一招检验10大深度学习框架哪家强!
来源:机器之心
[ 导读 ]近日,Ilia Karmanov 在 Medium 发表了一篇题为《Neural Net in 10 Frameworks (Lessons Learned)》的文章,其内容源自一个 GitHub 项目,其中作者通过构建同一个神经网络,对比了当前最流行的 10 种深度学习框架,其中 Caffe2 和 MXNet 在准确度和训练时长上处于领先位置。该项目甚至还得到了 FAIR 研究者、各大框架创始人(比如贾扬清)的支持。
项目GitHub链接:
https://github.com/ilkarman/DeepLearningFrameworks
除却所有的技术元素之外,我发现关于这一项目最有趣的事情是来自开源社区的惊人贡献。社区发起的请求(pull request)、提出的问题(issue)非常有助于在准确度和训练时间方面统合所有框架。看到 FAIR 研究者、框架的创始人(比如贾扬清)以及 GitHub 的其他用户所做出的贡献,我很震惊。没有他们,就不会有这个项目的完成。他们不仅给出了代码建议,还提供了不同框架的整个 notebook。
你可以在这里看到贡献之前该项目的最初状态:
https://github.com/ilkarman/DeepLearningFrameworks/tree/0143957489e8adbecaa975f9b541443421db5c4b
问题
搜索 Tensorflow + MNIST 会出现这个看起来很复杂的教程,它规避了更高级的 API(tf.layers or tf.nn),并且似乎没有从输入数据中充分分离,因此使用 CIFAR(举例来说)替代 MNIST 更加让人舒服。一些教程为了避免冗长加载 MNIST 有一个自定义的封装器,比如 framework.datasets.mnist,但是对此我有两个问题:
初学者可能并不太清楚如何在数据上重新运行。
将其与另一个框架对比也许更加棘手(预处理会有所不同吗?)
其他教程把 MNIST 作为文本文件(或自定义数据库)保存到硬盘,接着使用 TextReaderDataLoader 再次加载。这个想法表明,如果用户有一个大型数据集,它太大以至于无法加载到 RAM,并且需要大量的即时转换,那么会发生什么?对于初学者来说,这也许是误导性的,使人胆怯。我经常被问到:“为什么我需要保存它,我明明有一个数组!
目标
本文的目标是如何使用 10 个最流行的框架(在一个常见的自定义数据集上)构建相同的神经网络——一个深度学习框架的罗塞塔石碑,从而允许数据科学家在不同框架之间(通过转译而不是从头学习)发挥其专长。不同框架具有相同模型的一个结果就是框架在训练时间和默认选项上变得越发透明,我们甚至可以对比特定的元素。
能够快速地把你的模型转换为另一个框架意味着你能够交换 hats。如果另一个框架有一个层需要你从头编写,用更有效的方式处理数据资源,或者使其更匹配正运行于其上的平台(比如安卓)。
对于这些教程,我尝试不顾违反默认选项,使用最高级别的 API,从而更加便捷地对比不同框架。这意味着 notebook 并不是专为速度而写。
这将证明如果使用更高级的 API,代码结构将变得相似,并可被大体表征为:
Load data into RAM; x_train, x_test, y_train, y_test = cifar_for_library(channel_first=?, one_hot=?)
把数据加载到 RAM;x_train, x_test, y_train, y_test = cifar_for_library(channel_first=?, one_hot=?)
