字符级NLP优劣分析:在某些场景中比词向量更好用
选自LightTAG
机器之心编译
参与:熊猫
在解决 NLP 问题时,你选择的基本处理单位是词还是字符?LightTag 近日的一篇博文介绍了字符级 NLP 模型的优势和短板,并介绍了一些更适合字符级模型的应用场景。需要注意的是,本文主要围绕英语等单个字符无具体意义的语言编写,对于汉语这种词与字符之间存在很多重叠的语言,或许还需要一些新的思索。
NLP 系统就像人生一样,充满了选择与权衡。其中一个选择是指定我们的模型所看到的最小单位。通常而言,我们处理语言的方式是处理「词(word)」。本文则将探索另一个不太直观的选择——字符(character),并将介绍字符级处理方式的优缺点。
字符级模型放弃了词所具有的语义信息,也放弃了即插即用的预训练词向量生态系统。另一方面,字符级深度学习模型又有两个基本优势:它们能缓解我们在模型输入上遇到的词汇库问题,还能避免在模型输出上的计算瓶颈。
在输入方面,它们能极大地提升我们的模型所能处理的词汇量,并且能弹性地处理拼写错误和罕见词问题。在输出方面,由于字符级模型的词汇库很小,所以计算成本更低。这样的性质使得在预算有限时也能使用某些训练技术(比如联合训练一个语言模型)并达到较快的训练速度。
本文将按以下结构展开。我们首先会介绍我们在词层面常遇到的且可用字符级模型解决的问题。因为字符级模型不够直观,所以我们会看看它们是否能学习到重要的信息,并会展示一些解决这一问题的研究。然后我们会讨论在字符层面处理语言的优势和缺点,最后会以解决这一问题的其它技术作结。
油井分析——一个启发示例
WellLine 提供了「用于油井优化的 AI 驱动的油井时间线」,并且也是 LightTags 最早的客户之一。他们的一部分成果是将自然语言处理技术应用于人类书写的每个油井的生产日志。

使用 LightTag 标注的油井日志
WellLine 的数据域几乎算得上是一种英语次级方言。很多词都是英语,但也有很多不是,其中有很多只有领域专家才能理解的缩写和行话。因为这个域的数据在互联网上并不充裕,词向量等常用的预处理 NLP 解决方案并没有适合 WellLine 的词汇库。
在 WellLine 这个情况中,度量和单位都很重要,但在应用模型之前将它们 token 化可能会有问题。比如标注为「Rig Equipment」的「9 7/8" BHA」这一项;标准的 token 化方法(对词有标准的假设)会将这些数字分开,让我们得到 [9,7,/,8,"]。要得到更准确的 token 化方法,需要大量领域专业知识和工程开发工作。
行业内的很多 NLP 用例都遵循相似的模式,尽管相关文本的语言是英语,但它们往往都有特有的词汇、缩写和标点符号,甚至还有挑战传统的 token 定义的表情符号。正如我们之前看到的那样,使用了标准 token 化假设的直接可用的解决方案往往无法达到预期的目标。但是,构建一个领域特定的 token 化器又可能需要非常多的时间和金钱。
在这样的案例中,我们认为使用字符级模型更合理。它们的使用场景可能远远超出你的预料——不管是用于处理金融聊天、政治推文、生物学记录、医药处方文本,还是用于希伯来语或阿拉伯语等形态丰富的语言。通常而言,我们并不关心整个词汇库的 token 化或语义。我们只关心能否在这些文本中找到我们需要的信息。
在这些情况中,字符级模型能给出让人信服的结果。根据定义,字符级模型能让我们免去 token 化的麻烦,从而让我们可以处理任意大小的词汇库,而且计算成本也很低,这有助于无 TPU pod 的预训练和联合训练技术。
字符级模型有效吗?
尽管字符级模型听起来很有潜力,但它们确实也违反直觉。词有语义含义,字符则没有,因此我们不能显然地预期模型能够通过处理字符来学习了解一段文本的语义内容。幸运的是,我们站在巨人的肩膀上,我们来看看他们的一些工作成果。
字符级模型可以学习非平凡的句法
2015 年时,Andrej Karpathy 发表了《循环神经网络不合理的有效性》https://karpathy.github.io/2015/05/21/rnn-effectiveness/,其中他训练了一个可以写出基本上合理的 C 代码的循环神经网络。下面是一个来自他的文章的示例:
/*
* Increment the size file of the new incorrect UI_FILTER group information
* of the size generatively.
