UC浏览器快开之路:如何应对大型APP优化工作周而复始难题?

启动对于 APP 非常重要,本文会先介绍一下启动的背景,以及通常做一个 APP 会面临哪些问题,然后介绍我们采取的优化方案,最后介绍如果要维护现有的成果,需要什么样的性能监控体系。
可能有些人觉得启动并不重要,但是有三个层面说明它的重要性:
第一个是它对用户来说是一个口碑性传播,因为启动对于用户来说,它是用户对于 APP 的第一个认知,如果你第一印象对它不好,可能影响用户对它的口碑传播。
第二个是现在很多 APP 都是需要去做一些合作的,这些合作的前提就是需要我们相互的调取。假如你的启动速度比较慢的话,很多合作方是不愿意去跟你合作的,因为在它的界面上调起你的页面比较慢的话,会影响它的整个体验闭环,也就是说启动速度的提升是合作的一个最起码的筹码。
第三个,也有一些产品会去分析启动速度和日活留存之间的关系。我这边没有一个具体的数据,但是有一个专门的移动报告公司去分析过,移动的日活留存和 APP 的启动性能、卡片性能等等都是有相关性的,所以我们还是有必要去把启动性能做得更好。
虽然我今天分享的主要是针对安卓平台的优化经验,但是相信内容对其他平台也是有一定的借鉴意义的。
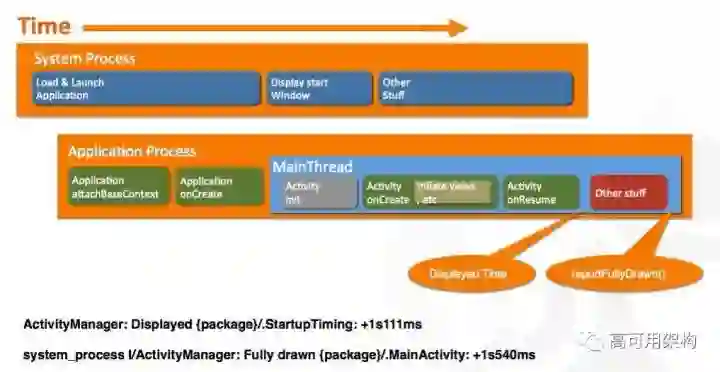
要了解启动,首先要了解 APP 在启动过程中做了什么。启动是系统和我们应用进程之间配合的过程,如图1所示,上面是系统进程做的一些事情,我们把焦点关注到下面的 Application Process 做的一些事情。
安卓平台在我们应用启动的时候固定把那些流程给预留出来了,绿色的部分是系统给到我们去做的一些事情,然后启动要关注的一个时间长度主要是在 Application 进程开始一直到启动结束的时间。
那么什么是启动结束呢?其实系统层面是给了一个 Displayed Time,但是这个时间在很多情况下并没有表明应用是启动的,只是说我们的 Activity,它的 Windows 已经是被绘制了,但是我们应用到业务的 UI 其实是没有完全展现的,所以它在 4.4 版本的时候提供了 API 供我们调用。目前这两个时间点,我们在启动的时候会有下面两个对应的 Log 去显示启动时间,这是我们启动流程的一个过程。
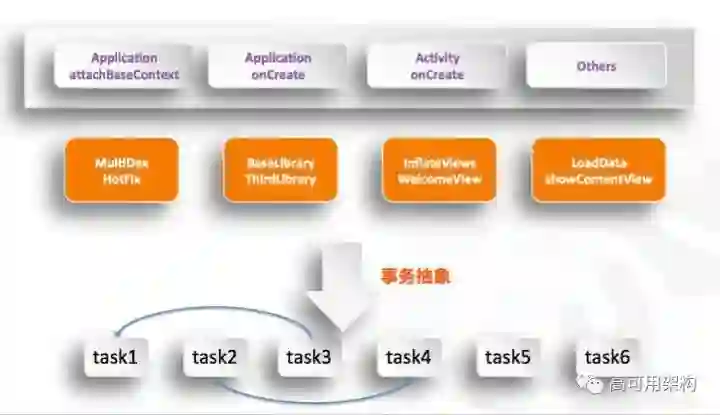
现在关注的是我们能够做些什么,我们能够做的就是上面绿色的部分,非绿色部分是系统帮我们做的,我们只能在里面去插一些我们的事物,去配合完成我们的启动,到真正用户使用的界面去。
通常来说,我们在这些回调里面做一些这样的事情:在 Application attachBaseContext 里面去做一些 MultiDex HotFix 或者 BaseLibrary 这些东西。在 onCreate 里面做一些第三库的加载或者是一些基础库的加载。这样真正到我们的业务 APP 启动的时候,我们专心去做 UI 或者一些数据加载就行了。
我们可以把这个事情给抽象一下:我们启动做了一堆的事情,这些事情有一个隐含的关系。它的隐含关系,比如说系统限制性的预留出这个接口,它有先后顺序,比如说我们加载第三方库,我们在应用去加载我们 UI 的时候,我们可能会直接用第三方库的事情了。
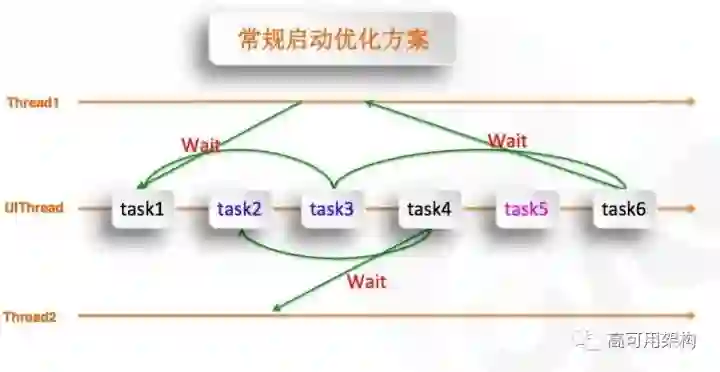
知道启动过程的关系之后,我们该如何去优化它呢?
