点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
本文授权转载自:机器之心 | 参与:一鸣、张倩
TensorFlow 2.0 正式版上线两月有余,迎来的却是疯狂吐槽。网友们评价:「你看看人家 PyTorch!」
TensorFlow 被吐槽不好用,也不是一天两天了。TensorFlow 2.0 的发布似乎将这种「民怨」推上了高潮。
昨天,一位 reddit 网友说自己正在尝试从 PyTorch 转到 TF 2. 0(虽然没有说为什么这么想不开),但他吐槽说:真是「太难了」。
这篇吐槽 TensorFlow 2.0 的帖子,让深有同感的网友们疯狂点赞。
切换之后,TF 2.0 给他的最大感觉是:这个库本身没有什么问题,真正的问题在于缺乏官方指南、详细的说明文档以及来自官方开发团队的答疑。
首先,ta 感觉 TensorFlow 信息不全:很多在用户中非常常见的 pipeline 都要自己动手做。而且,无论做什么似乎都有很多种方法。令人头疼的是,这些方法都有细微的差别,但官方文档并没有告诉你有哪些差别,你只能苦哈哈地翻他们的 GitHub issue,找不找得到全凭运气。
其次,ta 发现,medium 上有很多非正式的 TF 2.0 相关博客,但这些博客中包含很多错误信息,还有一些是广告。
最后,ta 发现网上有很多关于 TF 的提问,但却没人回答,有些甚至是一年前提出的。这些问题质量很高,而且都是官方文档里没有提及的。相比之下,PyTorch 有一个论坛,在上面问问题可以得到 PyTorch 开发人员的解答,这方面要比 TensorFlow 好太多。
发帖者还对比了一下 TensorFlow 和 PyTorch 积压的问题,发现
PyTorch 积压未回答的问题只有 2101 个,但 TensorFlow 却达到了 24,066 个
。差距之大触目惊心。
所以,作者的总体感觉是,TensorFlow 架构本身问题不大,但给人的用户体验是在是太差了。
最后,这位网友不禁发出了灵魂追问:「
如果不提供足够的信息让用户掌握最佳的使用方式,东西做得再好又有什么用呢?
」
所谓一石激起千层浪。这位网友的抱怨引来了大批 TFboys(girls)的共鸣,该贴也成为 TF2.0 的大型吐槽现场。
除了赞同发帖者提出的几个问题外,跟帖的网友还指出了 TensorFlow 2.0 本身存在的一些问题,如与 Keras 的整合。
官方文档不足/官方文档不好找;
很多 Bug 没有及时修复或更新;
和 Keras 的整合很不好,导致用户混乱。
一位网友写道:「在过去 TF 的黄金时期,有很多容易上手的教程,官网上的教程质量也很高。但是自从 Keras 被引入后,整个指引文档成了 Keras 和经典 TF 的混合。」这段评论得到了很多人的赞同。一些人表示,TF1.x 版本尽管学习成本很高,但是(教程)是非常连贯的,况且还有 tensor2tensor 这样的代码库,使得旧版本的使用并不是那么困难。
官方教程缺失使得社区只好自力更生,很多人不得不去其他渠道寻找相关教程和指南。但是非官方的教程也不一定靠谱。比如下面一位网友就写到:
1. 我有个想法,我想要在训练过程中逐渐改变损失函数的『形状』;
2. 我搜索『tensorflow 在训练中改变损失函数』;
3. 最高搜索结果是一个 Medium 的文章,我们去看看吧;
4. 这个 Medium 文章介绍的是均方误差(MSE)损失函数,以及你怎样在 TensorFlow 中用它训练一个深度神经网络;
不仅仅是教程文不对题的问题。正如发帖者所说,非官方的教程也会有很多错误,增加了用户解决问题的成本。久而久之,大家自然都不愿意用 TF2.0 了。
此外,跟帖者的反馈也证实了发帖者提出的第三个问题:太多问题和反馈没有及时处理。
