谈谈过度设计:因噎废食的陷阱

引言
为什么长期来看,设计模式相比过程式代码是更好的?
什么情况下设计模式是有益的,而什么情况下会成为累赘?
如何利用设计模式的益处,防止其腐化?
设计模式的缺陷
开闭原则的缺陷
开闭原则:软件中对象应该对扩展开放,对修改关闭。
最小知识原则的缺陷
最小知识原则:一个对象对于其他对象的了解越少越好。
// 绩效int performance = 4;// 职级int level = 2;String job = "engineer";switch (job) {case "engineer":// 虽然计算薪资时只使用了 绩效 作为参数, 但是从上下文中都是很容易获取的return 100 + 200 * performance;case "pm":// .... 其余代码省略}
// 绩效int performance = 4;// 职级int level = 2;String job = "engineer";// 只传递了需要 performance 参数Context context = new Context();context.setPerformance(performance);strategyMap.get(job).eval(context);
可理解性的缺陷
策略模式在内的几乎所有设计模式都使用了多态
访问者模式需要理解动态分派和静态分派
-
...
小结
过程式编码的本质缺陷
“简单”:业务逻辑不会因为过程式编码而变得更加简单,相反,越是大型的代码库越会大量使用设计模式(比如拥有 2400w 行代码的 Chromium);
“好理解”:过程式编码只是短期比较好理解,因为没有设计模式的学习成本,但是长期来看,因为它没有固定的模式,理解成本是更高的;
“易于修改”:这一点我相信是对的,但是设计模式同样也可以是易于修改的,下一节将会进行论述,本节主要论述前两点。
软件复杂度
理解单一问题 vs 理解一类问题
public void printTree(TreeNode root) {if (root != null) {System.out.println(root.getVal());preOrderTraverse1(root.getLeft());preOrderTraverse1(root.getRight);}}
public int countNode(GraphNode root) {int sum = 0;Queue<Node> queue = new LinkedList<>();queue.offer(root);root.setMarked(true);while(!queue.isEmpty()){Node o = queue.poll();sum++;List<Node> list = g.getAdj(o);for (Node n : list) {if (!n.isMarked()) {queue.add(n);n.setMarked(true);}}}return sum;}
public void printTree(TreeNode root) {Iterator<TreeNode> iterator = root.iterator();while (iterator.hasNext()) {TreeNode node = iterator.next();System.out.println(node);}}
public int countNode(GraphNode root) {int sum = 0;Iterator<TreeNode> iterator = root.iterator();while (iterator.hasNext()) {iterator.next();sum++;}return sum;}
看到 XxxObserver,XxxSubject 就知道这个模块是用的是观察者模式,其功能大概率是通过注册观察者实现的
看到 XxxStrategy 策略模式,就知道这个模块会按照某种规则将业务路由到不同的策略
看到 XxxVisitor 访问者模式 就知道这个模块解决的是嵌套结构访问的问题
...
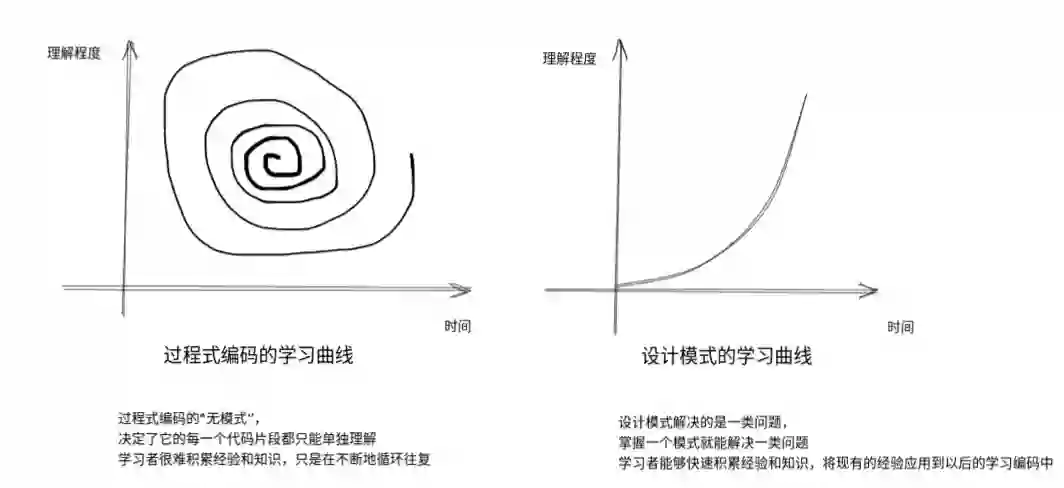
过程式编码虽然刚开始时没有任何学习压力,但是不会有任何积累。设计模式虽然刚开始时很难懂,但是随着学习和应用,理解会越来越深刻。
设计模式防腐
腐败的设计模式
有一条恶龙,每年要求村庄献祭一个少女,每年这个村庄都会有一个少年英雄去与恶龙搏斗,但无人生还。
又一个英雄出发时,有人悄悄尾随,龙穴铺满金银财宝,英雄用剑刺死恶龙。然后英雄坐在尸身上,看着闪烁的珠宝,慢慢地长出鳞片、尾巴和触角,最终变成恶龙。
无法调试: 新的维护者无法通过调试快速学习模块中的 “模式”,或者说因为学习成本太高,人们常在没有弄清楚“模式”的情况下就着手改代码,越改越离谱,最终覆水难收
-
没有演进: 系统中的设计模式也是要跟随业务不断演进的。但是现实中很多系统发展了好几年,只在刚开始创建的时候进行过一次设计,后来因为时间紧或者懒惰等其他原因,再也没有人改过模式,最终自然跟不上业务,变成系统中的累赘。
可调试的模块
模块可以是一个独立的系统。由多个微服务构成的一个系统,每个微服务可以认为是一个 “模块”;
-
在同一个应用中 和一个功能相关的对象集合也可以认为是一个模块。
模式演进
