场景模型驱动自动化测试在盒马的探索及实践

一 引言
二 背景及待解决问题介绍
1 盒马自动化体系发展新挑战
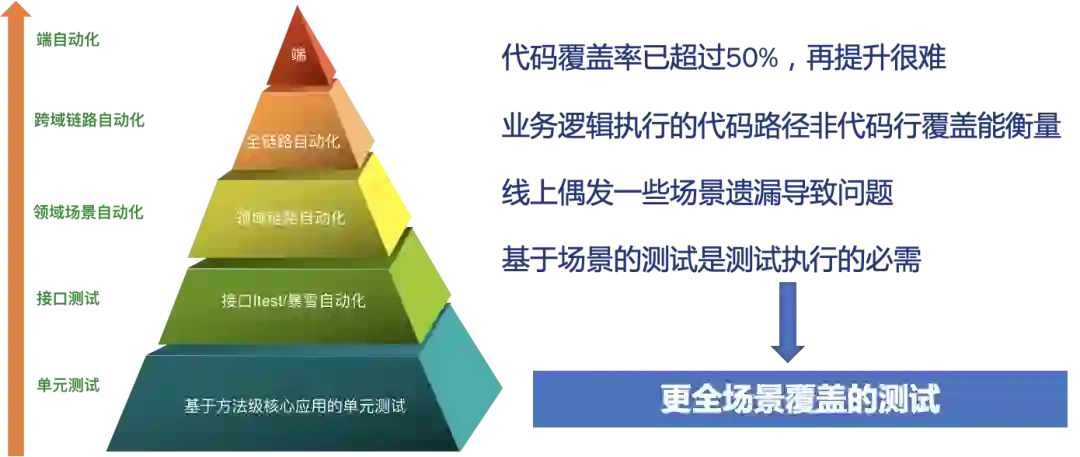
2 业务场景全覆盖的挑战