生成 CNN 符号(在最后的密集层上通常没有激活)
指定损失(交叉熵通常与 softmax 绑定)、优化器和初始化权重,也许还有 session
使用自定义迭代器(所有框架的通用数据源)在训练集的小批量上进行训练
对测试集的小批量进行预测,也许为层(比如 dropout)指定测试标记
评估准确率
注意事项:
我们实际上比较了一系列确定的数学操作(尽管初始化比较随意),因此比较框架的准确率并无意义,相反,我们想匹配框架的准确率,来确保我们在对同样的模型架构进行对比。
我说比较速度没有意义的原因是:
使用数据装载器(仅)可以减少几秒,因为 shuffling 应该异步执行。但是,对于一个合适的项目,你的数据不可能适合 RAM,可能需要大量预处理和操作(数据增强)。这就是数据装载器的作用。贾扬清认为:
我们在多个网络中经历了主要瓶颈 I/O,因此告诉人们如果他想要顶尖的性能,使用异步 I/O 会有很大帮助。
这一实例中仅使用若干个层(conv2d、max_pool2d、dropout、全连接)。对于一个合适的项目,你也许有 3D 卷积、GRU、LSTM 等等。
轻松添加自定义层(或者层的可用性,比如 k 最大池化或者分层 softmax),及其运行速度可以促成或毁掉你的框架选择。能够用 python 代码写一个自定义层并快速执行它对研究项目至关重要。
结果
在 CIFAR-10 上的 VGG-style CNN
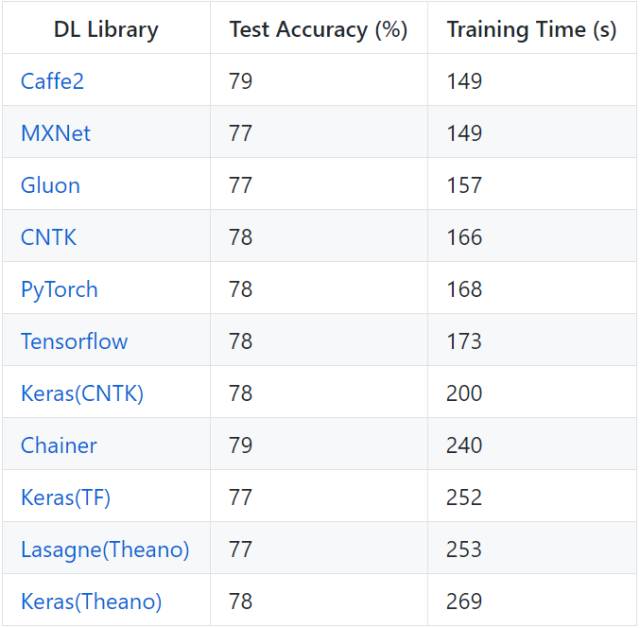
IMDB 上的 LSTM(GRU)
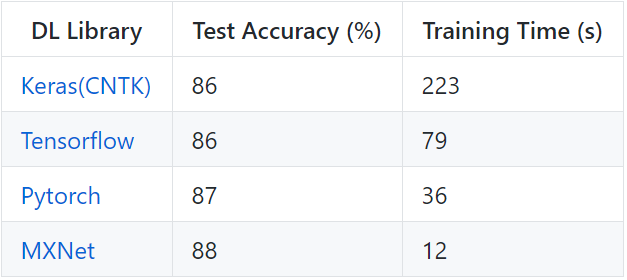
心得体会(匹配准确率/时间)
下列是我对多个框架测试准确率进行匹配,并根据 GitHub 收集到的问题/PR 得到的一些观点。
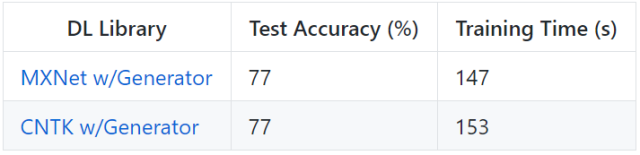
1. 为方便对比,上文中的实例(除了 Keras)使用同等水平的 API 和同样的生成器函数。我在 MXNet 和 CNTK 的实验中使用了更高水平的 API,在该 API 上使用框架的训练生成器函数。该实例中的速度提升几乎微不足道,原因在于整个数据集作为 NumPy 数组在 RAM 中加载,每个 epoch 所做的唯一的处理是 shuffle。我怀疑该框架的生成器也在异步执行 shuffle 操作。奇怪的是,似乎框架在一个批次水平上进行 shuffle,而不是在观察层面上,因此测试准确率稍稍降低(至少在 10 epoch 之后)。在框架运行时进行的 IO 活动、预处理和数据增强的场景中,自定义生成器对性能的影响更大。
2. 启用 CuDNN 的自动调整/穷举搜索参数(对固定大小的图像选择最高效的 CNN 算法)会使性能大幅提升。在 Caffe2、PyTorch 和 Theano 中,必须手动启用。而在 CNTK、MXNet 和 Tensorflow 中,该操作默认进行。我不确定 Chainer 是什么情况。贾扬清提到 cudnnGet(默认)和 cudnnFindi 之间的性能提升比 Titan X GPU 上要小;看起来 K80 + new cudnn 使该问题在这种情况下更加突出。在目标检测的每一次规模连接中运行 cudnnFind 会带来严重的性能回归,但是,正因如此,可以在目标检测时禁用 exhaustive_search。