*/
static int indicate_policy(void)
{
int error;
if (fd == MARN_EPT) {
/*
* The kernel blank will coeld it to userspace.
*/
if (ss->segment < mem_total)
unblock_graph_and_set_blocked();
else
ret = 1;
goto bail;
}
segaddr = in_SB(in.addr);
selector = seg / 16;
setup_works = true;
for (i = 0; i < blocks; i++) {
seq = buf[i++];
bpf = bd->bd.next + i * search;
if (fd) {
current = blocked;
}
}
rw->name = "Getjbbregs";
bprm_self_clearl(&iv->version);
regs->new = blocks[(BPF_STATS << info->historidac)] | PFMR_CLOBATHINC_SECONDS << 12;
return segtable;
}
Yoav Goldberg 在 Karpathy 的这篇博客下跟了一个评论:
很厉害,对吧?网络是怎么学会模仿这样的输入的?确实如此,我也觉得相当了不起。但是,我觉得这篇文章的大部分读者感到震撼的原因是错误的。这是因为他们不了解非平滑的最大似然字符级语言模型以及它们在生成相当可信的自然语言输出上那不合理的有效性。……在我看来,一次一个字符地生成英语并没有那么厉害。这个 RNN 需要学习之前 nn 个字母,其中 nn 比较小,就是这样。
但是,这个生成代码的例子却非常厉害。为什么?因为上下文感知。注意,在这里贴出的所有例子中,代码是有很好缩进的,大括号和小括号嵌套正确,甚至注释都有正确的开始和结束。这不是通过简单查看前 nn 个字母就能实现的。
从这个意义上讲,Karpathy 的演示表明我们可以合理地预期字符级模型能够学习和利用语言的「深度」结构。Karpathy 训练了一个语言模型,它本身虽然不是很有用,但我们还会回来解释我们为什么认为这表明了字符级模型在应用 NLP 上的出色能力。
字符级模型可以「理解」情绪
2017 年,OpenAI 发布了一篇博客和论文《Learning to Generate Reviews and Discovering Sentiment》介绍他们训练的一个字符级语言模型,这个模型是在亚马逊评论上训练得到的,结果发现该模型自己学会了识别情绪。该实验的一些细节让其听起来有些不切实际。
我们首先在一个包含 8200 万条亚马逊评论的语料库上训练了一个有 4096 个单元的乘法 LSTM,用来预测一节文本的下一个字符。训练过程在 4 个英伟达 Pascal GPU 上用去了一个月的时间,我们的模型每秒处理 12500 个字符。
尽管如此,其论文还指出这个字符级模型能够习得文本的语义属性,这主要来自第一原理(first principle)。
字符级模型能够翻译
DeepMind 的《Neural Machine Translation in Linear Time》和 Lee et al 的《Fully Character-Level Neural Machine Translation without Explicit Segmentation》展示了在字符层面上实现的翻译。这些结果尤其引人注目,因为翻译任务需要对基础文本有非常好的语义理解。
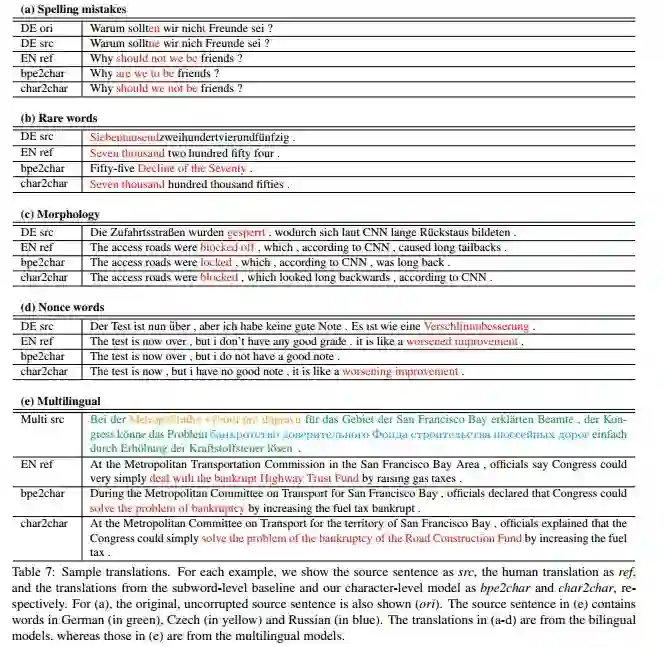
Lee 论文的模型有很好的弹性
DeepMind 论文的相关性可能会有些疑问,因为他们的模型使用的是卷积,而不是常用的 RNN/LSTM。实际上,这使得模型可以更快地训练,无需很大的计算预算或 TPU 集群就能进行迭代和探索。
在字符层面上处理的优势
了解了字符级模型的效果,我们来看看它们能带来哪些优势以及我们可能想要使用它们的原因。我们需要在两个地方在字符和词之间做出选择,即模型的输入和模型的输出。在输入方面,选择字符时词汇库要宽松得多,而且可以处理更长的序列(更多计算),但语义信息会减少。在输出方面,计算性能会有显著的提升,我们将在后面详述这一点。
字符级模型支持开放的词汇库
考虑一下下列来自深海石油钻井平台维护日志中的以下句子(是的,它们有日志):
Set 10 3/4" csg slips w/ 50K LBS.
