阿里大淘系模型治理阶段性分享

一 数据现状
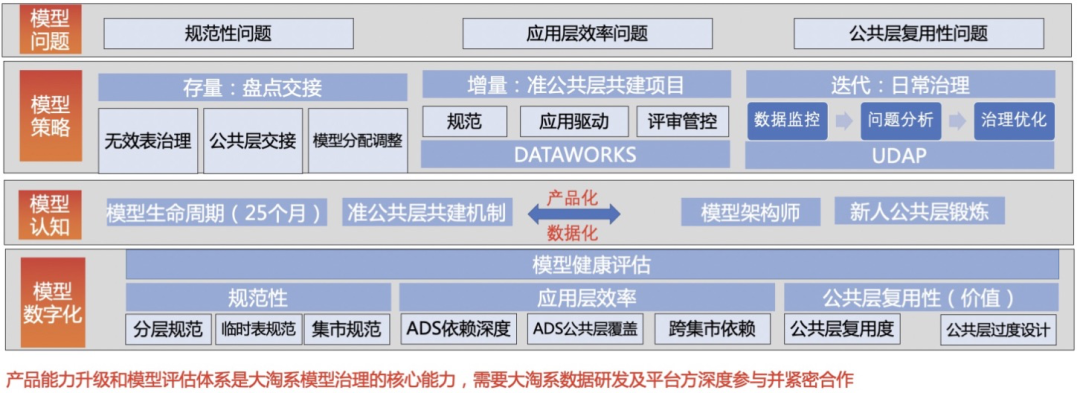
1 规范性问题
-
表命名不规范,缺乏管控:随着数据量增长,大淘系的表出现了大量命名未遵循阿里大数据体系的情况,难以管控。
2 通用层复用性问题
-
通用层表复用性不高:通用层表下游引用少于2个的数量非常多;
-
通用层建设不足或通用层透出不足:cdm引用下降,ads引用上升;
-
较多的ads表共性逻辑未下沉:出现很多ads表代码重复,字段相似度高的情况;
3 应用层效率问题
-
临时表多,影响数据管理:出现了很多TDDL临时表、PAI临时表、机器临时表、压测临时表等;
-
通用层表在各团队分布不合理:散布多个团队;
-
较多的ads表共性逻辑未下沉;
-
部分ads表层内依赖深度较深:很多ads表在应用层的深度超过10层;
-
应用层跨集市依赖问题明显:不同集市间ads互相依赖,不仅影响了数据稳定性,而且数据准确性也难以保障;
-
存在大量的可交接的通用层表:不同团队的通用层数据与大淘系数据混合在一起;
-
表人员分配不均衡:表owner管理的表数量分布很不均匀,有些owner名下只有几十张,有些owner名下有几千张;
二 问题分析
三 解决方案
1 DataWorks共建
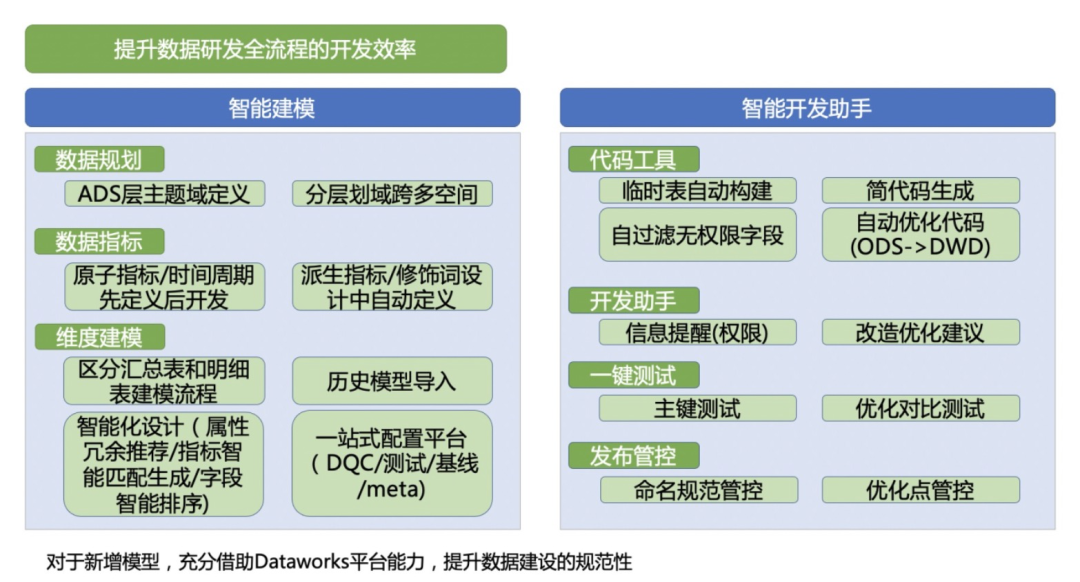
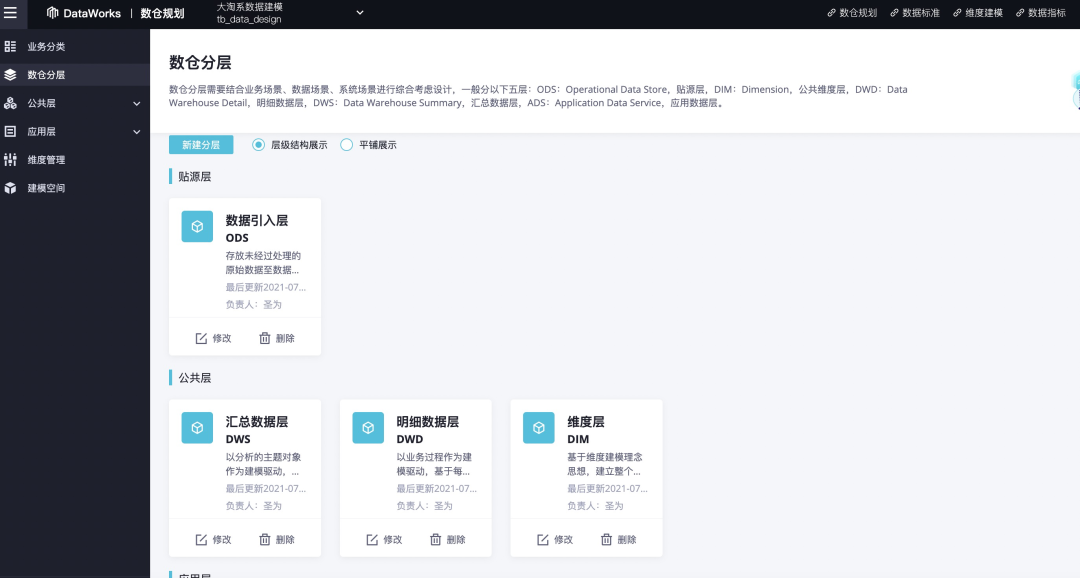