可能是因为 TF 社区本身就比较火爆,对框架的提问和反馈会更多,因此 TF 官方对问题的回复和 bug 的修复似乎比 PyTorch 要慢。正如发帖者所说,TensorFlow 待回答问题数量比 PyTorch 高了 10 倍还要多。更何况,PyTorch 还有一个专门的团队在平台上负责解答疑问。
对于一个开源软件来说,提高其性能、易用性、安全性及减少 bug 的最佳方式是不断地收集用户反馈、给予回复、并根据反馈修复错误和问题。但是,如果 TF2.0 没有及时对这些出现的问题进行处理,则软件本身不可能继续进步。
正是因为用户遇到问题时 TF 官方能够及时跟进并改进问题,用户才会继续留存。有位网友就评论说,他在使用 TF2.0 的过程中遇到了很多问题,但是幸好有官方的开发经理跟进和解决,所以他才愿意继续留在 TF2.0 上继续使用。
除了这两个问题,很多人还是回到了吐槽 Keras 和 TF 的结合上。
一些网友认为,TF2.0 还有一个不好用的地方,那就是 Keras 和 TF2.0 的「联姻」。上图的这位就表示,eager 模式的确是 TF 版本更新迭代的正确方向(毕竟去掉了 session 这个万恶之源,支持动态图),但是引入 Keras 却让 API 又变得更混乱了。现在人们有多种构建模型的方法:tf.keras、tf.function 等等。
这些都是 TF2.0 目前遇到的问题,但是距离其第一个版本——alpha 发布已过去大半年,为什么还有这么多问题困扰着开发社区呢?机器之心通过整理过去发布的资料认为,TF2.0 的设计思路可能有一些问题,导致原本朝着易用性发展的框架又变得难用了。
TensorFlow2.0 本身的定位是:减少复杂和冗余的 API,降低用户的使用门槛,推动它向研究领域和深度学习普及方向发展。这一思路是正确的,但是在实际的设计阶段,为了实现以上目的而采用的解决方法并不正确,最终导致 TF2.0 依然难用。
Keras 是一个封装了 TF 等深度学习框架的代码库,具有很好的易用性。TensorFlow 为了解决饱受诟病的上手困难问题而引入了 Keras 的 API。但是从 TensorFlow 的定位和功能来看,和 Keras 的结合在目前来说不够成功。
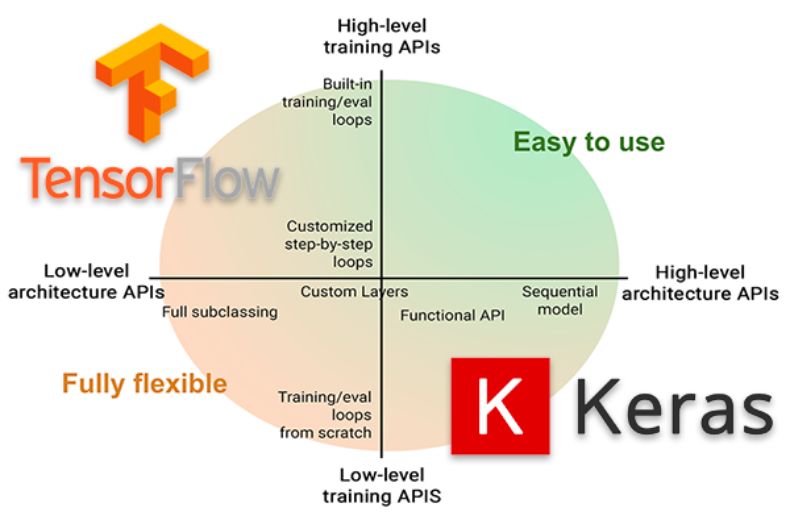
如下图所示,TensorFlow 本身在架构上有着细粒度很高的低级 API,这样的框架很适合进行各种方面的定制。但是 Keras 则正好和它相反,用户不知道底层的架构如何搭建,只需要关注整体的设计流程即可。
这两个框架可以说是两种极端,而在 TF2.0 里使用了一种妥协性的兼容形式:TF2.0 本身仿照 PyTorch 的方法构建灵活的模型,而不需要这种设计的用户则使用 tf.keras 高级 API。这样割裂的 API 使得用户有些不知所措,也加大了他们在寻找教程的难度,因为他们除了搜索 TF2.0 的同时还需要搞清楚:这个教程是关于 TF2.0 本身的,还是关于 tf.keras 的。
![]()
图源:
https://www.pyimagesearch.com/2019/10/21/keras-vs-tf-keras-whats-the-difference-in-tensorflow-2-0/
这就有点类似 TF1.x 时代各种各样的 API 混杂的情况——同一个功能可以由不同的 API 实现。但是,在不同的功能 API 进行组合的时候,某些 API 之间可能不兼容。
例如,我使用了 tf.keras,以 model = tf.keras.Sequential 的方式构建了一个网络,它的 training loop 是什么样的?我应该使用 model.fit() 吗?还是 with tf.GradientTape() as Tape ? 如果我想要自定义损失函数中某个标签的损失,我该在哪里修改?
