Facebook 直播是如何承受海量压力的?
挑战
Facebook 在 2016 年底时的月活用户数有 1860 万,Facebook live 的压力很大,有大量的人开直播,有大量的用户观看直播
整体来看,直播的挑战在于:
需要能够同时支持数百万的直播流
对于同一个直播流,需要能够支持数百万的用户
而且直播有一个非常明显的特点,就是非常集中的流量峰值,例如某个名人开了直播,很快就会有大量的用户进来,产生巨大的流量峰值
架构
当很多请求一起进来时,会引发惊群效应,导致严重的流问题,例如延迟、丢包、新用户无法连接 ……
对于这种情况,首先要做的就是阻止请求直接进入流服务器,可以使用多层结构,对请求进行过滤,确保只让必要的请求进入流服务器
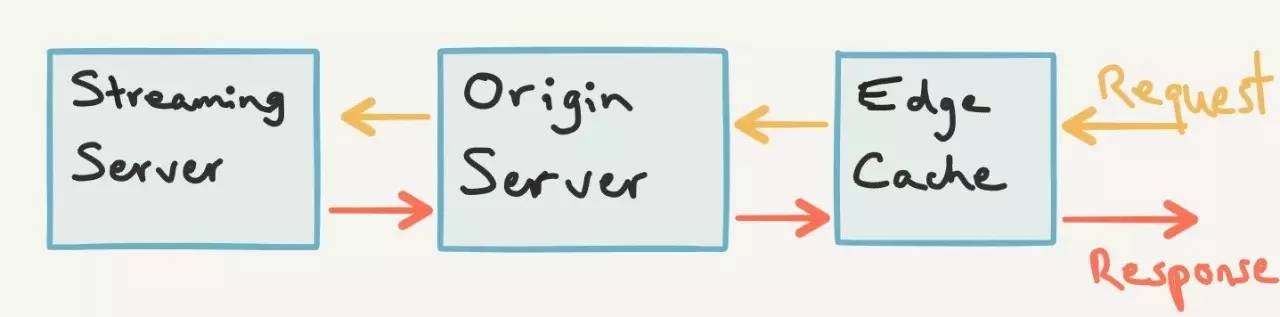
其中,Edge Cache 是散布在全球的,Edge Cache 与 Origin Server 是 多对一 的关系,多个 Edge Cache 可以发送请求到同一个 Origin Server
工作过程:
用户的请求首先到达离自己最近的 Edge Cache server,这个服务器本质上就是一个cache层,不做复杂的处理工作
如果用户请求的数据包就在 Edge Cache 中,那么直接返回给用户
如果不在 Edge Cache 中,那么请求会被转到 Origin Server,它也是一个类似 Edge Cache 的缓存服务器
如果请求的数据包在 Origin Server 中,就返回给 Edge Cache,Edge Cache 再返回给用户,Edge Cache 同时会自己缓存一份
如果 Origin Server 中没有,请求就会被转到 Streaming Server,然后数据返回给 Origin Server,再经由 Edge Cache 返回给用户,同时,Origin Server 和 Edge Cache 都会进行缓存
以后有相同的请求时,Edge Cache 和 Origin Server 就可以轻松处理
这个架构极大的减少了 Streaming Server 处理的请求数量,例如有5个请求顺序达到 Edge Cache,只有第一个请求走遍了全程,从 Streaming Server 拿数据,其他4个请求都可以直接从 Edge Cache 中拿到数据
如何防止请求渗漏?