我们以前是比较常规的去优化这个启动过程,从头到尾去打点、去掐点。比如当我们用那个系统工具去掐一个点的时候,发现有些任务比较耗时(如 task2、task3),我们有没有办法把它挪到其他的线程去做;或者有些任务根本是不需要用到的(如 task5),我们是不是可以在启动过程中就不要做它,这样就缩短了整个 UI 线程做的事情。
但是我们不能忽略一点,就是这些任务是有隐含依赖关系的,比如说这个任务它的 task4 要做,但它依赖于 task2,假如我们把 task2 移到其他线程里去做,这个依赖关系还是要维护起来。包括 task3 也一样的,你挪到另外一个线程去做,同样的这些依赖关系,你也要维护起来,这个维护过程也是一个比较大的工作量。再如 task5 这个任务不做了,我们放到后面去做等等。
这个优化方案,它确实能够带来一些启动速度的提升,比如说我们的 UI 线程它的任务、负载变轻松了,但是它引发的问题也比较多,就像我刚才说的,一个是线程之间的维护,一个是我们的任务抛到后面去,就会给启动后的任务造成压力,也会引起后续任务的卡顿。
我们总结一下会遇到哪些问题:
第一个是并发导致的代码复杂度越来越高了,这个改如何解决?
第二个是并发依赖如何处理?并发虽然是多线程的,但是执行的时候会有一个依赖过程,UI 线程可能要依赖到另外一个线程去做一个事情,不可能说这个依赖建一个锁,那个依赖建一个回调。
第三个是我们每发现一个问题把它抛到业务线程中去,开始是可以的,但是长此以往,可能会造成线程瓶颈。不当的这种操作,还可能会造成线程下滑,因为 CPU 毕竟是有限的,如果你抛得够多的话,它的 CPU 切换反而更耗性能。
第四个是如果我们把任务放到启动后去做了,启动后的卡顿问题也会提升或者有一个明显的突出问题,我们该如何处理。
第五个是我们在做整个启动的时候,发现之前做的优化都是一个事后的工作,我们能不能在这个问题没发生之前就把它遏制住了,而不是等到有问题了,再去检查或者监控问题。
最后一个是其实 UC 浏览器发展这么多年来,它作为一个大型 APP,优化也做过很多轮了,但是每次到做的时候,它是做完一轮之后,然后迭代几个发明之后,又发现数据下滑下来,这是我们大型 APP 经常面临的一个难题。这导致我们优化的工作是周而复始一直在进行的。
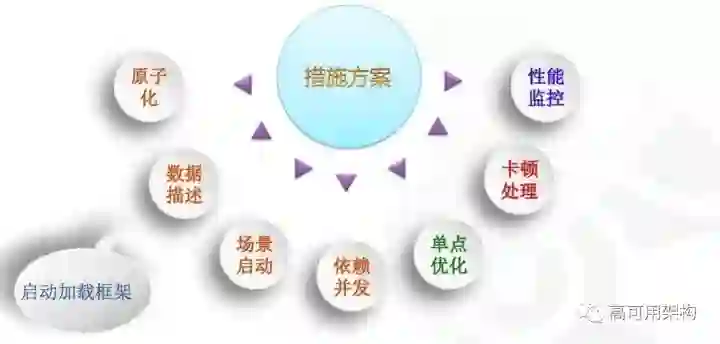
针对这些问题,我提出了几个措施方案,如图 4 所示。其中前四个是属于启动,我把它做成了一个加载的框架,后面的单点优化是对于我们实现部分的一些优化方案,包括整个优化方案导致说有可能把一些任务挪后了或者调整了(因为我们会产生调度),影响后续业务的卡顿,我们该如何处理,包括它的线程监控。
既然是启动加载框架,我们要加载什么?怎么加载?启动我们一开始说了,就是一大堆任务,然后加载无非就是两点,一个是并发加载,一个是延时加载,如果你的任务都要做的话,你只能这样。现在就是看我们怎么更高效、更优雅的加载,我们第一个是启动任务原子化的过程,比如刚才这个任务,我们原子化。要解决它的依赖问题,我们把它的依赖做成一个,至少你原子化完之后,你每个任务是单向依赖的,不会成为一个环形依赖。
第二个是我们会把一些任务尽量地拆分。比如说 6 和 10,以前是一个的话,把它拆完之后,9那个任务就可以很早就执行了,而不用等到 6 和 10 一起做完它才能做,这就间接性的提升了那条链路的执行速度,从而有可能缩短整个有效的关键路径。如果是并发的话,我们把关键路径给缩短了,启动速度当然也就缩短了。
