百度开源高性能 Python 分布式计算框架 Bigflow
开源最前线(ID:OpenSourceTop) 猿妹 整编综合自:https://spectrum.ieee.org/computing/software/webassembly-will-finally-let-you-run-highperformance-applications-in-your-browser
百度近日开源了一套计算框架 Bigflow , 致力于提供一套简单易用的接口来描述用户的计算任务,并使同一套代码可以运行在不同的执行引擎之上。
Python 分布式计算框架 Bigflow
授权协议:Apache
开发语言:Python
操作系统:跨平台
开发厂商:百度
Github:https://github.com/baidu/bigflow
Bigflow 简介
Baidu Bigflow (以下简称Bigflow)是百度的一套计算框架, 它致力于提供一套简单易用的接口来描述用户的计算任务,并使同一套代码可以运行在不同的执行引擎之上。
它的设计中有许多思想借鉴自 google flume java 以及 google cloud bigflow ,另有部分接口设计借鉴自 apache spark 。
用户基本可以不去关心 Bigflow 的计算真正运行在哪里,可以像写一个单机的程序一样写出自己的逻辑, Bigflow 会将这些计算分发到相应的执行引擎之上执行。
Bigflow Python 是一个致力于简化分布式计算任务编写和维护的 Python module,它提供了对分布式数据和计算的高层抽象,你可以使用这些抽象来编写分布式计算程序。Bigflow Python能够将这些抽象映射到不同的分布式计算框架之上。
Bigflow Python 中最重要的抽象被称为 P 类型 ,P 类型是分布式数据的抽象描述,非常类似于 Spark 中的RDD。第二个抽象概念为 SideInputs ,它指被广播到计算中去的 P 类型或是 Python 变量。通常而言,一个计算将被并行地在计算集群中执行,这时每个计算切片都能够得到SideInputs来满足计算的需求(例如查字典)。
Bigflow 的目标
Bigflow 的目标是: 使分布式程序写起来更简单,测起来更方便,跑起来更高效,维护起来更容易,迁移起来成本更小。
目前 Bigflow 在百度公司内部对接了公司内部的批量计算引擎DCE(与社区Tez比较类似),迭代引擎 Spark,以及公司内部的流式计算引擎Gemini。在开源版本中,目前仅开放了 Bigflow on Spark。
Bigflow 特性
虽然 Bigflow 目前仅仅开源了 Bigflow on Spark,但 Bigflow on Spark 仍有许多出色的特性:
● 高性能
Bigflow 的接口设计使得 Bigflow 可以感知更多的用户需求的细节属性,并且 Bigflow 会根据计算的属性进行作业的优化;另其执行层使用 C++ 实现,用户的一些代码逻辑会被翻译为 C++ 执行,有较大的性能提升。
在公司内部的实际业务测试来看,其性能远高于用户手写的作业。根据一些从现有业务改写过来的作业平均来看,其性能都比原用户代码提升了 100%+。
开源版本的 benchmark 正在准备中。
● 简单易用
Bigflow 的接口表面看起来很像 Spark,但实际实用之后会发现 Bigflow 使用一些独特的设计使得 Bigflow 的代码更像是单机程序,例如,屏蔽了 partitione r的概念,支持嵌套的分布式数据集等,使得其接口更加易于理解,并且拥有更强的代码可复用性。
特别的,在许多需要优化的场景中,因为 Bigflow 的可以进行自动的性能以及内存占用优化,所以用户可以避免许多因 OOM 或性能不足而必须进行的优化工作,降低用户的使用成本。
● 在这里,Python 是一等公民
我们目前原生支持的语言是 Python。使用 PySpark 时,有不少用户都困扰于PySpark的低效,或困扰于其不支持某些 CPython 库,或困扰于一些功能仅在 Scala 和 Java 中可用,在PySpark中暂时处于不可用状态。
而在 Bigflow 中,Python 是一等公民(毕竟当前我们仅仅支持 Python),以上问题在 Bigflow 中都不是问题,性能、功能、易用性都对 Python 用户比较友好。
Bigflow 后端引擎
目前,Bigflow Python 支持两种后端执行引擎:
● Local – 一个轻量的本地执行引擎,便于学习以及基于小数据集的算法验证。
● Spark – 开源分布式计算引擎。
后端执行引擎可以在创建 Pipeline 的时候指定,例如:

Bigflow 配置
Hadoop 配置
Bigflow Python需要读取core-site.xml配置文件来访问HDFS。因此在使用时,用户需要首先设置好HADOOP_HOME环境变量。
bigflow-env.sh
bigflow-env.sh 位于 BIGFLOW_PYTHON_HOME/bigflow/bin 下,其中包含一些Bigflow Python 在运行时的可选参数。
● Bigflow Python 默认将 log 打印到屏幕,用户可以通过改变下面的参数来指定 Log 的输出文件:

● 对于一个 P 类型 PValue,默认的 str(PValue) 仅会得到一个表示其具体类别的字符串。也即`print PValue`不会真正地触发计算。这时,如果希望看到一个P类型的内容,可以调用 PValue.get()
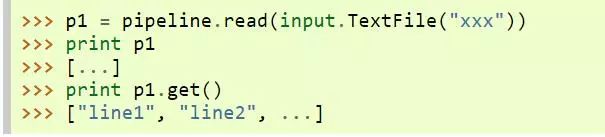
用户可以设置下面的变量来改变`str(PValue)`的行为
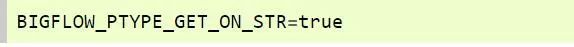
这时,每次`print PValue`都会隐式地执行`PValue.get()`:

这样做的好处在于可以使 Bigflow Python 写出的代码更像一个单机程序。
Bigflow 在线试用
在线试用网页 包含了一些简单的例子介绍 Bigflow 的概念和 API 用法,同时也可以在线编写 Python 代码尝试 Bigflow 的功能,可智能提示。(http://180.76.236.159:8732/?token=9a1bd5c7aeb2b217bef4e85c007f275e82744ba33f42eaf9)(密码:bigflow)
●本文编号477,以后想阅读这篇文章直接输入477即可
●输入m获取文章目录

↓↓↓ 点击"阅读原文" 进入GitHub详情页




