美图个性化推送的 AI 探索之路

分享嘉宾:周燕稳、蒋文瑞 美图
文章整理:李元
内容来源:DataFunLive
出品平台:DataFun
注:欢迎转载,转载请在留言区留言。
导读:Push 作为一种有效的拉起 DAU 和召回用户的策略,近几年来被各类社交 App 广泛应用,随着深度神经网络在语音和图像识别上取得的巨大成功,AlphaGo 战胜人类围棋顶尖高手,以深度网络为基础的人工智能迎来第三次高潮。如何将深度模型应用于个性化 push 场景,从而减少无效 push 对用户的骚扰,是近年来一个关注的热点。本次分享将结合美图的实际业务场景从 Embedding、召回、排序、文案、内容池等多个方面介绍如何打造一个良好的 push 场景。
本次分享的内容概要如下:

1. 业务背景
Push 也就是推送通知,可以通过系统界面直接触达用户,当用户点击就会唤醒 APP,是提高 APP 的日活,留存等指指标重要的环节之一。
2. Embedding 演进
首先,我们介绍 Embedding 的过程。从三个算法层面介绍 embedding:Word2Vec,Listing Embedding ( 参考 Airbnb ) 在个性化 push 的应用,以及近两年流行的图相关的算法 GCNs。
2.1 Word2Vec

- Feed 也就是展示页的一个 item,对于美图秀秀来说就是用户发的一张图,对于电商来说就是一个商品,本文统一称为 feed。