它是说「设置十又四分之三英寸的…」,还是「设置十个四分之三英寸的…」。
slips 的后缀 s 提供了一个强有力的线索,告诉我们有 10 个数量的 3/4 英寸的 slip,所以第二种解读是对的。可以预料词级模型能轻松地解决这个问题,但是,我们需要问自己,我们的模型究竟会看到什么 token?
因为当我们在词层面操作时,我们必须事先选择一个词汇库,也就是说我们的模型可以处理的词汇列表是固定的,其它词都会被映射到 UNK(未知词)。一个宽松的模型的词汇库通常有 1-3 万个最常用的词。
在 GoogleNews 上训练的词向量不包含这些 token:10、3/4"、csg、w/、50K。
更进一步,与 slips 最接近的词是 slip、fall 等——表示模型认为 slip 是一个动词,slips 是动词的一种变形形式。也就是说,我们的模型会把句子「Set 10 3/4" csg slips w/ 50K LBS」读取为「Set UNK UNK UNK falls UNK UNK Location_Based」。
如果我们想要使用 NLP 来理解我们的油井中的情况,使用词向量(单纯地)会让我们很快迷失方向。另一方面,字符级模型对词汇库没有实际的限制,能以输入本来的样子读取它。回想一下 Goldberg 有关上下文的评论,很难想象字符级模型能够将表示复数的 s 后缀与 10 联系起来,从而「理解」10 是一个数量。
这样的优势并不局限于油井分析。将 NLP 应用于用户生成的文本是一种常见做法,这样的文本通常充斥着拼写错误、emoji、缩写、俚语、领域特定的行话和语法。最重要的是,语言还会不断演化出新的词汇和符号。尽管字符级模型不能解决人类文本的所有问题,但它们确实能让我们的模型更稳健地处理这样的文本。
字符级模型能移除训练任务的瓶颈
应用 NLP/文本挖掘的一个更常见问题是查找文本中的实体并消除歧义,比如上面例子中的「10」。也就是说,我们并不总是需要生成文本。但是,已经可以确信,在一个语言建模任务上联合训练或预训练我们的模型是有帮助的,原因包括:1)有助于泛化,2)减少一定验证准确度所需的标签的数量。
语言模型的目标是根据之前的 token 预测下一个 token。标准的做法是最后一层在词汇表的每个 token 上计算一个 softmax。当词汇库较大时,softmax 步骤和相关的梯度计算就会成为训练语言模型的性能瓶颈。
字符级模型因为一开始词汇库就很小,也就隐含地避免了这一问题。这让我们可以快速地预训练或联合训练一个与我们的主要目标一致的语言模型。尽管你确实可以通过投入更多预算、硬件和工程开发来克服这一瓶颈,但那同时也会推高你的开发和部署成本。事实上,涉及到应用 NLP 的业务都很看重投资回报率,最好还要快,而且可以投入到一个给定问题上的资金是有限的。
字符级 NLP 模型的缺点
字符级模型也并非万能,同样存在自己的缺陷。最显眼的两个缺陷是缺乏输入的语义内容(字符是没有意义的)以及输入长度的增长。英语的平均词长为 5 个字符,这意味着根据架构的不同,可以预期计算需求会有 5 倍的增长。
