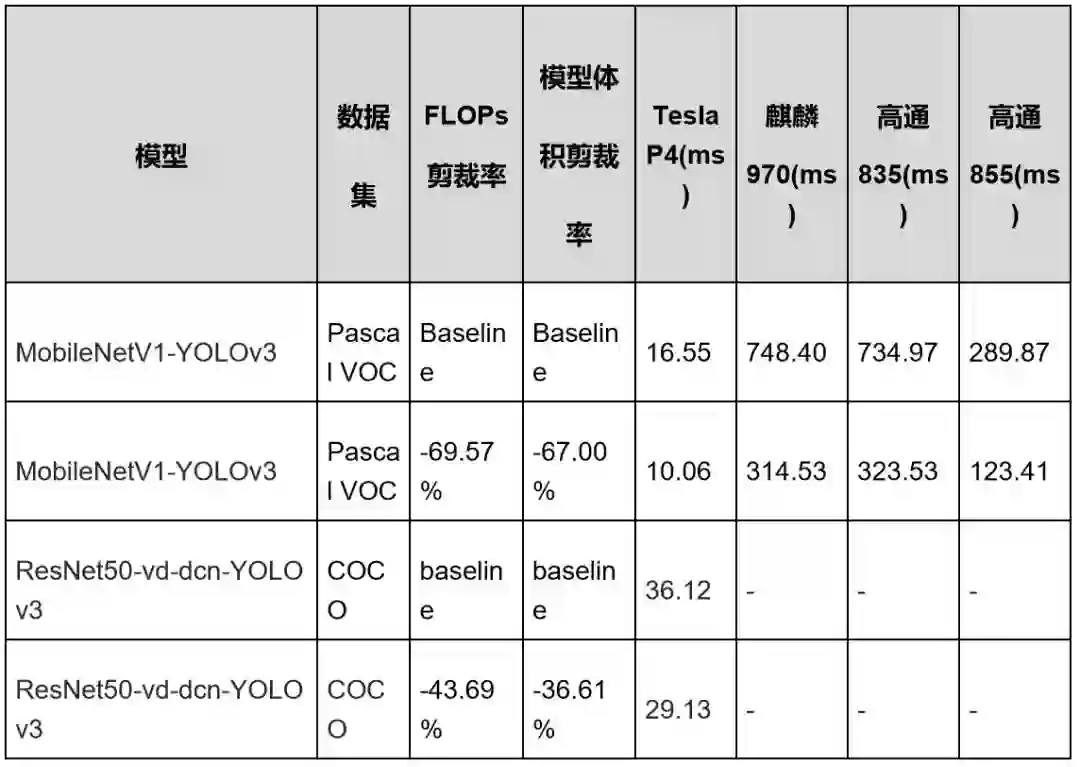
测试数据表明,MobileNetv1-YOLOv3在移动端不同设备上提速约127%~137%。
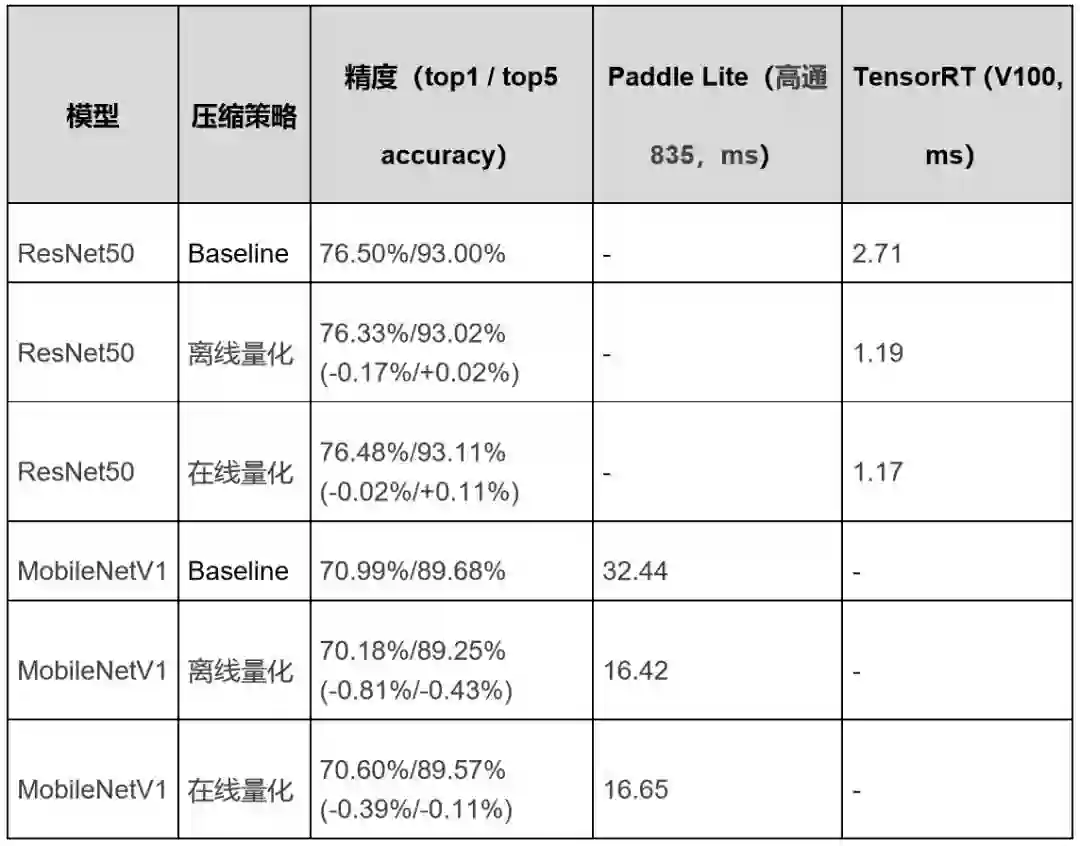
表9 ImageNet分类模型部署在服务端和移动端的部分性能
九、轻量级接口设计,实现各策略解耦,大大缩短编码耗时
PaddleSlim1.0实现了全新接口设计,通过算法独立实现不同压缩方法之间的代码解耦,每个方法既可独立使用,又可混合使用,大大缩短了编码耗时。此外接口设计更加简单,用户只需要在原有工程上添加如下几行代码,即可快速实现模型压缩。
下面我们构造一个MobileNetV1图像分类模型,并剪裁其中两个卷积层,观察剪裁后的FLOPs,代码示意如下:
# 构建网络
import paddle
import paddle.fluid as fluid
import paddleslim as slim
exe, train_program, val_program, inputs, outputs =
slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=False)
print(“FLOPs before pruning: {}”.format(slim.analysis.flops(train_program)))
# 声明剪裁器
pruner = slim.prune.Pruner()
# 剪裁网络
pruned_program, _, _ = pruner.prune(train_program
fluid.global_scope(),
params=["conv2_1_sep_weights", "conv2_2_sep_weights"],
ratios=[0.33] * 2,
place=fluid.CPUPlace())
# 查看FLOPs
print(“FLOPs before pruning: {}”.format(paddleslim.analysis.flops(train_program)))