DataWorks智能数据建模
支持公共层及应用层数仓经典分层化域方案所需要素(如数据域、数据集市等)的业务自定义;
支持数仓规范的业务自定义,如各层表名规范定义;
支持建模空间,支持设置建模空间与数据研发空间的关系建立,满足大淘系多业务共享数据规范统筹管理数据模型的需求。
支持数仓已有物理表的、的逆向建模,解决了大淘系已有物理表的冷启动难题。
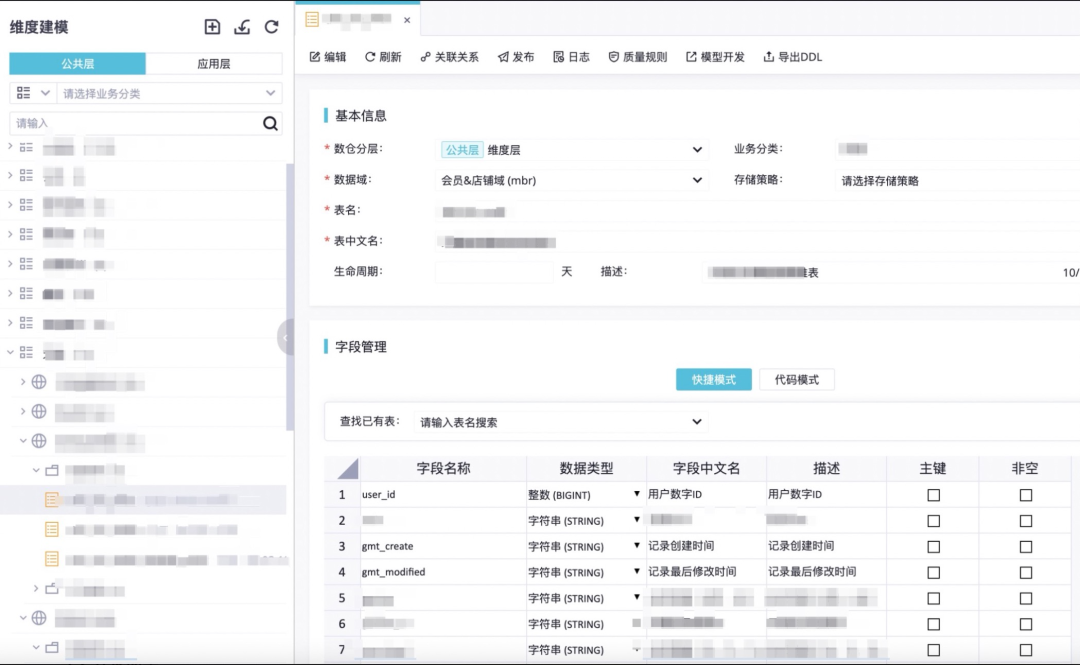
支持维度表、明细表、轻度汇总表和应用层表的正向建模,支持可视化建模、excel文件导入模型及代码建模三种方式。正向可视化建模产品功能汲取了大淘系建模同学沉淀的经典建模理论,依托了MaxCompute的优势,实现了快速复制MC已有物理表的表结构并支持基于已有字段做维度字段冗余的产品功能,此外,汇总表及应用层表可快速引用已创建的指标生成模型表字段。正向建模excel文件导入模型将大淘系同学数年来沉淀的经典模型excel模版产品化,满足部分习惯性excel建模同学的建模需求。正向建模产品功能,极大程度上提升了建模效率。
设计完成的模型,支持模型评审及物理表发布到MaxCompute、Hologres等五种引擎。
发布成功的模型,实现了和DataStuido(数据开发)的打通,支持自动生成ETL框架代码,数据开发同学只需在此代码基础上补充业务逻辑代码即可,该功能在一定程度上提升了数据开发同学的研发效率;
开发助手
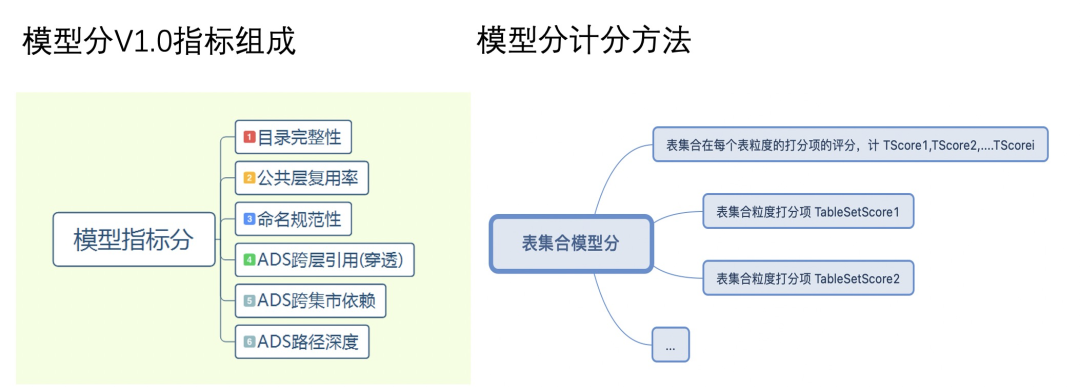