说到底,启动过程就是把这些任务组成的关系是一个有项的乌班图,原子化的目的是要解决它的依赖,然后把它们的任务依赖最小化。当然这边是一个经验值,原则是让至少每个任务,为了维护,我们肯定是要业务类聚,为了更好的调度,我们把颗粒度、它的耗时是控制在 200 毫秒以内。
前面提到了,在启动过程中,假设我们的业务不断迭代,然后用户不断的变,不断的加载,或者不断的异步,导致我们整个启动过程是不太好控制的。现在为了好控制启动过程,我们是想把启动过程用一种数据描述,这样以后我们改启动过程的时候,改的是启动数据。刚才说了,我们启动是一个有项的乌班图,我们以后改就相当于是改这个图就行了,我们启动过程中不用变,因为有一个专门加载器把这个图给自动分解。我把具体的描述大致说一下:
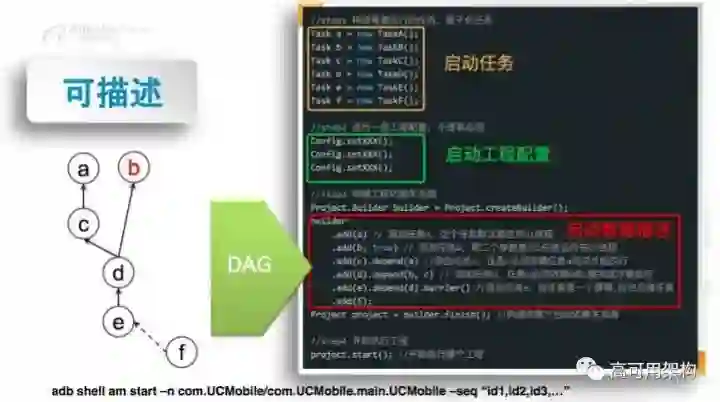
比如说这一块的话(图5),是 add(a),就是我们把一个没有依赖的任务加进来,它可以直接跑的。红色b,比如说它只能在 UI 线程跑,因为有一些 UI 相关的渲染工作,它必须在 UI 线程做的,我们是 add(b),后面有一个 true。比如说它有依赖关系,比如说 c,它有依赖关系,它后面就是 depend(a),或者是 d,它依赖两个,有一个多参的 API 接口,依赖 b 和 c。值得注意的是我们这里还有后面一个接口,是一个 barrier 接口,可能是 Java 里面有一个接口,用的 barrier 这个概念。
这个接口的意义在于有时候有些任务,比如说启动的时候就要用户授权开启权限,这种用户不给过,你的任务也不能往下跑,所以说我们可能会在那里设一个栅栏把它拦住,比如说后面的f就是被拦住的类型。这样的话,以后我们想变了,启动过程中想变了,只是去变这个红色部分就行了。
第二个部分 config 是我们去配置工程的特性,其中有一个是我们可以让所有的任务都在 UI 线程跑,也可以设置线程值的大小等参数。有了这些功能之后,我们启动过程中可以用 adb shell 的 start 命令去指定你的启动序列,就是你可以让 a 先跑,你可以让 b 也先跑这种,这个序列其实是这个图的一个拓扑序列其中一个,这就是我们讲的可描述,这样就会降低以后我们的维护成本,我们的启动过程就维护这个数据就行了。
再是另外一个点,比如说我们讲了一个问题,启动是要把所有任务都加载完吗?明显是不需要的,第一并不是所有人都用所有的业务,可能有些人只是用到小说,有的人只用了视频,全部都加载的话就浪费了不必要的内存,这样启动时间肯定是过长的。
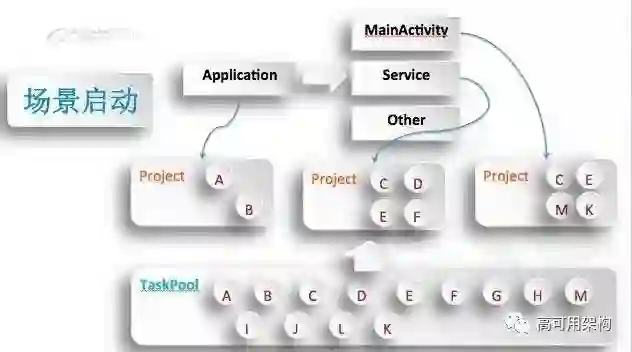
要解决这个问题,我们提了一个场景,就是我们把所有任务都放在一个任务池里面。用户进入,他可能是打开一个网页,也可能是进到浏览器看视频了,当然别的APP也有各种各样的场景,然后每个场景都会有一个入口。对于安卓来说,它是有很多个组件入口的,那么每个组件入口只需要关心它这个入口里面最小的启动集合就行了。
这样有几个好处,第一个是它可以省去那些不必要加载的任务。第二个好处就是假如我们的service组件,它在后台起来了,那么它跟 MainActivity 有一个共同任务 C,假如它起来的时候,用户有可能进到这个界面的时候,它就省去了 C 执行的时间,也一定程度缩短了启动时间,这就是场景化。
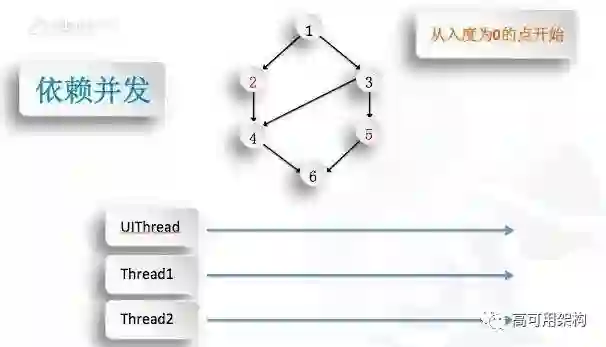
我们刚才说了,它是一个有依赖关系的,我们该如何去并发呢?这里面用到了之前的拓扑分解步骤,就是我们从入度为 0 的点开始。