如果想了解和使用完整代码,请打开下方链接查看图像分类模型通道剪完整代码示例:https://aistudio.baidu.com/aistudio/projectdetail/309947
如果您想了解更多的关于裁剪的代码示例,请打开下方链接查看高级剪裁教程:https://aistudio.baidu.com/aistudio/projectdetail/308077
如上完整代码在百度开发实训平台AI Studio上可在线运行,进入链接的地址后,选择 “登录AI Stuido -> 单击Fork ->启动项目”即可。
十、完善的中英文文档,为全球开发者和合作伙伴提供了更友好的支持
同步开发者建议,完善了中文文档,并新增英文文档,为全球PaddleSlim开发者和合作伙伴提供了更友好的支持。
当前,PaddleSlim已经在业内领先的壁虎人脸识别套件、AI测温等系列产品上成功商用。在第15届百度之星开发者大赛中,PaddleSlim作为模型小型化赛题中的重要工具,被来自全国90%双一流高校和相关研究的1800多支参赛队使用。
(百度之星开发者大赛更多内容打开下方链接:http://astar2019.baidu.com/index.html)
未来,飞桨PaddleSlim愿与广大AI开发者、爱好者和合作伙伴携手,共同探索模型小型化的领先技术,为AI在工业领域中的广泛应用,持续贡献力量。
如果您加入官方QQ群,您将遇上大批志同道合的深度学习同学。官方QQ群:703252161。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档:
官网地址:https://www.paddlepaddle.org.cn
飞桨PaddleSlim项目地址:https://github.com/PaddlePaddle/PaddleSlim
推荐阅读
2020年AI算法岗求职群来了(含准备攻略、面试经验、内推和学习资料等)
重磅!CVer-NAS&模型压缩 交流群已成立
扫码添加CVer助手,可申请加入CVer-NAS&模型压缩 微信交流群,目前已满1000+人,旨在AutoML&NAS、模型压缩&剪枝等内容。
一定要备注:研究方向+地点+学校/公司+昵称(如模型压缩+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!