字符没有语义
放弃词的语义内容不是一个简单的决定,也不是常能在当前最佳系统中看到的。在写作本文时,Google 的 BERT 模型是当前最佳,并且在 100 种语言上预训练过。没有多少组织机构有运行 BERT 预训练的计算能力,所以不能轻易放弃使用这些模型。话虽如此,值得注意的是用于亚洲语言的 BERT 模型是在字符层面上有效工作的。
更长的序列会增加计算成本
在词层面进行有效的处理会将你的序列的长度乘以词的平均字符数。比如在英语中,词的平均字符数为 5,如果假设你按序列处理你的输入,那么你需要 5 倍的计算。使用字符级模型的一个重要理由是计算成本低,这似乎刚好适得其反。
这是一个实际存在的而且往往令人沮丧的缺点,但只有在你按序列处理你的输入时才会有这个问题。如果你愿意而且可以使用卷积(比如 Bytenet)或 Transformers(比如 BERT),那么模型固有的并行能力能有效地抵消长序列的成本。这仍然需要权衡,基本上而言,如果想要收获字符级模型的最大优势,对架构的选择会受到「温和的」限制。
你不关心字符
如果你要完成一个序列标注任务(比如命名实体识别),你可能并不在乎单个字符。你的模型应该要能分辨一个特定的词是否是实体,并会在那样的输出上得以衡量。使用字符级模型意味着你得到的输出也是字符级的,这会让你需要完成更多的工作。
还有更糟糕的呢。字符级模型不满足任何 token 化方案,肯定也不满足你选择用来评价你的模型的方案。可以推知,没有什么能阻止你的模型基于子词(subword)进行预测或者与你的 token 化方案(比如将你想要保留成一个 token 的缩略词分开)背道而驰。从效果上讲,这会引入一类新的误差,你在评估模型时需要考虑到这一点。
当然,这一问题也存在解决方案/补充方法。将 B-I-O 方案应用于你的模型是有帮助的,因为这能激励模型明确地学习词的边界。学习线性的 CRF 或使用波束解码器也有助于缓解这一问题。
针对字符级模型所能解决的问题的其它解决方案
正如我们之前说的那样,选择字符或词需要权衡,但两者之间也存在一个连续范围。有些方法集中了两者的优势,但可能也会有自己的缺点。这一节我们将看看其中一些方法,并讨论一下它们的相对优势和缺点。
使用大词汇库
在输入方面,字符级模型解决的主要问题是处理任意大小的大词汇库的能力,包括对拼写错误和其它人类文本差错的抗性。常用的方法有两种,但可能还有一些我们还不知道的方法。
有一类嵌入技术是用于在嵌入预训练过程中处理子词单元的。使用这些技术的最早期论文之一是《Neural Machine Translation of Rare Words with Subword Units》,其开篇写道:
神经机器翻译(NMT)模型通常用于处理固定大小的词汇库,但翻译是一个开放词汇库的问题。……在这篇论文中,我们引入了一种更简单且更高效的方法,让 NMT 模型可以通过将罕见和未知的词编码成子词单元的序列来执行开放词汇库的翻译。这基于这样一个直觉:不同的词类别可以通过比词更小的单位进行翻译,比如名字(通过字符层面的复制或转写)、复合词(通过翻译成分)、同源词和借词(通过语音和形态变换)。