- Embedding 就是把任何一个 Feed 转化为一个向量,服务于后面的召回和排序。Embedding 是比较基础的过程,在最开始阶段,我们尝试了最基础的 Work2Vec 中的 Skip-Gram 的模型,通过对于用户的点击序列模仿 Work2Vec 中的一个句子。如图所示,我们有序列之后,定义窗口大小,通过中心词,就会得到 Train Sample。紧接着定义单侧窗口大小为2,就可以得到样本对,把样本对输入模型,就可以返回向量。
在实验中,我们采用了60天的点击序列,输出向量设置为100维。
2.2 Airbnb Listing Embedding
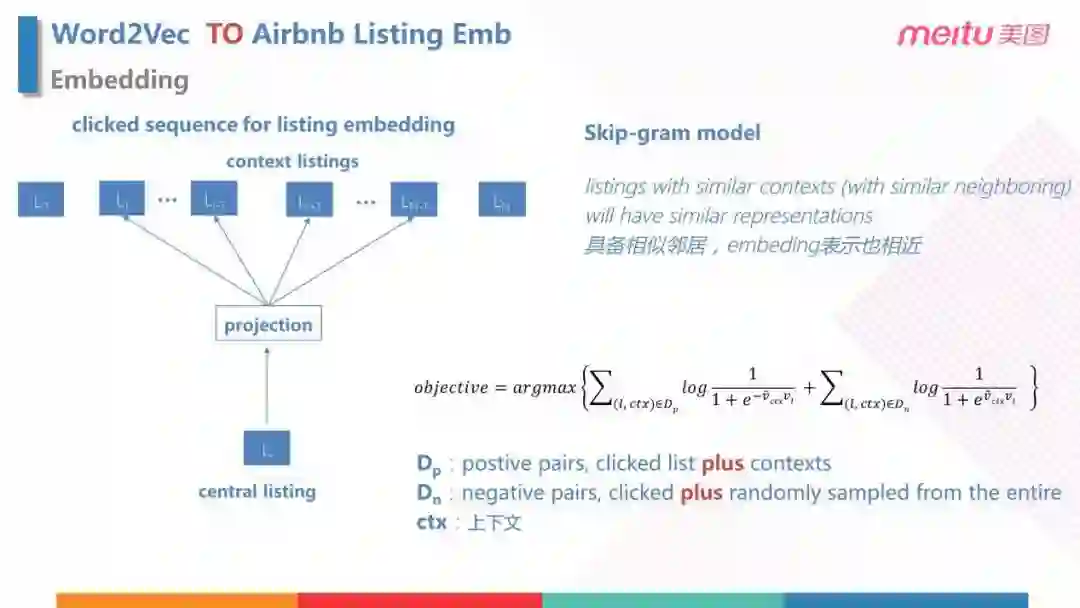
Airbnb listing Embedding 是2018年 KDD 的最佳论文,这里和 Word2Vec 主要的区别在于损失函数,模型本身和 Word2Vec 是保持一致的,所以我们先看 Word2Vec 的损失函数:
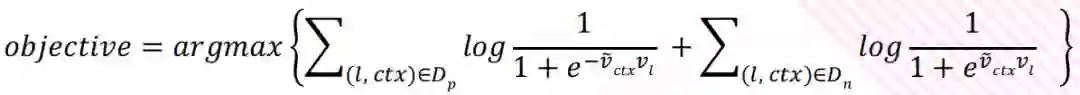
损失函数由正负样本两部分组成,正样本对 Dp 来源于用户点击流生成的 item pair,负样本对 Dn 通过当前的 item + 随机采样空间的其他 item ( 这里假设随机采样的样本不是当前 item 的邻居 ),ctx 表示上下文。这里需要注意的是在 log 里,正样本前面有负号,负样本没有负号。