2 模型分
模型分打分逻辑
模型分大盘
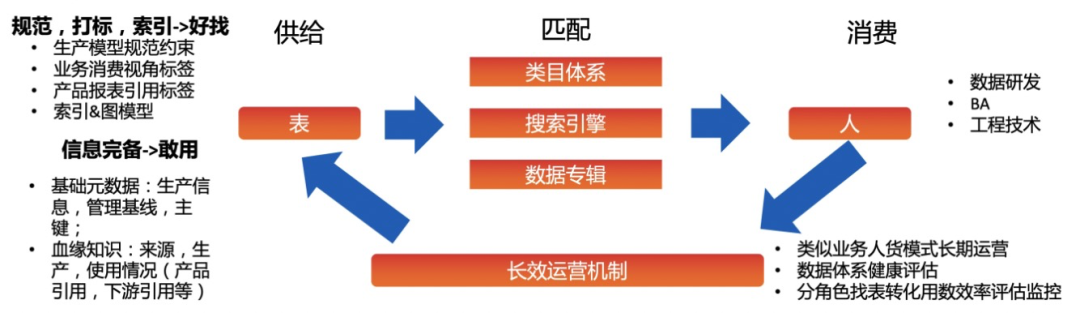
3 找数提效
-
搜索结果左侧过滤条件透出高频使用条件供用户选择,提高筛选效率和搜索CTR。
-
恢复字段搜索功能,搜索过滤支持按照环境过滤。
-
升级表使用说明编辑器为语雀编辑器,支持导入语雀内容,来帮助解决口径问题
-
数据专辑提供管理员功能,支持多人协作维护。
-
加入专辑支持展示和修改收藏备注。
-
个人专辑详情页中,支持通过表的描述和收藏备注进行搜索。
-
专辑增加使用说明功能
-
支持在地图中标识表是模型表、展示出表的模型信息。
1)搜索推荐

2)数据专辑
3)专辑说明
4)数据百晓生
四 思考总结
-
模型评估体系:设计并定义了大淘系模型评估体系,从多个维度实现了数据健康度的评估和表级别的治理建议。
-
智能建模:与DataWorks智能建模团队合作,上线了数仓规划、维度建模等重磅产品,实现了维度表、明细表、轻度汇总表和应用层表的正逆向建模。
-
数据地图升级:升级了搜索推荐、数据专辑、表说明等重要功能,极大的提高了找数、用数、管理数据的效率。
-
协作规章制度:定义了准通用层下沉规范、协作规章、交接流程、新人培养机制等清晰的制度,提供清晰的制度保障。
五 后续规划
-
统一架构和规范难保障:各业务对阿里大数据体系规范的理解程度不一致,集团数据架构和规范的统一难以保障;
-