3. 使用 Keras 时,选择匹配后端框架的 [NCHW] 排序很重要。CNTK 首先使用通道运行,我错误地将 Keras 配置为最后使用通道。之后,Keras 在每一批次必须改变顺序,这引起性能的严重下滑。
4. Tensorflow、PyTorch、Caffe2 和 Theano 要求向池化层提供一个布尔值,来表明我们是否在训练(这对测试准确率带来极大影响,72% vs 77%)。
5. Tensorflow 有一点麻烦,它需要两个改变:启用 TF_ENABLE_WINOGRAD_NONFUSED 来提升速度;首先改变通道的维度,而不是最后再改变(data_format=』channels_first』)。TF 作为后端时,在卷积层上启用 WINOGRAD 自然也能改善 Keras 的性能。
6. 对于大多数函数,Softmax 通常与 cross_entropy_loss() 绑定在一起,有必要检查一下最后的全连接层是否需要激活,以省下应用两次激活的时间。
7. Kernel 初始程序在不同的框架中会发生改变(我发现这对准确率有+/- 1% 的影响),我试图在可能不是很长的情况下指定统一的 xavier/gloro。
8. SGD 动量实现的动量类型。我必须关闭 unit_gain(只在 CNTK 中默认开启),以匹配其他框架的实现。
9. Caffe2 在网络第一层需要额外的优化(no_gradient_to_input=1),通过不计算输入的梯度产生小幅提速。有可能 Tensorflow 和 MXNet 已经默认启用该项。计算梯度对搜索和 deep-dream 网络有用。
10. 在最大池化之后(而不是之前)应用 ReLU 激活意味着你在降维之后执行计算,并减少几秒时间。这帮助 MXNet 时间减少了 3 秒。
11. 一些可能有用的进一步检查:
指定 kernel 为 (3) 变成对称元组 (3, 3) 或 1D 卷积 (3, 1)?
步幅(用于最大池化)默认为 (1, 1),还是等同于 kernel(Keras 会这样做)?
默认填充通常是 off (0, 0)/valid,但是对检查它不是 on/』same』很有用
卷积层上的默认激活是『None』还是『ReLu』(Lasagne)?
偏差初始程序可能会改变(有时不包含任何偏差)。
不同框架中的梯度截断和 inifinty/NaNs 处理可能会不同。
一些框架支持稀疏标签,而不是独热标签(如,Tensorflow 中有 f.nn.sparse_softmax_cross_entropy_with_logits)。
数据类型的假设可能会不同:我尝试使用 float32 和 int32 作为 X、y。但是,举例来说,torch 需要 y 变成 2 倍(强制转换成 torch.LongTensor(y).cuda)
如果框架 API 的水平稍微低了一点,请确保你在测试过程中,不通过设置 training=False 等来计算梯度。
原文链接:
https://medium.com/@iliakarmanov/neural-net-in-8-frameworks-lessons-learned-6a5e8e78b481
编辑:王璇
校对者:王红玉