interface Strategy {void doSomething();}class AStrategy implements Strategy {//... 代码省略}class BStrategy implements Strategy {//... 代码省略}及// 业务代码class AService {private Map<String, Strategy> strategyMap;public void doSomething(String strategy) {strategyMap.get(strategy).doSomething();}}
class AService {private Map<String, Runnable> strategyMap;static {strategyMap.put("a", this::aStrategy);strategyMap.put("b", this::bStrategy);}public void doSomething(String strategy) {strategyMap.get(strategy).run();}private void aStrategy() {//...}private void bStrategy() {//...}}
小结
构造可调试的模块,保证后来的维护者能够通过调试快速理解设计。
-
在业务发展中不断探索最合适的模式。
开发效率与系统的成长性
// 统计 a 控件的总数public int countComponentAB(Form form) {int sum = 0;for (Component c: form.getComponents()) {if (c.getType() == "A") {sum++;} else if (c.getType == "Table") {// 明细控件含有子控件for (Component d: c.getChildren()) {if (d.getType() == "A") {sum++;}}}}return sum;}
// 返回表单中所有的 A 控件和 B 控件public List<Component> getComponentAB(Form form) {List<Component> result = new ArrayList<>();getComponentABInner(result, form.getItems());return result;}private getComponentABInner(List<Component> result, List<Component> items) {for (Component c: items) {if (c.getType() == "A" || c.getType() == "B") {result.add(c);} else if (!c.getChildren().isEmtpy()) {// 递归访问子控件getComponentABInner(result, c.getChildren());}}}
第一段代码只展开了一层子控件,但是审批表单是支持多层子控件的
-
第二段代码虽然用递归支持了多层子控件,但是并不是所有的子控件都属于当前表单(前面提到过,审批支持关联其他比表单的控件)
// 统计 a 控件的总数class CountAVisitor extends Visitor {public int sum;public void visitA(ComponentA a) {sum++;}}public int countComponentAB(Form form) {CountAVisitor aVisitor = new CountAVisitor();// 遍历逻辑统一到了 accept 中form.accept(aVisitor);return aVisitor.sum;}
// 返回表单中所有的 A 控件和 B 控件class GetComponentABVisitor extends Visitor {public List<Component> result;public void visitA(ComponentA a) {result.add(a);}public void visitB(ComponentB b) {result.add(b);}}public List<Component> getComponentAB(Form form) {GetComponentABVisitor abVisitor = new GetComponentABVisitor();form.accept(abVisitor);return abVisitor.result;}
关于 Visitor 模式的细节,可以参考我的另一篇文章 重新认识访问者模式。
幸福的家庭都是类似的,不幸的家庭各有各的不幸。
因噎废食的陷阱
软件工程师的成长
互联网精耕细作的新时代
本文的边界情况
真理是有条件的。
一次性脚本,没有多次阅读和修改的可能。我自己在写工具类脚本时也不会去应用模式,但是我相信阿里巴巴的应用代码,100% 都是要被反复阅读和修改的。
真的很简单的模块。前文提到过 ”模块应该是深“,如果这个模块真的很简单,它或许抽象不足,我们应该将它和其他模块整合一下,变得更加丰满。如果应用中抽不出复杂模块,那可能不是事实,只是我们的实现方式太简单了(比如全是过程式编码),反过来又对外宣称 ”我们的业务很复杂“。
-
团队内都是喜欢攀比代码设计的疯子,需要告诫警醒一下。真的有团队达到这个程度了吗?如果到了这个程度,才可以 “反对设计”。
参考:
[1]《人月神话》
[2]《软件设计哲学》
[3]《Java 8 实战》
[4]《设计模式 - 可复用的面向对象软件元素》
[5]《大话设计模式》
[6] 代码重构:面向单元测试
[7] 重新认识访问者模式
[8] 对抗软件复杂度的战争