这一类型的系统包括 Facebook 的 fastText、谷歌的 SentencePiece 和 SpaCy 的 HashEmbed(其依赖于 Bloom Embedding)。
我们的内部研究发现这些系统很令人沮丧。我们常常需要处理有丰富形态或领域的语言,其中单个字符都可能在句子中有不同的含义。在这些案例中,子词嵌入会遗落某些所需的东西。
Primer.ai 的 Leonard Apeltsin 曾写过一篇关于俄语 NLP 的文章:https://primer.ai/blog/Russian-Natural-Language-Processing/,其中,他在通过 RusVectors 构建的嵌入空间中查找了与词 Vodka 最近的词。RusVectors 是使用有关俄语形态学的知识构建的,这与 FastText 的情况不同。结果很有意思:
与 Vodka 最近邻的 RusVectors
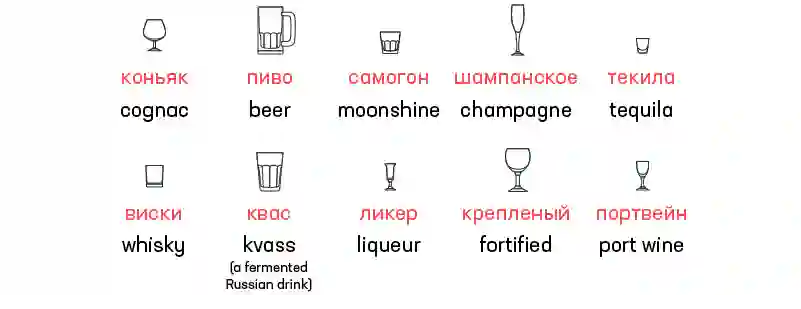
与 Vodka 最近邻的 FastText

与 Vodka(已包含曲折化)最近邻的 FastText

结合词嵌入与字符表征
另一个尤其引入关注的方法是既输入词嵌入,又处理每个词的字符,然后再将处理结果与对应的词向量连接起来。
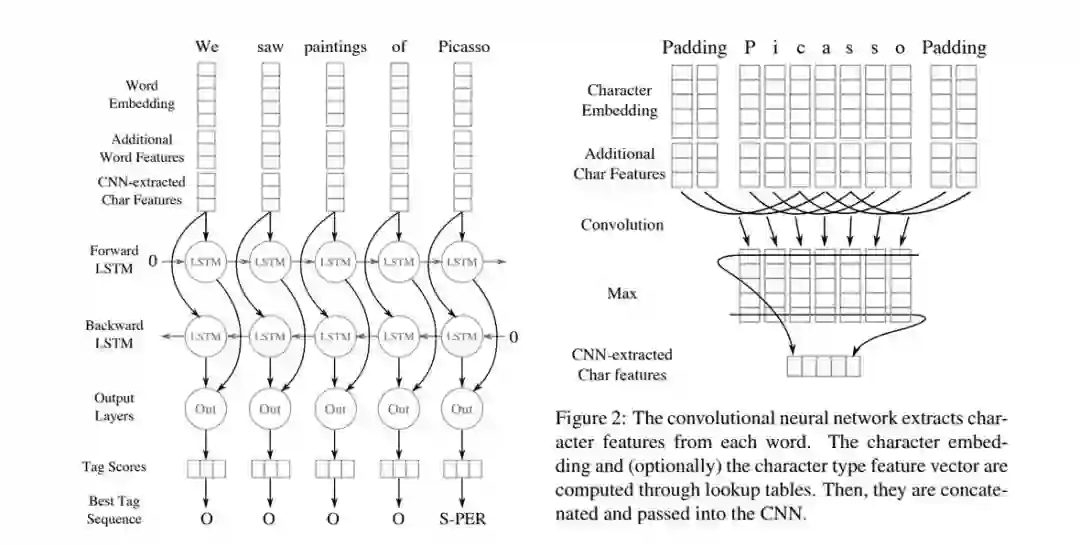
字符与词相结合,来自《Named Entity Recognition with Bidirectional LSTM-CNNs》
就词的形态而言,这种方法似乎是在子词单元上的改进。因为没有事先确认子词单元是什么,模型可以自由地学习「词」的最优表征方式。
降低 softmax 的成本
这些方法本身都没有缓解 softmax 层较大的问题,而我们可以看到这个问题常常是网络的性能瓶颈。通常来说,我们的核心 NLP 任务并不需要大的 softmax,但我们确实想要联合训练或预训练一个语言模型来提升我们的模型的性能和数据效率。
这一问题的解决方案分为两类。第一类是以某种更计算友好的方式近似 softmax。Sebastian Ruder 在他的博客中对 softmax 近似方法进行了出色的介绍:http://ruder.io/word-embeddings-softmax/
第二类是通过寻找替代目标来绕过 softmax。来自 Spacy 的 Matt Honnibal 一直在努力将这类方法加入 Spacy 库,在相关的一个 GitHub 问题中,他写道:
我的解决方案则是载入一个预训练的向量文件,然后使用向量-空间作为目标。这意味着我们仅需要预测为每个词预测一个 300 维的向量,而不是试图在 10000 个 ID 等事物上进行 softmax。这还意味着我们可以学习非常大的词汇库,这很能让人满意。