3 场景模型驱动自动化的思考

三 解决思路
1 模型驱动自动化解决策略
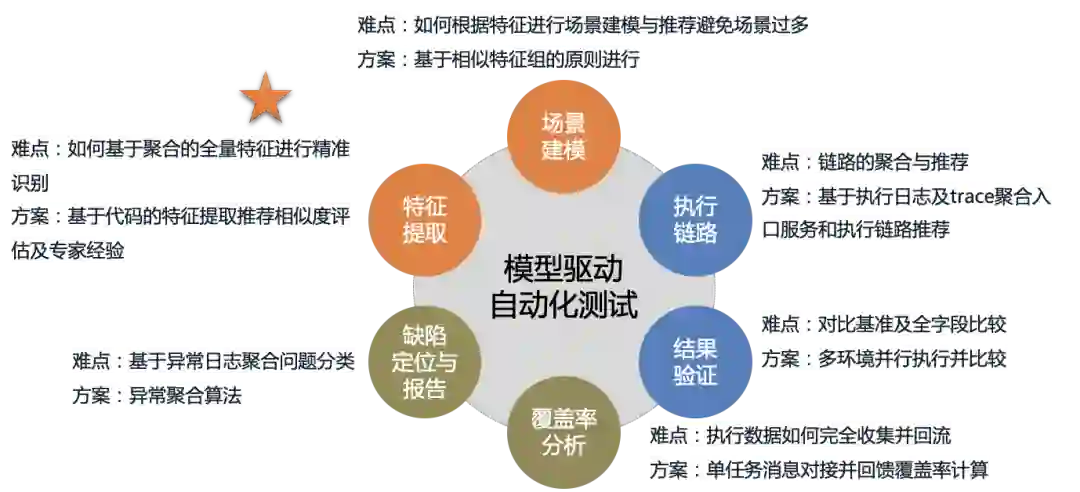
2 业务场景建模问题定义

业务场景建模-特征提取方法

业务场景的建模-特征提取过程
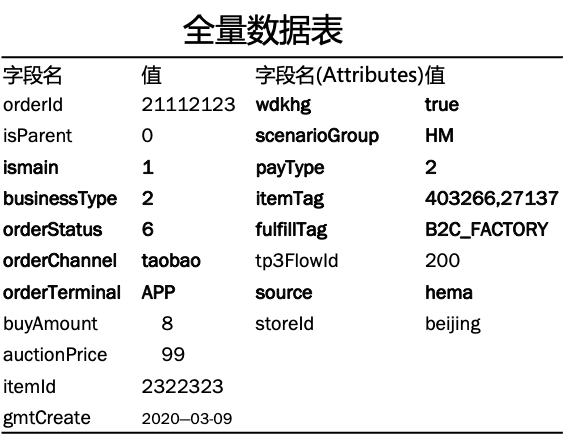
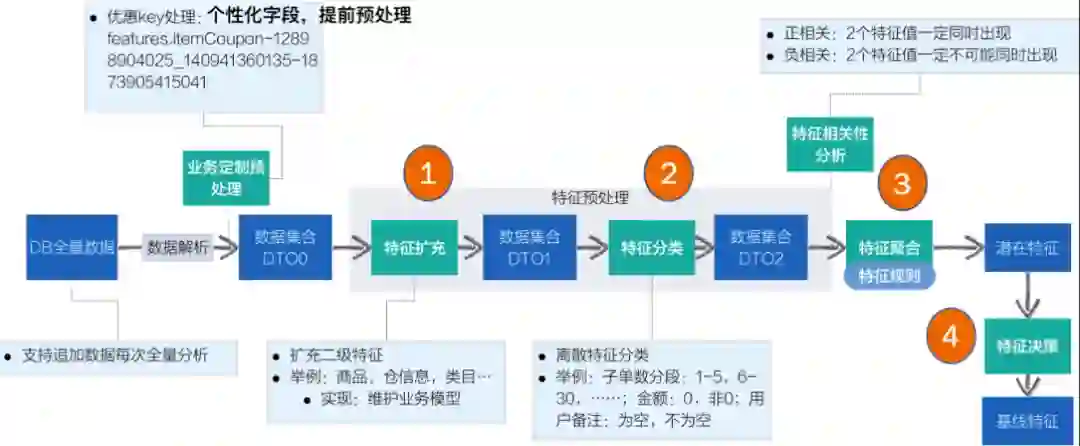
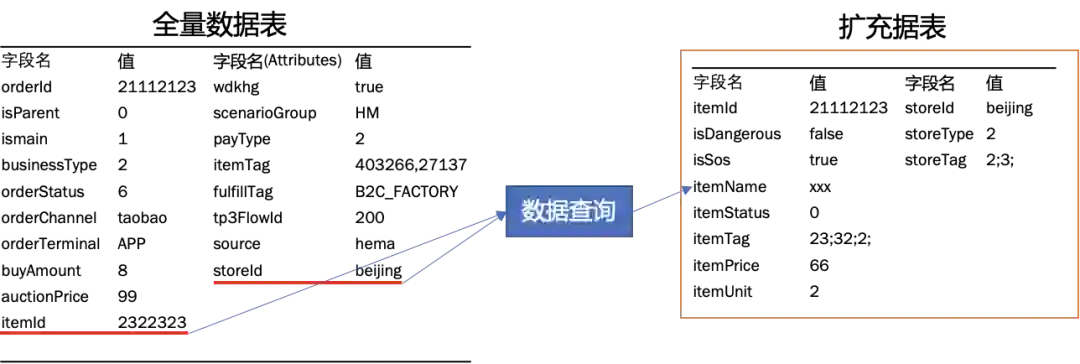
1)特征提取-特征扩充
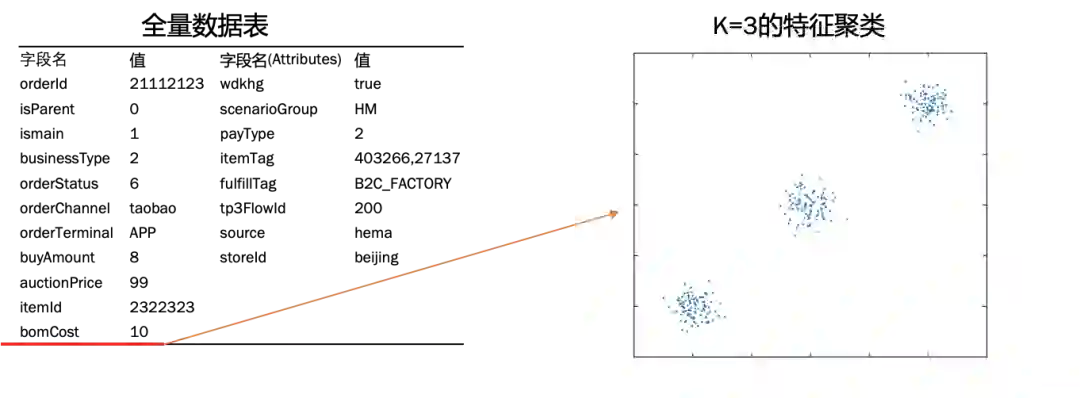
2)特征提取-特征聚类
3)特征提取-特征聚合
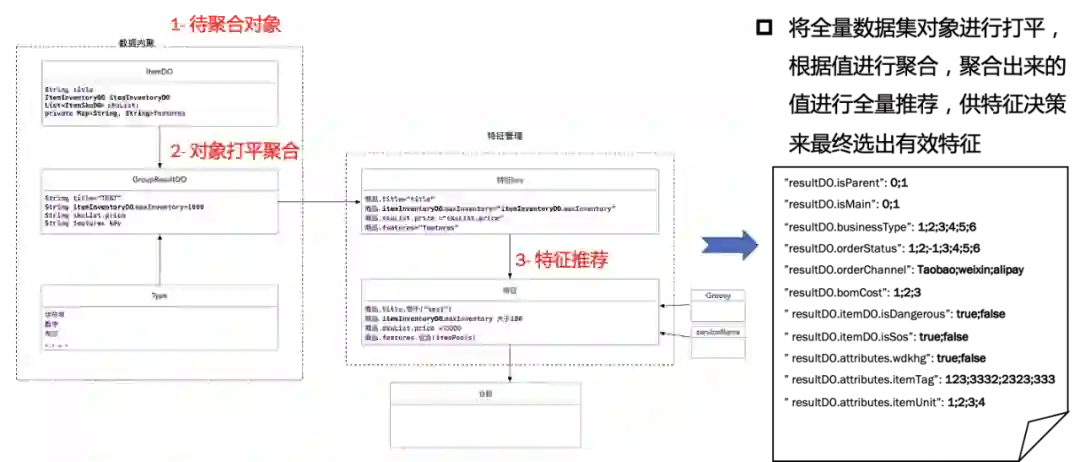
4)特征提取-特征决策



