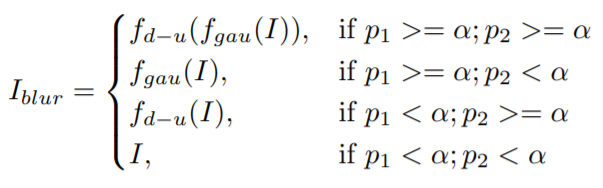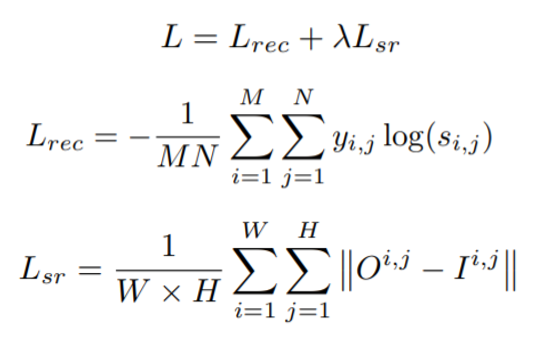加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
导语:自然场景文本识别是计算机视觉领域的一个经典问题,并被广泛使用于无人驾驶、视觉识别等领域。不同于电脑中的文本识别,自然场景中所采集的文本,往往包含着大量低质量的图像,这对于目前的文本识别器来说是一个相当棘手的问题。为此,ImageDT图匠数据联合华中师范大学提出,“PlugNet:一种基于可插拔的超分辨学习单元的文本识别方法”( PlugNet: Degradation Aware Scene Text Recognition Supervised by a Pluggable Super-Resolution Unit),显著提升了通用文本识别方法在低质量文本上的识别效果,并在更加广泛的通用文本基线数据集中取得了目前最佳的性能。目前,这项研究工作已经被欧洲计算机视觉大会(ECCV2020)收录。
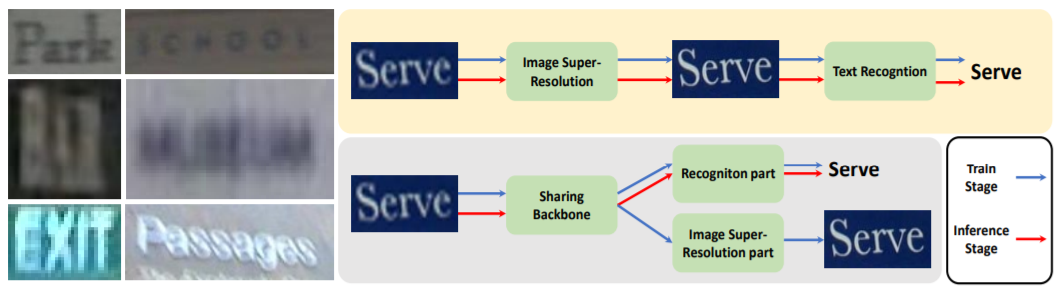
如图1所示,此前,解决模糊问题往往需要依赖于串联一个大型的超分辨网络来进行图像级的超分辨学习,以此改善输入图像的质量。这种方案往往需要依赖有力的数据集划分以及大量的计算资源,在实际应用中显得并不具有性价比。
因此,作者提出了一个含有可插拔超分辨单元的端到端学习的文本识别方法(PlugNet)。通过在训练时增加超分辨支路来改善特征表达的方式提升低质量文本的识别结果,这也就意味着相对于原始的文本识别方案,PlugNet在应用时(前向计算)没有增加任何额外的计算量。
