百万英雄直播答题辅助系统,非OCR实现

向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT数据分析 公众号: datadw
本文代码在公众号 datadw 里 回复 百万英雄 即可获取。
看了网上很多的教程都是通过OCR识别的,这种方法的优点在于通用性强。不同的答题活动都可以参加,但是缺点也明显,速度有限,并且如果通过调用第三方OCR,有次数限制。但是使用本教程提到的数据接口。我们能很容易的获取数据,速度快,但是接口是变化的,需要及时更新。
本文来自 微信公众号 datadw 【大数据挖掘DT数据分析】
二、实战解析
1、背景介绍
百万英雄答题是一个最近很火爆的答题软件,答对12题的人,可以平分最后的奖金。奖金不错,笔者参加过几次,不过获得的都是小奖,最后几块钱的那种。对于不难的题目,能够直接百度出答案的题目,如果有个软件辅助实时给出参考,还是一件很舒服的事情。想干就干,走起!
2、先睹为快
先看下部署效果,通过服务器后端处理,通过前端显示:
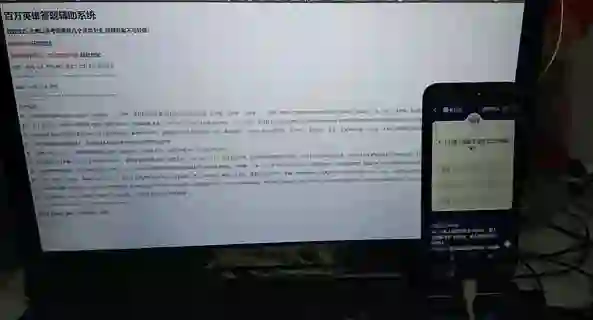
本文代码在公众号 datadw 里 回复 百万英雄 即可获取。
3、西瓜视频APP抓包
对于如何抓包,我想应该都会了,我在手机APP抓包教程中有详细讲解,如有不会的,请暂时移步:http://blog.csdn.net/c406495762/article/details/76850843

在比赛答题的时候,我们可以通过抓包,找到这样的接口(点击放大):可以看到,参数如上图所示。其中heartbeat后面的参数是一个随着场次的增加,逐渐增加的一个数,后面其他的例如iid和device_id是每个人的用户信息,在接口的最后,有个rticket参数,这个是一个时间戳,可以通过time.time()模拟。
2018-1-17更新:据朋友反应,url的有效参数只有heartbeat和rticket参数,用户信息可以不填写。
注意:只有在答题直播开始的时候,才能通过接口抓取到数据,没有直播的时候,是获取不到数据的,是乱码。
通过这个接口获取数据,然后对数据进行解析,在通过百度知道索问题,简单高效。有了这个思想,就可以开始写代码了。
本文来自 微信公众号 datadw 【大数据挖掘DT数据分析】
获取数据和查找答案就是这样,很简单。
本文代码在公众号 datadw 里 回复 百万英雄 即可获取。
将这些部署到服务器上。这是我的部署效果:

部署好后。使用指令运行Node.js服务:
1 |
node app.js |
运行python3脚本:
1 |
python3 baiwan.py |
如果一切都搭建好了,那么这个百万英雄答题辅助系统就可以运行了!
via http://cuijiahua.com/blog/2018/01/spider_3.html
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注