业务场景建模-场景提取

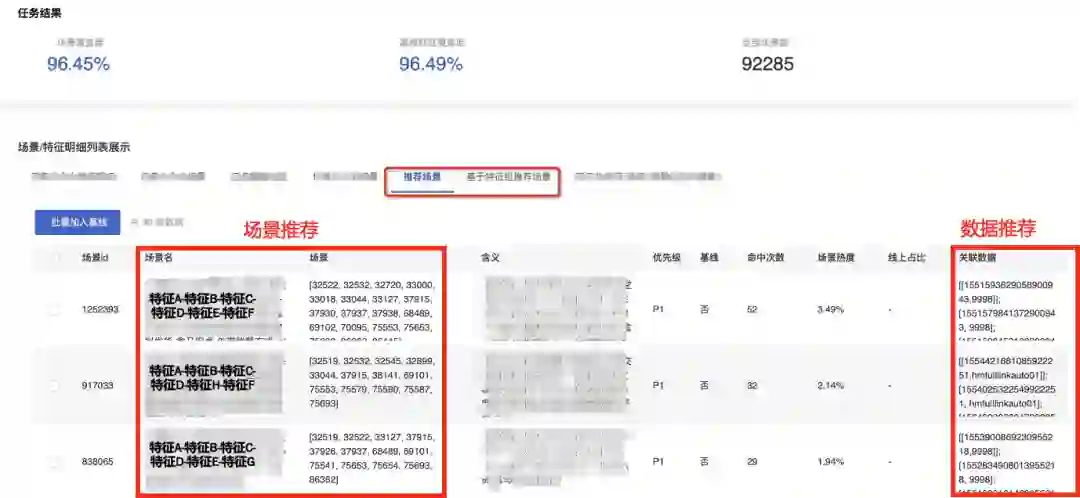

3 执行链路分析及构建
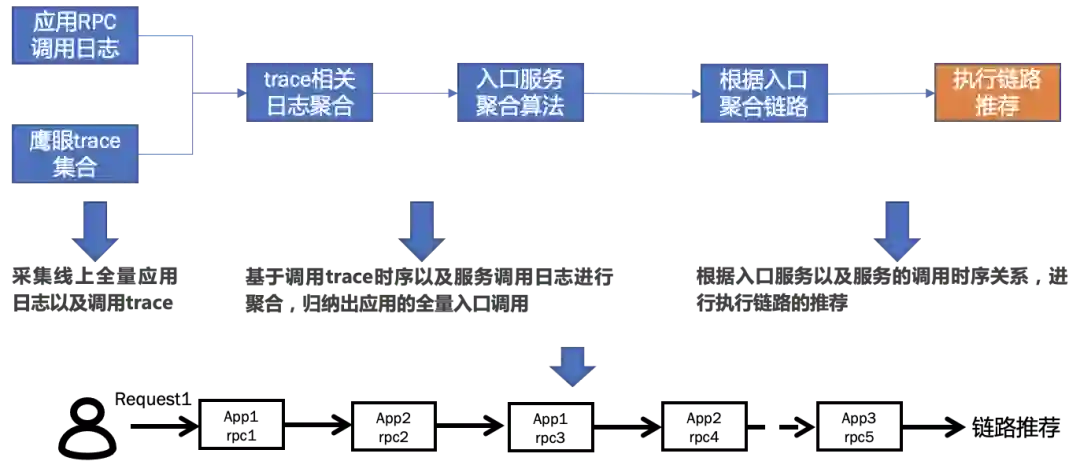
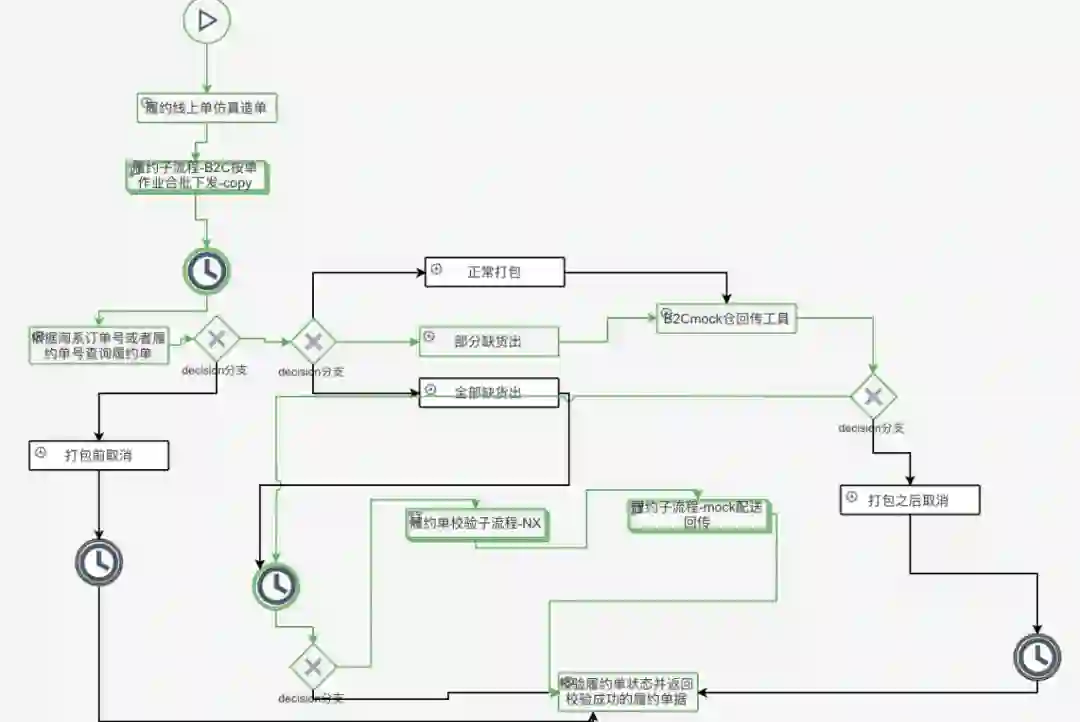