1、利用特征级超分辨学习来增加用于识别特征的鉴别能力,进而提升文本识别结果的精度。
2、针对原始文本识别方法使用CNN压缩图像分辨率的问题,提出了使用特征压缩模块进行替代,尽可能的更好的保留特征原始的空间特性。
3、算法训练时间无显著增加,推理时间不变的情况下,低质量图像精度显著提升,非常有利于对实时和精度要求较高的应用场景。
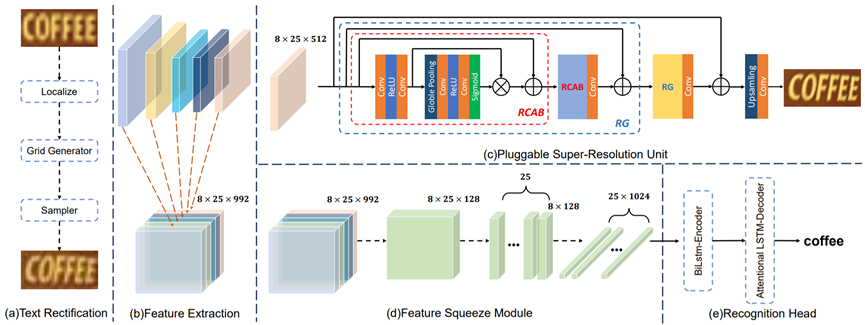
如图2所示,PlugNet的构建基于自顶而下的文本识别方案,共包含五个模块,分别是校正模块、特征提取模块、特征压缩模块、识别模块和可插拔的超分辨单元。
1、校正模块:使用一个简单的浅层卷积神经网络预测了20个关键点位置来约束文字的上下边缘,并通过TPS方法从原始的图像中采样得到校正图像。
2、特征提取模块:沿袭了ResNet的结构作为主干网络,选取了四倍下采样的特征图来作为最终的特征尺度。为了更好的将底层特征引入到识别的部分中,作者使用了一个特征增强块,通过将不同层的特征下采样并进行通道融合,让最终的特征能够获取多元化的语义信息。
3、特征压缩模块:通过1*1降维和Reshape的方式,从特征提取模块输出的特征中,获取到输入到识别模块的1维向量。在传统的文本识别方案中,常使用CNN来进行特征的压缩,但是在过去两年的研究中发现,CNN对于空间特征显得并不敏感,这在一定程度上使得过去的文本识别方法的校正部分,不能够很好的对文本的上下边缘进行预测。因此,PlugNet采用了更为直接的手段,采用特征压缩模块取代了传统的CNN压缩,更多的保留了原始的空间位置信息。