这里面的入度为 0 是什么意思呢?比如说 1 没有箭头指向它,它是 0,出度就是 1 出去的箭头,就是 1 有两个。如果我们从入度为 0 的点开始,意味着找到那种没有依赖的点,它就可以执行,比如说 1,它是可以执行的。红色部分是必须在 UI 线程做了,我把这个分解步骤给大家演示一下。1 做完了之后,它自然就把它出的两个边给消失,然后这样的话,换成 3,它的入度就为 0 了,然后 2,它是红色,它就进到 UI 线程去跑,然后 2 做完了之后,它会消失,我这里 3 没做,但是你可以看出来,4 这个时候是做不了的,因为它还是有依赖的,所以说它要等到 3 做完,然后 3 的两个边消失了之后,才是 4 和 5 去并发的这种。后面的一样,直到这个工程分解完,我们启动其实就做完了。
这里有几个好处。第一个,它把这种依赖并发的问题给解决了。第二个就是我们这个线程是我们可以控制开的,而且我们入这个线程的顺序是看各个线程的繁忙程度,自己去动态决定的。假如以前是我们自己在不同的点去控制的话,可能会导致这个线程模型并没有现在这么均匀,所以这也是我们去解决并发依赖关系里面过度的问题。
并发虽然是能够在一定程度上缩短我们启动的路径,但是它也会引入一个新的难题。在 UC 来看,启动任务是有近 30 项的,但是加上它的依赖关系,目前它的拓扑排序出来,大概有超过 7 万条拓扑顺序的。如果我们想要保障我们的启动是在线上 100% 没问题,就意味着我们要把这 7 万次的启动顺序都要测一遍,确保没问题,我们才能确定说我们这个启动是没有问题的。明显测这个是有难度的,第一是工作量太大,第二是我们本地的机型根本就模拟不出来说 7 万条的启动序列都能够走得到,所以我们该怎样去保障这个上线的质量呢?
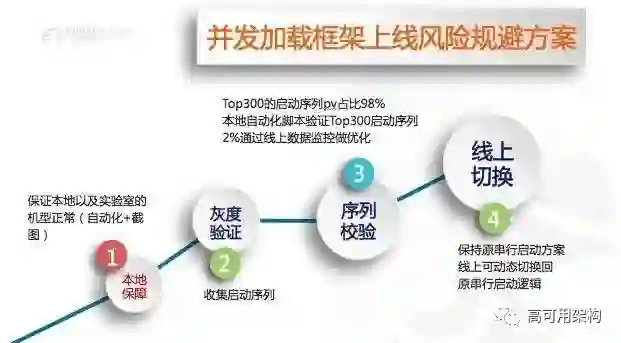
这边有四个步骤去逐步上线。第一个是我们本地做一些自动化的,因为我们刚才说了,我们可以通过 adb 命令去指定一个启动序列的,我们可以随机制定,或者我们可以在这边预跑,保障我们大部分的启动是没有问题的。我们再在小范围去灰度,灰度的目的是去收集线上到底有哪些可能的启动序列。
收集到之后,我们去分析这些序列,我们当时发现数据,我们一共有几十万条数据里面,Top300 这种序列的 PV 占比是占比 98%,意味着我们只要验证这前 300 的启动序列,就至少可以保障线上 98% 的启动次数是没有问题的。剩下的 2%,我们不会说通过这种测试,因为二八原则,这种程度就太低了。
我们是通过线上监控去看,假如说它有那种异常数据反馈回来,我们就去专门验证它的数据,去做这种保障。最后我们还保留着,因为刚才说了,我们是可以串行去执行我们的启动顺序的能力。第三步,发现线程监控的异常率超过了一个阈值,我们可能会把我们并发的路径给切换回来。通过这四种方式去做了上线有保障。
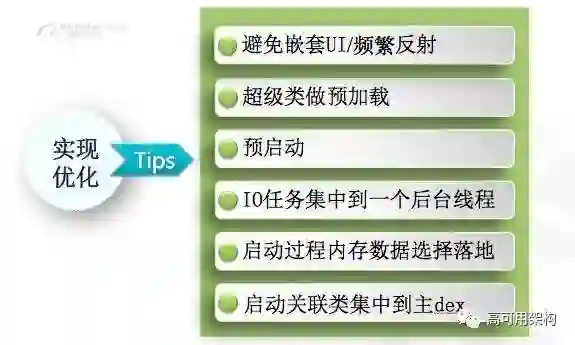
刚刚是从调度方面优化来我们的启动过程。那启动过程其实存在问题代码、或者没有使用良好的系统新特性,新手段,等从这些方面去解决。这里面会常规的有一些优化方案,如图9所示。
