今日面试题分享:什么是最大熵

什么是最大熵?
参考答案:
解析:
熵是随机变量不确定性的度量,不确定性越大,熵值越大;若随机变量退化成定值,熵为0。如果没有外界干扰,随机变量总是趋向于无序,在经过足够时间的稳定演化,它应该能够达到的最大程度的熵。
为了准确的估计随机变量的状态,我们一般习惯性最大化熵,认为在所有可能的概率模型(分布)的集合中,熵最大的模型是最好的模型。换言之,在已知部分知识的前提下,关于未知分布最合理的推断就是符合已知知识最不确定或最随机的推断,其原则是承认已知事物(知识),且对未知事物不做任何假设,没有任何偏见。
例如,投掷一个骰子,如果问"每个面朝上的概率分别是多少",你会说是等概率,即各点出现的概率均为1/6。因为对这个"一无所知"的色子,什么都不确定,而假定它每一个朝上概率均等则是最合理的做法。从投资的角度来看,这是风险最小的做法,而从信息论的角度讲,就是保留了最大的不确定性,也就是说让熵达到最大。
3.1 无偏原则
下面再举个大多数有关最大熵模型的文章中都喜欢举的一个例子。
例如,一篇文章中出现了“学习”这个词,那这个词是主语、谓语、还是宾语呢?换言之,已知“学习”可能是动词,也可能是名词,故“学习”可以被标为主语、谓语、宾语、定语等等。
令x1表示“学习”被标为名词, x2表示“学习”被标为动词。
令y1表示“学习”被标为主语, y2表示被标为谓语, y3表示宾语, y4表示定语。
且这些概率值加起来的和必为1,即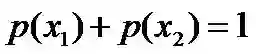

, 则根据无偏原则,认为这个分布中取各个值的概率是相等的,故得到:

因为没有任何的先验知识,所以这种判断是合理的。如果有了一定的先验知识呢? 即进一步,若已知:“学习”被标为定语的可能性很小,只有0.05,即
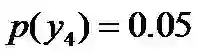
,剩下的依然根据无偏原则,可得:

再进一步,当“学习”被标作名词x1的时候,它被标作谓语y2的概率为0.95,即
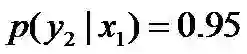
,此时仍然需要坚持无偏见原则,使得概率分布尽量平均。但怎么样才能得到尽量无偏见的分布?
实践经验和理论计算都告诉我们,在完全无约束状态下,均匀分布等价于熵最大(有约束的情况下,不一定是概率相等的均匀分布。 比如,给定均值和方差,熵最大的分布就变成了正态分布 )。
于是,问题便转化为了:计算X和Y的分布,使得H(Y|X)达到最大值,并且满足下述条件:
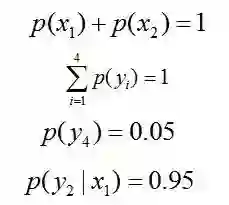
因此,也就引出了最大熵模型的本质,它要解决的问题就是已知X,计算Y的概率,且尽可能让Y的概率最大(实践中,X可能是某单词的上下文信息,Y是该单词翻译成me,I,us、we的各自概率),从而根据已有信息,尽可能最准确的推测未知信息,这就是最大熵模型所要解决的问题。
相当于已知X,计算Y的最大可能的概率,转换成公式,便是要最大化下述式子H(Y|X):
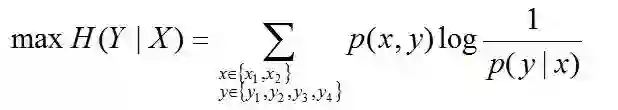
且满足以下4个约束条件:
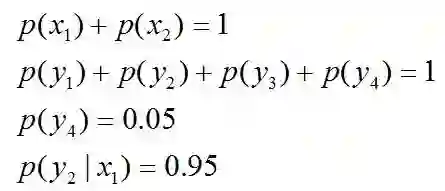
题目来源:七月在线官网(www.julyedu.com)——面试题库——面试大题——机器学习

今日学习推荐
【机器学习集训营第八期】
火热报名中
前三十人特惠价:14199
2019年4月15日开课
报名加送18VIP[包2018全年在线课程和全年GPU]
且两人及两人以上组团还能各减500元
有意的亲们抓紧时间喽
咨询/报名/组团可添加微信客服
julyedukefu_02
扫描下方二维码
免费试听
☟

长按识别二维码
助力“金三银四”
分享一套全体系人工智能学习资料
600G资料 限时限额0元领
小伙伴们可以屯起来,慢慢学习喔~
扫描下方海报二维码
立即领取
☟

▼
点
咨询,查看课程,请点击“阅读原文”
给我【好看】
你也越好看!