4、识别模块:使用基于LSTM的Encoder-Decoder架构,这种方案在过去的数年中,在文本识别领域取得了极佳的效果。因此,PlugNet在识别部分仍然沿用了这一方案,通过将特征压缩模块得到的一维向量输入到双向LSTM的Encoder和基于注意力机制的Decoder结构,最终输入文本识别的结果。
5、可插拔超分辨单元:使用了2个基于Resnet结构的超分辨基础单元和一个上采样部分,将共享的特征恢复成原始图像对应的超分辨图像。为了更好的训练超分辨单元、改善特征的表达,使用了如下两种特征增强的方式:高斯模糊和4倍上下采样。其生成方式可以表示为:
其中,和分别代表4倍上下采样和高斯模糊处理,和是两个随机参数,是文章中所使用的阈值。
在损失函数部分,作者使用了一个比较通用的多任务形式,总的损失由文本识别部分的交叉熵损失和超分辨部分的L1损失构成,并使用了一个超参数对两个部分的权重进行调节,这部分可以描述为:
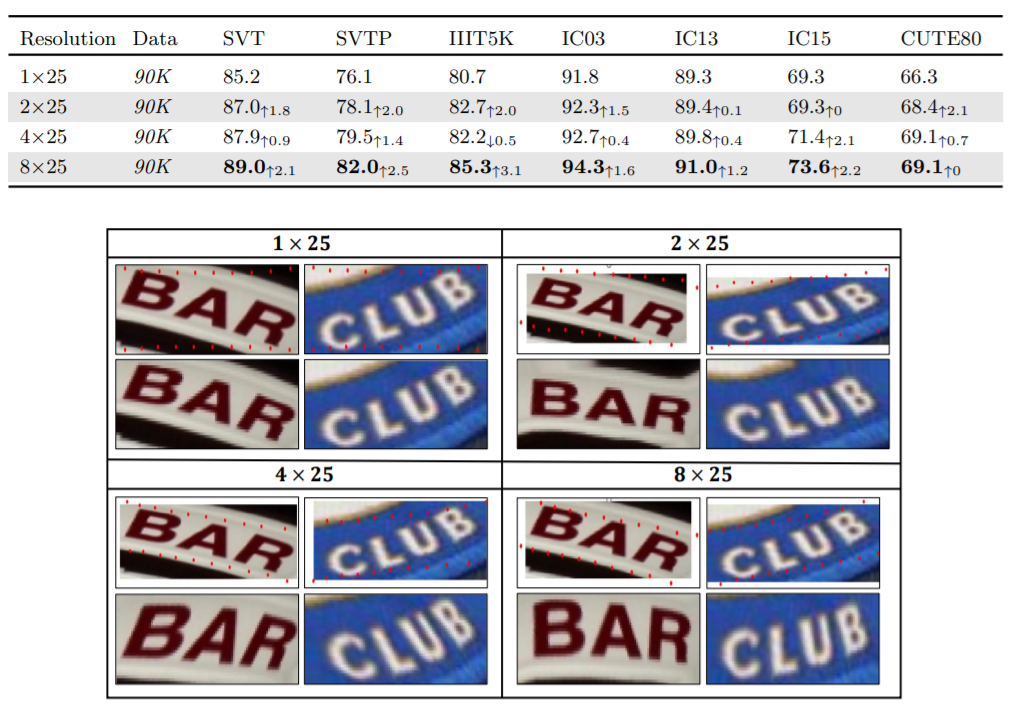
作者选取了文本识别领域应用最为广泛的7个数据集进行测试,分别是SVT, SVTP, IIIT5K, ICDAR2003, ICDAR2013, ICDAR2015以及CUTE80。实验的第一部分讨论了不同的特征分辨率对于文本识别的影响。为了保证公平性,对于不同的特征分辨率,实验通过调整1*1卷积的维度,确保Reshape后的特征尺度的完全相同。从下面的图表可以看到,特征分辨率的提升有效的帮助校正模块定位到文字部分的边界,从而改善了文本识别的性能。