值得提的是第二个,超级类做预加载和预启动。超级类做预加载,对于 UC 来说是比较有效的,因为 UC 发展了这么多年,有一个类似超过了几万行的,单这个类,new 它的耗时非常久。所以在 CPU 空闲的时候,我们可以预先把这个类在后台去分类一下,后面真正用到这个类的时候,它很快可以 new 出来。第三个就是预启动这个点,其实也是比较有效的,就是我们的进程可以在后台起来的时候,去预做一部分启动事务。这样一来,在真正用户用的时候,启动做的事情就少一些。后面还有一些方案如 IO 集中到一个后台线程、启动内存的数据不要频繁落地,然后一些主 dex 的问题等。这是从实现方式上去做的点优化。
还有一种就是我们在做完真正实现的优化后,还能不能在体验或者交互、视觉上做一些优化,比如说你启动比较快,你点它,再启动一个启动页面,再进到业务框去,那闪一下的感觉其实不太好,你还不如给到用户的感觉就是我直接点,给用户的感觉是我进入到浏览器里面去,包括第二点和第三点,大家也可以去尝试用一下,这是一些经验。
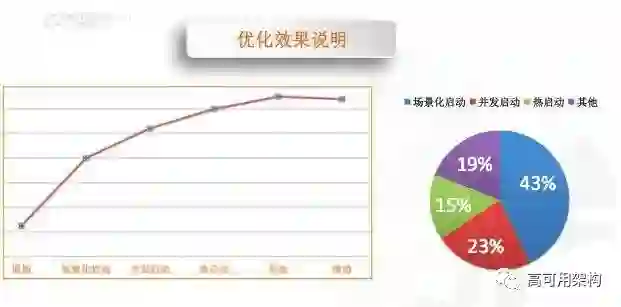
图 10 是做完之后一些效果优化的数据说明。红色的线是 UC 快开比的数据。快开比是这样定义的,是线上大量数据里面在 2 秒以内启动的用户和 PV 占比。我们看到,做场景化启动、并发启动、热启动、其他的优化对性能的提升是一个持续上升的过程,它的贡献比例的话可以如图中饼状图所示,场景化和并发启动是比较高的,所以大家可以优先做这两个去做自己的优化。
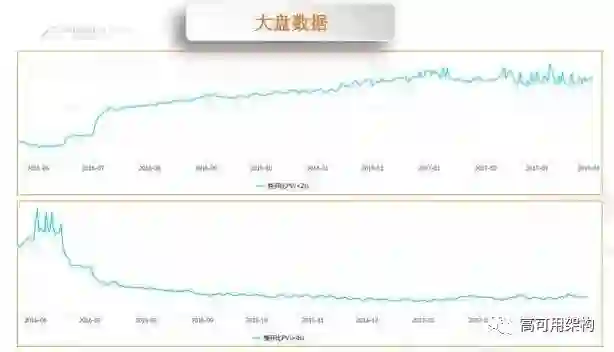
图 11 是 UC 的大盘数据,我们做这个优化是从去年 6 月中旬一直做到 12 月份左右,你可以看到我们的快开比是呈上升的趋势,后面一直是在维持着,包括下面的一些慢开比(就是大于4秒的一个启动数据)。我们也有大半年没有做优化,但是它还是一直维持在那个水平上,不需要像以前一样周而复始地去做这个优化。
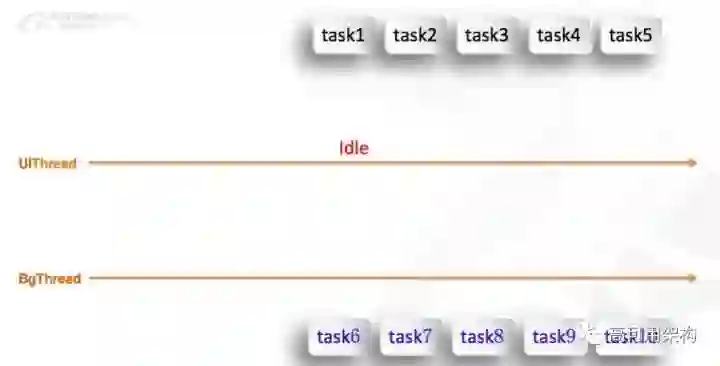
我们刚才说我们有一个很大的手段是把启动场景化,把一些任务预留到后面加载,这样会有一些负体验的作用,就是启动后可能会比以前更卡顿一点,这个该如何解决呢?其实归根结底启动后卡是因为它启动后的事务太多了。这个启动后的事务也是有一个框架去解决的,比如说启动后,我们不会开很多的线程,关注两条线程,UI 线程不用开,即开一条线程在后台。然后这些任务,比如上面的(图12),黑色字体的 task 是必须在UI线程做的,下面的蓝色字体的 task 是可以在非 UI 线程里做的,我们就会尽量把任务放在非 UI 线程去做,减轻 UI 线程的负载,多响应用户的操作。这样我们任务抛入 UI 线程的时候,不像以前一样的一味的进去。进去以后,会保留一个度,比如说 task1、task2 进去之后,我们切合一下这个 UI 线程,这两个任务占多少,有多少时间没有响应用户的事件。如果超过了一个阈值以后,就不要再往里面放了,我们就等它这个 UI 线程闲,idle 状态下再装第三个。
对于后台线程来说,它就没有这个限制了,因为它不太影响用户的响应,我们可以直接把任务给抛进去就行了。大家会有一个疑问,因为我们把这个启动的任务线拉长了,达到 UI 线程的控件,假如说用户这个时候用到了后面的任务怎么办?比如说我这个时候用户点了一个小说,他是不是就是要进小说了。这个时候我们如果在 UI 线程,我们直接把它从队列里面挪出来去加载。对于有些业务是在后台线程去跑的,就要看它本身的耗时,假如说 task9,历史数据表明它是不耗时的,我们就直接把它挪到 UI 线程里面去做。比如说用户用到 task10,他是比较耗时的,我们不可能把它放在 UI 线程,因为它可能会引起那个 ANR,所以说我们是优先从队列里面挪出来,放到后台线程里面去做,同时 UI 线程去转菊花等等这些,很多事情做完之后,再去通知用户响应它的一些操作,这是我们后面的卡顿做的一些规则。