不幸的是,这项技术目前的结果并不好,Matt 给出了记录:https://github.com/honnibal/spacy-pretrain-polyaxon#experiment-2-ontonotes-ner-fasttext-vectors
该领域另一项有趣的工作是近期的《Semi-Supervised Sequence Modeling with Cross-View Training》:
因此,我们提出了 Cross-View Training(CVT),这是一种半监督学习算法,可混合使用有标注和无标注数据来提升 Bi-LSTM 句子编码器的表征。在有标注的样本上,我们使用标准的监督学习。在无标注的样本上,CVT 会教能看到输入的受限视角(比如句子的一部分)的辅助预测模块匹配能看到完整输入的整个模型的预测。因为辅助模块与完整模型共享中间表征,所以这反过来又能改进整个模型。
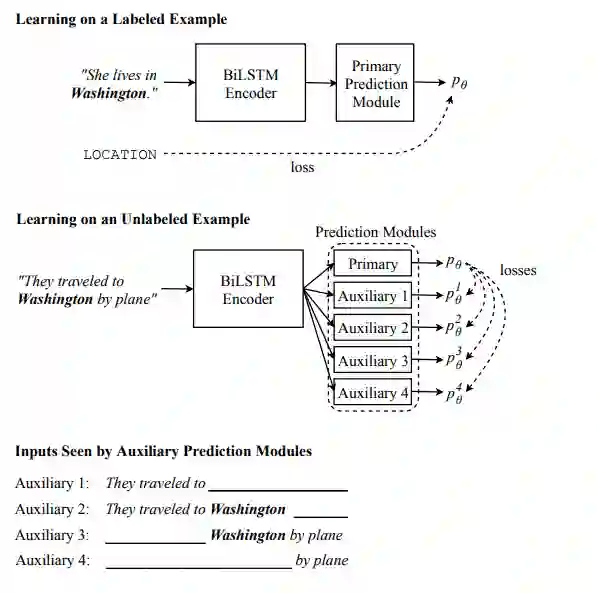
简单来说,这项技术假设你有一些有标注数据和大量无标注数据。你可以在有标注的数据批和无标注的数据批之间切换。在有标注的数据批上,网络按一般方式训练。在无标注的数据批上,仅有一部分输入的「辅助网络」会尝试预测整个模型会根据整个输入预测出什么结果。因为每个辅助网络只能看到输入的一个不同的部分,因为每个辅助网络都必须学习补偿缺失的部分。但因为辅助网络和主网络的权重是共享的,因此整个模型都能从中受益。关键的是,从 softmax 的角度看,在辅助步骤计算的损失是每个网络预测的 KL 距离(较小的 softmax),而不是在整个词汇库上计算得到的。
总结
文章挺长,这里我们简单总结一下。字符级模型能解决词级模型的一些问题。值得提及的是,它们让我们可以处理几乎任意大的词汇库,并让预训练或联合训练语言模型的成本降至可接受的范围。尽管有这些潜力,它们在实践中的效果还并不明朗。我们看到了 Andrej Karpathy 和 OpenAI 在字符级语言模型上的研究成果,也见识了 DeepMind 的字符级翻译系统。这些研究表明字符级模型可以理解文本中的语义。
我们也介绍了字符级模型的一些缺点,包括有效序列规模的倍数增长、字符中固有含义的缺乏以及它们与我们想要实现的实际语言目标的距离。
最后,我们介绍了一些字符级模型的替代方法,我们看到有一些嵌入方法使用了子词单元以及弥补缺点的模型架构。我们还看到有些方法试图绕过使用 softmax 方法进行语言建模的成本——不管是通过近似 softmax 本身,还是稍微修改语言建模任务。
在 LightTag,字符级模型为我们提供了很好的服务——它们可适应多个语言领域,训练轻松且快速,而且没有需要管理的外部依赖。和生活中的一切事情一样,选择你的模型所处理的基本单位是一个权衡。既然你已经读到了这里,相信对于如何在你自己的用例中如何选择,你已经有了自己的看法。

原文链接:https://www.lighttag.io/blog/character-level-NLP/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