业务通用层比较薄:历史背景之下,各业务通用层建设比较薄弱,新架构下业务效率和口径存在风险;
-
ADS层持续增长,复杂度难管控:阿里大数据体系规范缺少对应用层的规范,ADS与通用层的边界划分不清晰,ADS的复杂度难以控制;
-
缺乏有效管控:在数据开发与运维层面,阿里巴巴沉淀了大数据体系规范不断与数据平台融合,但是部分标准无法强制执行与数据平台进行集成。数据治理上,当前数据无法有效识别数据表是否无效,导致研发对数据表不敢下、没精力下;
-
数据建设和使用尚未完全打通:当前数据开发和数据使用尚未完全实现数据打通,定义的模型、开发的数据未在数据地图中有效的实现透出和管理。
大淘系模型架构
智能建模
数据地图
官方专辑快速接入:当前官方专辑构建需要专人进行配置和维护,后续可以考虑降低接入成本,下放到各个团队进行自主接入和维护,提升数据专辑的丰富度和易用性。
进一步打通数据开发和使用环节:将智能建模的数据与数据地图进一步打通,实现核心模型的快速筛选和透出。
多角度提升表查询和使用的能力:从表说明、表答疑、数据知识提取等方面实现对找表、用表、表答疑的简易度提升,结合文本算法、机器人等技术和产品能力,实现数据知识的智能生成。
开发助手
开发助手在表推荐和表管控方面可以进一步升级。
大淘系通用层评估体系升级
针对当前的模型分加入模型血缘相关的信息,做厚大淘系通用层,为业务提供更好的通用层数据支撑。
表自动化下线:实现模型、表、服务的自动化下线&专家经验下线,提高数据下线效率,降低人工介入成本。