上面是优化层面的,接下来做一些监控层面的。监控分为两个监控,一个是对启动速度的监控,还有一个是对启动后卡顿的监控。启动速度的监控,也会有几个问题,我们还是回到以前的老问题,就是怎么样把问题更早的发现,而不是等到线上去的时候,再去做一个弥补措施。第二是假如说我们发现了启动速度是变慢了,我们怎么样去快速定位这个问题在哪里,是哪条代码造成的。第三个,我们的启动监控代码对原本代码的入侵怎么解决。

在监控的时机上,我们有三个阶段,一个是代码提交阶段,一个是实验室阶段,还有一个线上控量阶段。代码提交阶段,我们有一个 Lint 的规则,插件在实验室去跑。当我们提交代码的时候,可能会跑一些数据,发现假如这个里面跑出创建文件里面有一些重复的、无用的 UI 节点,我们就把它列出来,包括一些 UI 线程多次提交、IO 操作等等把它列出来,在操作阶段就发现这个问题,这是一个层面的问题。还有一个是提交完之后,我们会有打包,打包完之后,我们会做一些跟之前版本的测试,可以是上一个版本,也可以是上一次提交,看你指定。
这个里面我们区分首次和非首次,因为首次和非首次的启动速度是差别比较大的,同时要去交叉执行,这样的话,让这两个包尽量在同一个环境下。这两个包跑完之后,后面有一个对比的数据值。这个数据值如果是在 50 以内,我们都可以认为它并不是一个问题,因为同一个包在同一台手机上,它启动两次,它可能有一个 50 的偏差。只要发现我们是取了多次,30 次、20 次或者50 次的,做两个包的对比,发现它的差值,如果小于 50 内没问题,超过 50 了,要进一步点进去查看。比如说我们要点那个查看,进一步把任务细分,看看哪一块有问题,我们这个任务里面就会按倒序排,发现哪个有问题,就很明显定位到前面的那个任务,会找到对应的负责人解决这个问题。
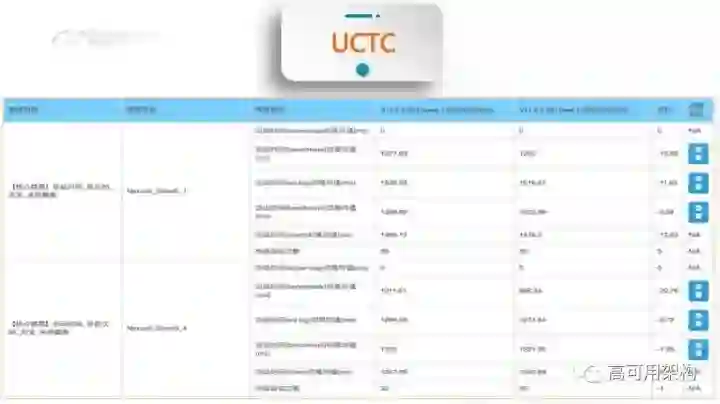

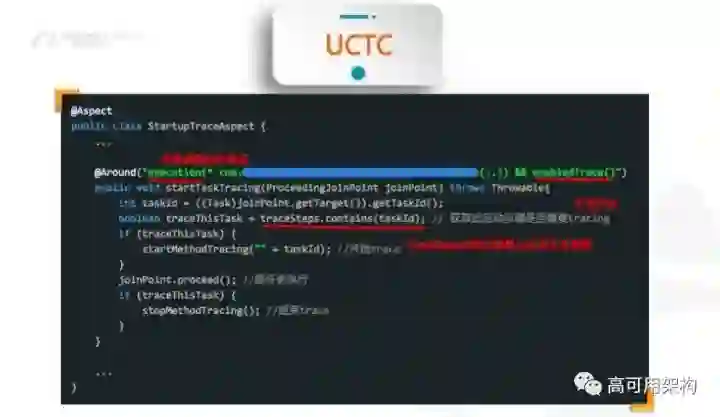
有的人说我这个问题是增长,但是我也不知道为什么,可能需要进一步定位了,就需要我们进一步去分析它的代码,比如说我们要去打 task6,或者是等等东西。这边也用了一个 AOP 的方式去做这个代码入侵的问题,为了防止和线上的包有冲突,因为这种代码加入线上是非常恐怖的,性能直线下滑,所以我们只能在实验室阶段做,我们这边有一个打包开关去控制说你必须是实验室的包才有开启这个开关的功能,包括我们刚才这个 TraceAspect,就是我们刚才上一张表里面,有问题的,我们可以把那个东西输出一个稳定的文件,放在本地的手机目录,当手机再次启动,它自动收集这个目录,把 task6 的逻辑嵌到我们的代码里面去,然后输出我们对应做的事情。这是启动相关的监控。
另外一个是启动后卡顿的问题,监测卡顿安卓这边是做的 loop。其实 UC 在几年前也是用 loop,这个点可能对于卡可以,但是对于顿就颗粒度不够。因为它每次去收集 loop 的话,它要收集一个堆栈,它的性能消耗非常大。还有一点,它的 loop 不断去 hook 每个消息的话,会有内存增长的问题,我们只会在一些大的卡的点上,ANR 的比较卡的点发现问题,但是对于顿的点,我们还是用帧率去衡量。