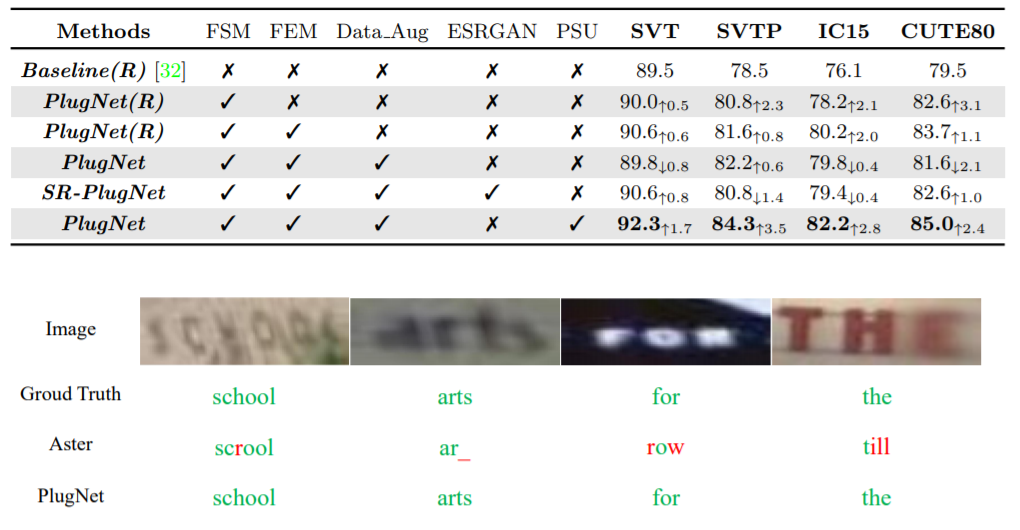
如下图所示,作者也对所提出的模块和方案进行了相应的消融实验以证明其作用,尤其是在模糊文本的识别问题上,PlugNet的表现相较于之前的文本识别方法有着较明显的改善。
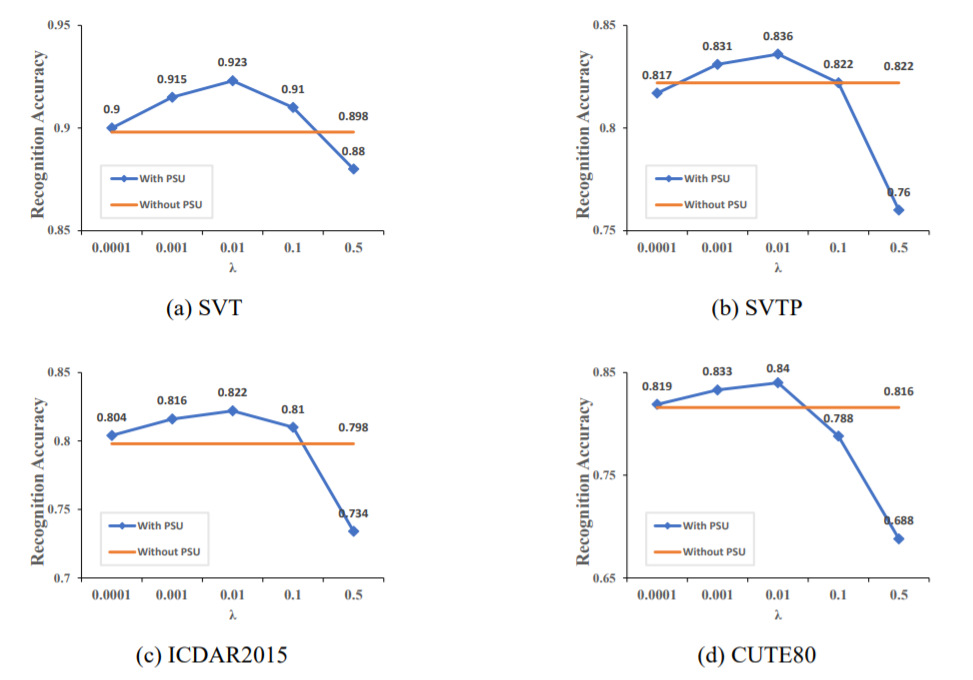
当然,作者也讨论超参数的影响,下面的图展示了不同的情况下识别准确率和共享特征的变化。
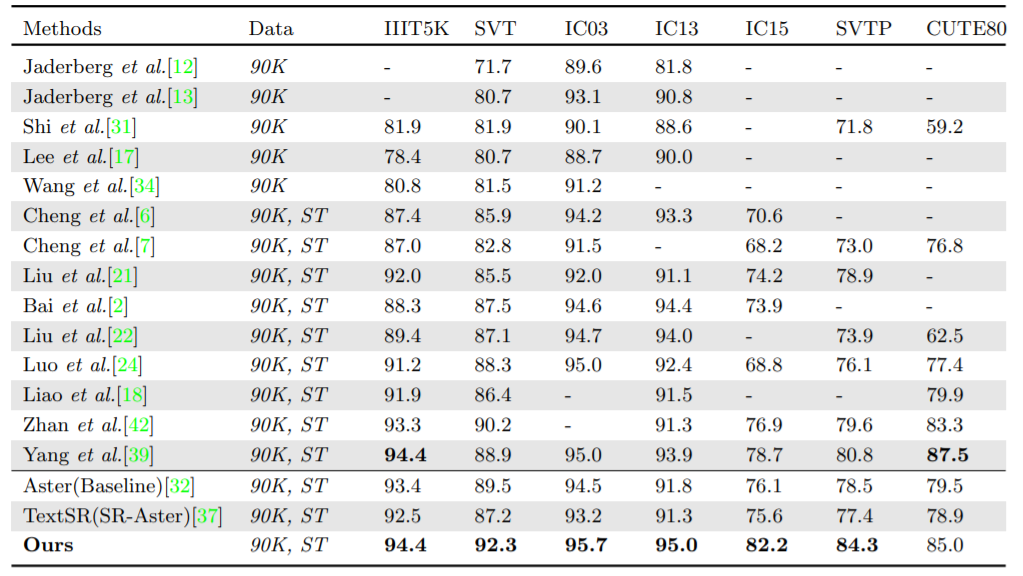
最后,实验在大量的通用文本数据集上与其他SOTA的方法进行了比较。PlugNet在所有的7个数据集中取得了6个数据集的最佳结果,尤其是在模糊文本较多的SVT数据集中相较于其他方法有着较大的领先。
总的来说,PlugNet提出了一种端到端可训练的退化感知场景文本识别器, 该方法结合可插拔超分辨率单元(PSU)从特征层解决低质量文本识别问题。它只在训练阶段进行可接受的额外计算,在推理阶段不需要额外的计算,最大程度减小了网络模型的大小和训练难度,并在模糊文本识别问题上取得了极佳的效果。这种通过超分辨学习来改善特征的网络设计方式,相比于传统的图像级超分辨学习方案,摒弃了在应用中使用大型而复杂的超分辨网络,联合照片质量恢复技术,从特征层面提升表达能力,确实让人耳目一新。这未尝不是超分辨方法在实际场景中一种更加简单的应用新思路。相信这项工作所提出的方案,在其他研究领域也将会有更为广泛的应用前景。
![]()
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()