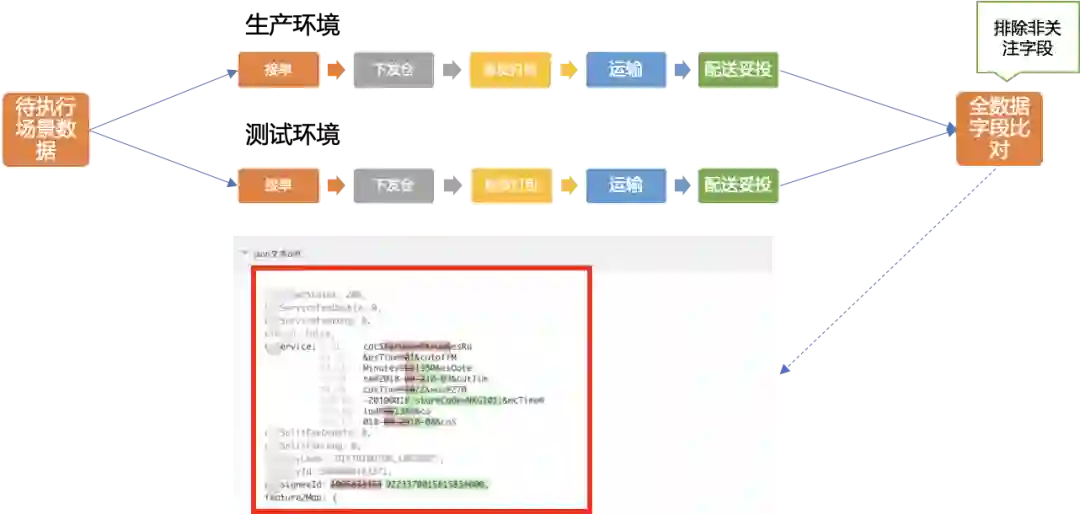
4 数据校验
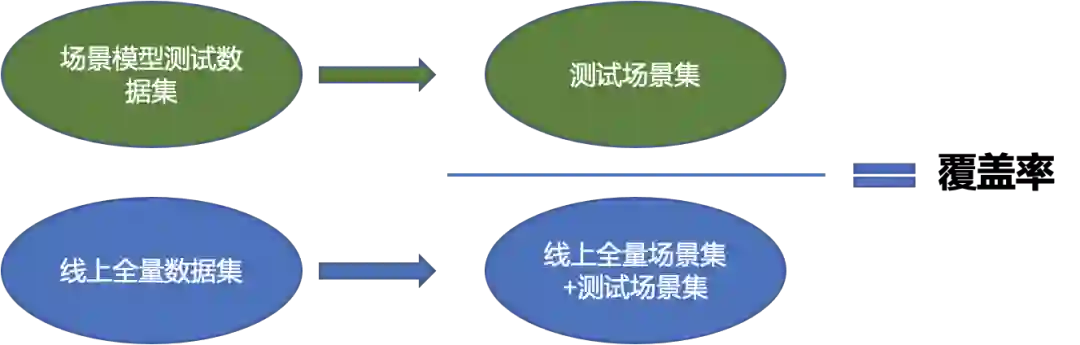
5 场景覆盖率分析
四 产品解决方案
1 产品解决方案架构图