我们怎么样去做帧率?帧率这个点又有一个问题,就是说帧率必须是界面刷新了才有帧率,界面不刷新,我们怎么拿到他的帧率呢?这是安卓平台的一个 API,我们可以通过这个API去拿到它的帧率,但是它的 API 是安卓 4.1 以上才有的,目前我们基本上用户市面上的机型都已经是 4.1 以上了。我们可以通过在这个回调里面设置一个变量去不断加它的帧,然后我们定一个时间,根据这个时间和帧数来决定帧率是怎么样的。但是这里也有一个问题,这个 API 是你每次 post,它只回调一次,你想让用户一直不操作,一直有帧率,有垂直信号回调回来的话,必须要加这个代码。
这个代码,大家可能会发现,这个不是第一回调用了吗?确实,这个东西必须要通过第一回调用才能够达到它计算用户不操作的时候那个帧率的回调。但是这样会导致我们的 CPU 一直是休眠不了的,怎么样去解决这个问题呢?监控本身的目的就是为了去发现问题,但是本身也是一个性能监控,我们不能够因为性能监控而带来另外性能的问题。我们的一个原则就是我们尽量去缩短我们监控帧率的时间。第二个,既然我们是要衡量用户操作卡不卡,那我们完全可以把问题定位在用户操作的时候,比如说用户操作的时候,只是在那个时间段去监控说这个帧率高不高就行了。
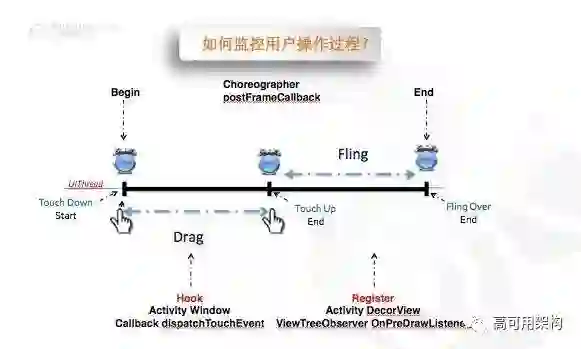
怎么样拿到用户操作过程的帧率呢?这个在安卓平台里面原理是这样的,整个用户操作其实是分成首次手落下到滑动、到手指抬起来,这个时候是没有结束的。因为它的界面还会存在一些动画,或者是一些滚动,类似于他会有一些滚动的行为,这整个行为才是用户的一次完整操作。也就是说我们要拿到最开始用户手点开始到整个界面不动了,这个过程中,我们要开始。对于第一个用户手动点这个东西,我们是通过 Hook Activity Window Callback dispatchTouchEvent 拿到这个 Touch 事件。这个 Touch 事件,我们知道他的 Drag 和 Up 事件这个过程,就知道他是一个什么行为。假如说他中间有拖动的行为,或者他只是一个点击,我们都可以知道。
对于第二个点,就是界面怎么样,它是不动了呢?这个点,我们是什么时间点去确定的。我们刚才说到我们的 Choreographer 这个回调,它是不管怎么样,有垂直信号过来,它都会有回调回来的。对于下面这个,我们是注册了一个 Activity DecorView ViewTreeObserver OnPreDrawListener,它这个回调是必须界面有绘制的时候,它才会去回调。也就是说,当我们的界面有动的时候,其实上层的 Choreographer 跟 PreDrawListener 是一一对应的。这就意味着当这两个不是一一对应的时候,表明界面是不动的,我们通过这种方式把这个过程的时间点给掐出来,只是在这个阶段去监控这个帧率,把我们性能的开销降到最低。
我们知道了之后,可以在这个过程中把我们监控的用户场景数据拉取出来,包括下面的 SM,也是帧率的意思,打印出来,这个日志帮我们定位哪些场景下用户真的操作卡,是不是拖动等等这些行为,这是我们对监控后卡顿收集的行为。
Q&A
提问:你好,我平常是使用 UC 浏览器的,我会遇到这样一个问题,启动浏览器的时候,有时候我并不是首次来操作立马就操作了,它就加载一些数据的时候老是去刷新它的页面,页面这个时候是有很大变化的,这个时候你们是怎么监控卡顿的?刚刚看到你是用手势来触发监控的机制,那个卡顿的监控机制,就是监控它的每一帧,这个时候如果是网络获取数据,或者 APP 从后台,然后在 UC 里面回来,数据隔一段时间会有一个刷新,庞大的数据刷新会造成 UI 界面的卡顿,你们是怎么监测的?