这个架构虽然非常有效,但还有一定的问题,据统计,有 1.8% 的请求会渗漏到 Streaming Server,对于 Facebook 的规模而言,1.8% 也是一个非常大的数字,会给 Streaming Server 造成极大压力
渗漏原因
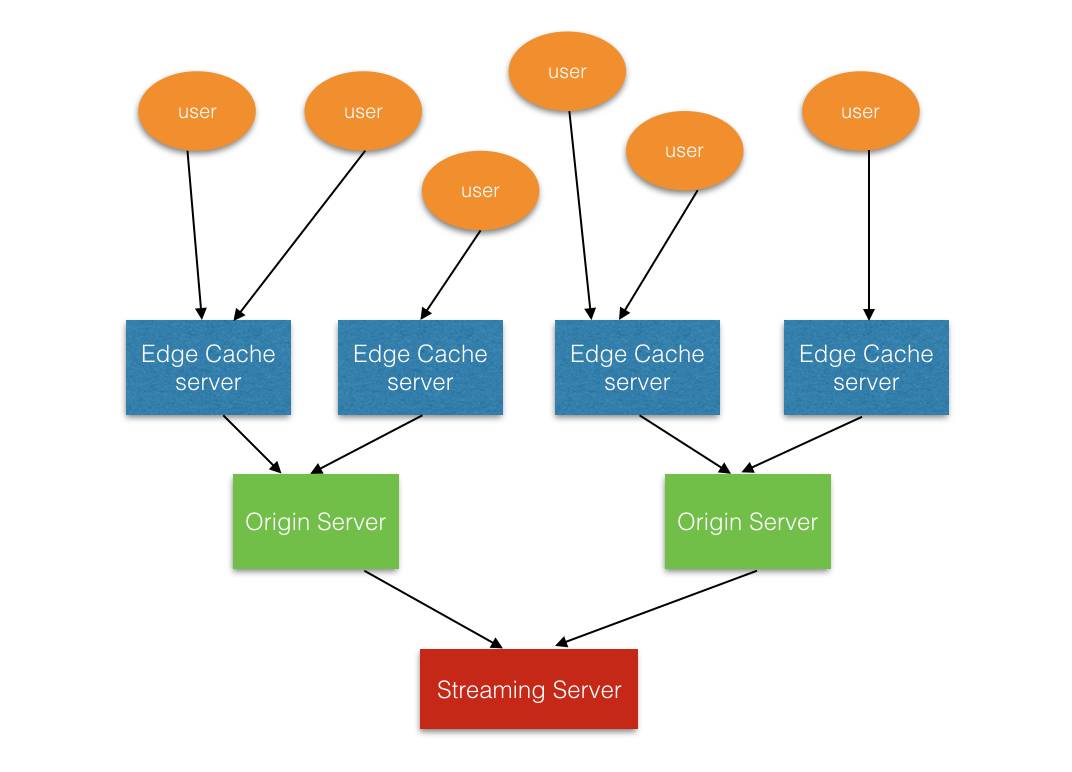
问题来自并发,当有多个请求一起到达某个 Edge Cache,都要请求数据包A,如果没有命中,那么这几个请求就都会转到 Origin Server
同样的,如果多个 Edge Cache 一起请求同一个 Origin Server,请求也会被转到 Streaming Server
所以,Facebook 的高并发特点就会导致有大量的请求渗漏下去
解决办法
Facebook 的处理办法非常简单,当有多个请求同时到达 Edge Cache,如果他们请求的是相同的数据包,那么就把他们归为一组,放到一个请求队列中,并且只让一个进入到 Origin Server(称为请求合并),当响应回来后,先缓存,然后返回给队列中的各个请求
这个策略同样也在 Origin Server 层进行应用,如果多个 Edge Cache 并发请求相同数据,也会进行合并,只有一个会进入 Streaming Server
这样就很好的解决了并发产生的问题
在 Nginx 中,请求合并可以这样设置:
proxy_cache_lock = on负载均衡
还有一点很重要,对 Edge Cache servers 进行负载均衡
在流量高峰期,Edge Cache server 的压力会很大,需要使用负载均衡器对请求进行调配,例如离你最近的那个 Edge Cache 已经在处理20万请求,那么负载均衡器就会把你分配到离你稍远一点,但处理压力较小的按个 Edge Cache
负载均衡器会根据距离与压力进行综合权衡,把用户分配到最合适的 Edge Cache server
小结
本文翻译整理自:
https://designingforscale.com/how-facebook-live-scales
其中的核心思路非常值得借鉴:通过多层结构来过滤请求,从而提高服务器的性能和可用性
点击 “阅读原文” 查看 文章列表