多余的 API 增加了额外的学习成本,自然就让用户产生很多新的疑问。而这些疑问和错误如果没有及时解决,就会让用户丧失使用这个框架的兴趣。
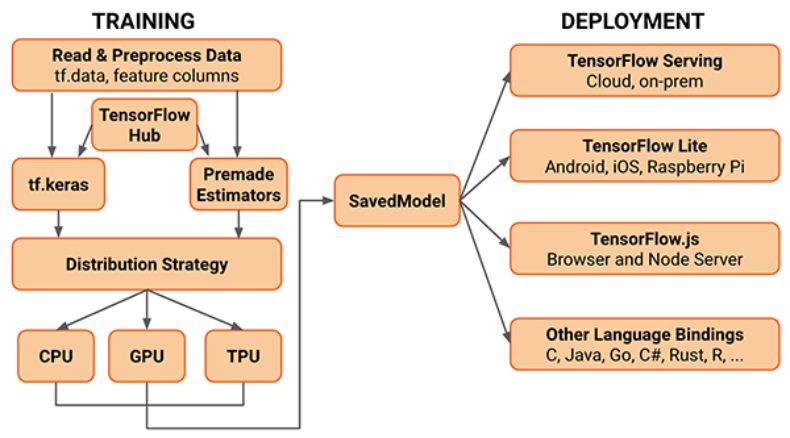
更何况,在分布式训练、数据并行/模型并行的需求下,框架越复杂,用户就越难上手。TF2.0 的框架已经非常复杂了。
![]()
现在的 TF2.0 架构已经非常复杂。图源:https://www.pyimagesearch.com/2019/10/21/keras-vs-tf-keras-whats-the-difference-in-tensorflow-2-0/
另一个麻烦的问题是,TF 2.0 无疑想让它成为研究领域和生产领域都非常流行的深度学习框架。因此在版本更新的时候一步大跨越,砍掉了很多 1.x 时代的 API,希望让追求简单特性的用户能够使用它。
但是别忘了,生产级的代码产品很怕的就是——突如其来的、没有向下兼容的版本更新。很多企业一旦部署了某个模型,就会希望它能够稳定支撑业务运行多年。除非有切实的需要(安全性问题、性能需要极大更新),否则他们是没有很大动力要更新的。
但是,为了吸引新用户使用 TF2.0,官方就大手一挥砍掉了很多 API,还不兼容旧版本。考虑到重新开发、训练、部署模型的成本,以及这个过程中对企业业务造成的可能影响,业界对于这种更新兴趣缺缺。更不用说,在新版本居然还有致命的 bug 的情况下。
在今年一月,用户发现 TF2.0 的 tf.keras API 中的 dropout 居然失效。虽然是测试版的问题,但是面对这样不稳定的更新,没有几个用户敢更新使用。
更不用说版本更新给开源社区带来的影响,很多开发者需要重新开始学习 2.0。从 1.x 到 2.0 的学习成本,这也是他们觉得 TF2.0 难用的一个原因。
此外,从时间上来看,TensorFlow 的推出要比 PyTorch 早好几年,但最近却被 PyTorch 步步紧逼。此前就有人猜测,TF 的团队可能分了三部分,一路人忙着开发 2.0,一路人忙着改变 eager,还有一部分人着力重构 Keras。这种分散精力的做法可能大大削弱 TensorFlow 在用户体验方面的投入,所以造成现在「怨声载道」的局面。
现在,TensorFlow 和 PyTorch 依然维持着「业界 vs 学界」分庭抗礼的局面。但是随着 PyTorch 的高歌猛进,这样的局面可能不久就会变化。
https://www.reddit.com/r/MachineLearning/comments/e4pxqp/d_ive_been_switching_over_from_pytorch_to_tf_20/
https://www.reddit.com/r/MachineLearning/comments/ajqmq9/d_tfkeras_dropout_layer_is_broken/
重磅!CVer学术交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
麻烦给我一个在看!