Anna 键值存储系统性价是 DynamoDB 355 倍
过去似乎每周都在宣布新的数据库。虽然近期新推出数据库的速度已大大放慢,但还不至于完全停滞。
来自加州大学伯克利分校的RISELabs近日将其Anna数据库由版本0提升到了版本1,变成了可识别云。这种数据库是一种每个核心一个线程的无共享架构,避免了所有协调机制,因而获得极高的速度。
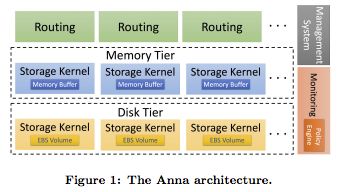
Anna的架构图
看看发生了什么变化。
Anna不仅速度极快,而且异常高效且极具弹性:这是一种自动扩展、多存储层、选择性复制的云服务。所有这些适应性意味着Anna为冷数据减少了消耗的资源,为热数据增加了所需的资源。你可以获得所需的所有多核Anna性能,但又不必为不需要的性能付费。
仅举几个数字,我们测得Anna以同样的成本提供了比DynamoDB高355倍的性能。 不,我认为这不是由于AWS在DynamoDB上获得高出355倍的利润!问题在于,除了速度快几个数量级外,现在Anna的效率也比与之竞争的系统高出几个数量级。
RISELabs在《快速又便宜:我们如何使Anna可以自动扩展?》中撰文介绍了Anna新的强大功能,内容如下:
我们使用Anna v0作为一种内存存储引擎,一心想要解决上述的云存储问题。我们还旨在让云端速度最快的KVS发展成为适应性最强、成本效益高的系统。为此,我们为Anna添加了三种关键的机制:垂直分层、水平弹性和选择性复制。
Anna v1 的核心组件是监测系统和策略引擎,共同实现了工作负载的响应性和适应性。为了满足用户定义的性能(请求延迟)和成本方面的目标,监测服务对工作负载的变化进行跟踪,并相应调整资源。每台存储服务器收集所处理的请求方面的统计信息和存储的数据等信息。监测系统定期获取和处理这些数据,而策略引擎利用这些统计信息,通过上述三种机制中的一种来执行操作。每种操作的触发规则很简单:
弹性:为了让系统适应不断变化的工作负载,系统必须能够自动增加或减少资源,以匹配它所看到的请求量。当某一层达到计算或存储容量的最大值时,我们为集群添加节点;当资源未得到充分利用时,节点就被移除,以节省成本。
选择性复制:就实际的工作负载而言,常常有一组热键,它们应该复制(不仅仅是为了满足容错要求),以提升性能。这增加了处理常见请求可供使用的处理器核心和网络带宽。Anna v0让用户能够对键实现多主复制,但是所有键都有一个固定的复制因子。很自然,这样的成本高得离谱。在Anna v1中,监测引擎选择访问最频繁的键,相应增加那些键的副本数量,又不支付额外的成本来复制冷数据。
升级和降级:就像传统的内存层次结构,云存储系统应该将热数据保存在高性能、内存速度的存储层中,以提高访问效率,而冷数据应放在速度较慢的存储层上,以节省成本。我们的监测服务可根据访问模式,在不同的存储层之间自动转移数据。
为了实现这些机制,我们不得不对Anna的设计做出了两个重大的改变。首先,我们将存储引擎部署在多种存储介质(目前是内存和闪存盘)上。与传统的内存层次结构类似,这每一个存储层代表了成本和性能之间不同的取舍。我们还实现了一项路由服务,它将用户请求发送到相应存储层的相应服务器上。无论数据存储在什么地方,这为用户提供了一套统一的API。这每一个存储层同样拥有由Anna第一个版本继承而来的丰富的一致性模型,因此开发人员只需要操心仅仅一种广泛参数化的一致性模型。
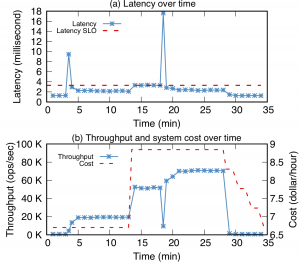
我们的试验表明,无论在性能还是成本效益方面,Anna都表现出众。在同样的固定价位下,Anna提供了8倍于AWS ElastiCache的吞吐量和355倍于DynamoDB的吞吐量。Anna 还能够通过准确地添加节点和复制数据来应对工作负载的变化。
RISELab的目标是让计算机能够做出智能化的实时决策。你可能不记得去年RISELab从AMPLab涅槃而生。AMPLab培育出了像Apache Spark和Apache Mesos这些成功的开源项目,所以别犯这个错误:以为它们所做的工作纯粹只是为了搞学术研究,它们旨在创造美好未来。
\
Anna的论文:《用Anna消除云存储方面的界限》https://arxiv.org/pdf/1809.00089.pdf

Anna的代码:https://github.com/fluent-project/fluent/tree/master/kvs