五 实践结果
1 在盒马交易领域的实践
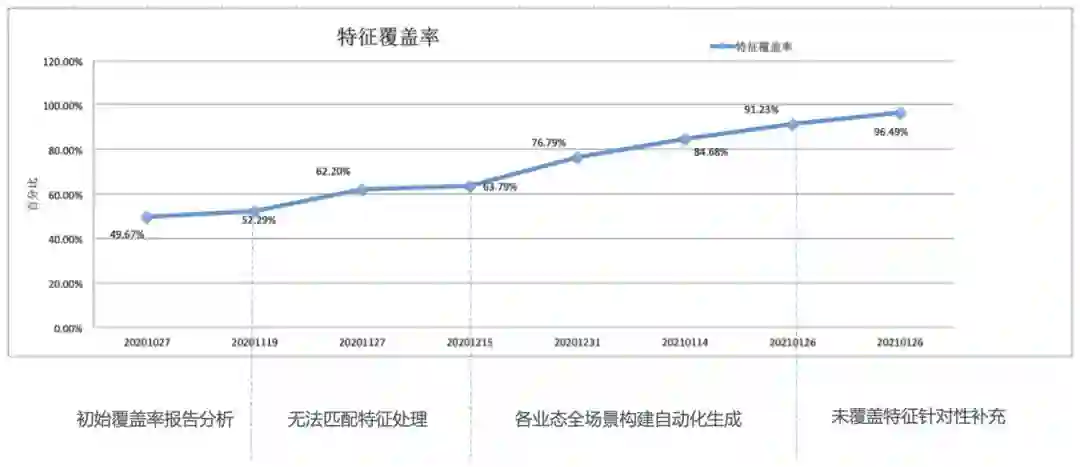

2 在盒马其他典型领域的实践

六 未来展望

七 结束语
技术精彩问答:锦囊妙计
点击阅读原文查看详情!
登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文