刘成:一个是用户操作行为,那个是可以的,但是我们可以人为设定这个时间的值,就像你当时有可能是一些业务行为,它有可能在业务里面自动去开启我们帧率开始的开关,我们可以有两种方式,一种方式是我们本身跟踪所有用户手势的、用户的操作,还有一种是我们自主去埋点的。对于前者来说,我们不需要自动埋点的,但是对于后一种方式,像你说的,特定的场景或者启动过了一段时间,我们是可以手动去调用 API 埋点的,这样去做的。
提问:我还有另外一个问题, APP 启动的时候会有一个多线程之间的任务调度,有一个排期。排期的时候,你们是怎么检测它某一个线程,它们是忙碌或者是空闲的,来进行一个任务的调度?
刘成:首先每一个线程都有 loop, loop 里面有 idle 回调的,你可以去设置的。通常情况下,我们只会检测 UI 线程的。第二点是我们其实不 care 说我们现在线程检测它忙不忙碌,我们一个是等它回调,第二个是因为任务全部是由我们管控,我们不往里面抛,里面是没有事情做的。
提问:比如说一个任务执行时间很长,相当于是一个大任务的话,你们会做一个拆分吗?
刘成:会,就是我们刚才讲的原子化的步骤,我们尽量把每个步骤保持在 200 毫秒以下,因为 200 毫秒已经调了很多帧了,所以我们为了保证很好的调度,我们是会把任务拆分的。
提问:你好,我这里有几个问题,第一个就是你刚才那个 PPT 说有 7 万的场景。那个 7 万多的场景是什么,可以具体说一下吗?
刘成:我们的任务是分了二十几个任务,这个任务是并发的,这个任务的先后顺序是没有规定的,假如说我们完全没有依赖关系的话,它的启动序列,就是这二十几个任务的排列组合,即 25 的阶乘,你可以想象它是多大一个数字了。在这个基础上,我们是加了一个依赖关系的限制,所以才会降到 7 到 10 万个左右这个样子。
提问:就是这个 7 万跟具体业务没有关系?
刘成:跟业务没有关系,只是我们这样做,启动的这个过程有可能这样启动,比如说 1、 2、 3,这三个任务,如果我们不加依赖关系,它可能是 1、 2、 3 ; 3、 2、 1 ; 1、 3、 2 ; 2、 3、 1 等,这种很多序列嘛。但是我们这二十几个,它的数据会是阶乘量级的暴增,我们只是再强制加了一些依赖关系,比如说我 2 必须要在 1 后面, 3 必须要在 2 后面,这样限制它,把这个东西收敛一下,是这个意思。
提问:第二个问题,你的大盘数据怎么统计你这个 APP 启动的一个时间,在客户端?
刘成:客户端是这样的,首先说一下统计方法,我们统计是在 APPLICATION 类加了一个静态变量,在这个类加载的时候就做了初始化,即起点的埋点,然后到我们启动后。启动后的点,我们定义的是启动后首页绘制 (View dispatchDraw) 调用后的下一帧。我们会抛一帧到下面去,那一帧才是真正的启动结束,你在那个时刻去打断点,会发现那个首页已经显示了。我们是把这个时间点统计起来,就是每个手机,它每次启动,我们都会把这个记录下来,通过数据上传到我们的服务器分析。
提问:这里有一个问题,用户的感知比较强烈,典型的还是要看到你这个界面,你这个就是没办法统计到他点击,就是从点击那个图标开始到你呈现出来。
刘成:对,会有你这个问题,我们点击到启动,可能有一部分它的响应是在系统的层面。因为你操作了,你点击桌面,其实操作的是 Native 的 APP,系统先会在 Native 那边去做一些运转,才会通过各种手段来起我们的进程。通常我们去看过那一块的时间,我可以在这边具体说一下这个点,可能你点的时候是在这个点点的,然后统计在这个点,这个点的差值怎么办?通常系统这边这个点的时候,我们去通过 adb Start 命令,刚才 adb Start 命令的时候会有三个值,我不知道你了不了解, Waittime 就是指从这个点到这个点的时间,你可以看见这个时间段,但是通常这个时间段是比较小的,对我们的大盘数据影响多大,是这样的。
提问:最后一个问题,你们内部有什么标准区分,我这个任务是放在 UI,还是放在后台,因为有些任务是 UI 也可以,放在后台也是可以的。
刘成:这个我们目前是预先定义的,刚才有一张图里面,我们启动任务的描述里面,我们这里面是预先在这里定义的,你的意思是说它能不能动态决定它是在 UI 线程还是非 UI 线程是吧?
提问:不是,因为我们在定义这个任务的时候应该是有一个标准,或者是有一个规范类的东西,就是说我定义这个任务的时候,把它放在 UI,还是放在后台线程,这个区分的标准是怎么样的?
刘成:目前是跟 UI 相关,如果是 UI 渲染相关的是必须在 UI 线程,如果只是 UI 的还不一定,我们可以在后台去做 UI 的初始化的,包括后面我们都在尝试做异步渲染,就是在异步线程去做这个渲染,所以其实任何任务都可以在异步线程的,只是我们目前为了避免一些不必要的麻烦,我们把 UI 渲染相关的是强制让它放在 UI 线程,其他的都可以放在异步线程。
推荐阅读
本文作者刘成,转载请注明出处,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号