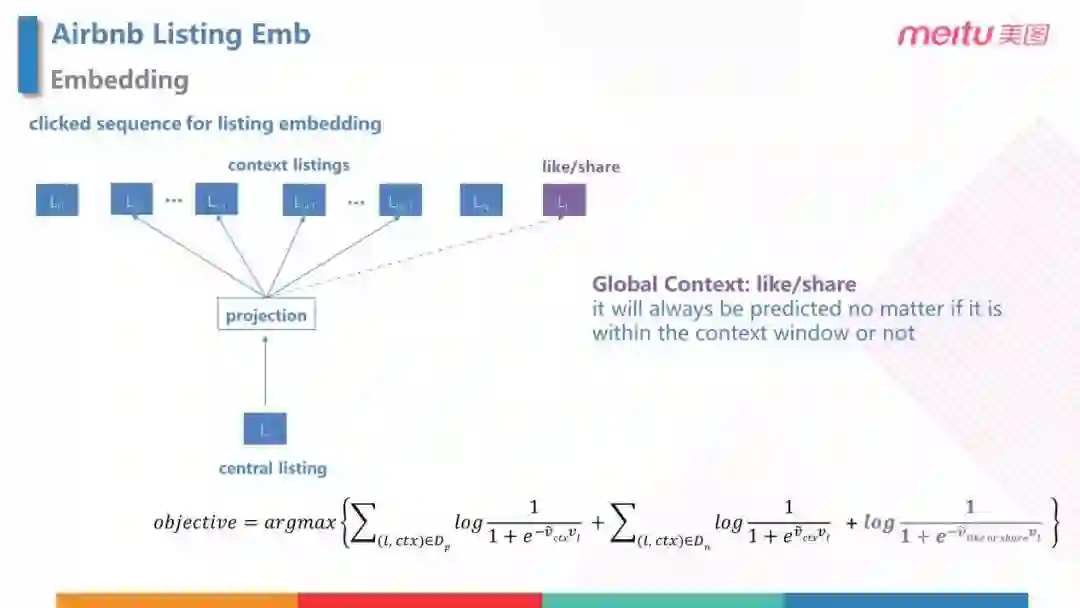
但是,之前的构造只用了用户的点击数据,实际上用户还有点赞、分享等行为数据可以利用。所以,在 Airbnb listing Embedding 中,加入了 Global Context 这样一个概念:通过用户历史的点赞、分享对应的 feed,与当前的 feed 构造出全局正样本对,使这些 feed 在点击序列上和当前的 feed 并不相邻, 加入到损失函数中。( 如公式中的紫色部分 )
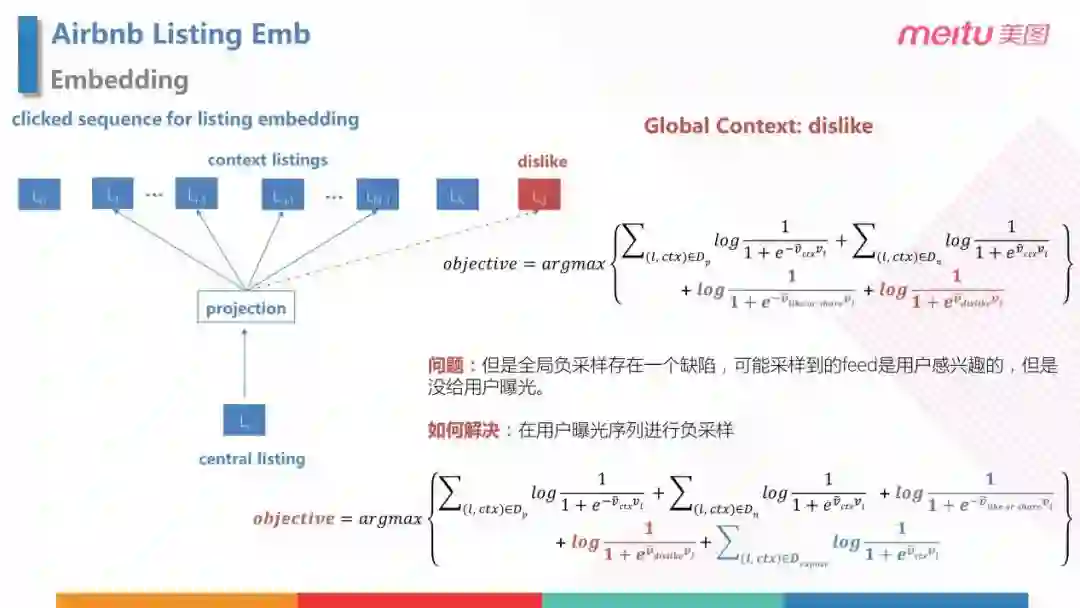
同理,我们可以通过用户的点击"不喜欢"的行为来构造负样本 ( 如公式中的红色部分 )。除此之外,用户的浏览过,但是没有点击的 feed 也可以随机采样之后当做负样本,加入到损失函数中 ( 如公式中的蓝色部分 )。
这样,就把 Airbnb listing Embedding 的策略引入到了美图秀秀的场景里。
2.3 Graph Embedding
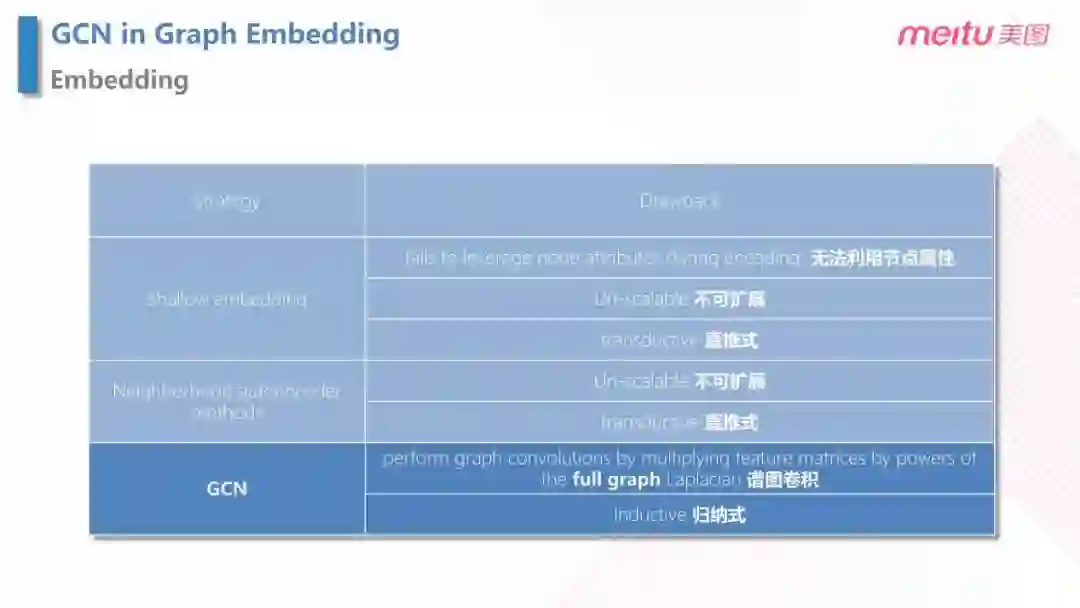
Graph Embedding 是近几年比较流行的 Embedding 方法,主要策略可以分为三类:Shallow Embedding,Neighborhood autoencoder methods 和 GCN 的方法。但是前两种方法涉及到不可拓展和直推式的缺陷,GCN 可以避免以上的缺陷。
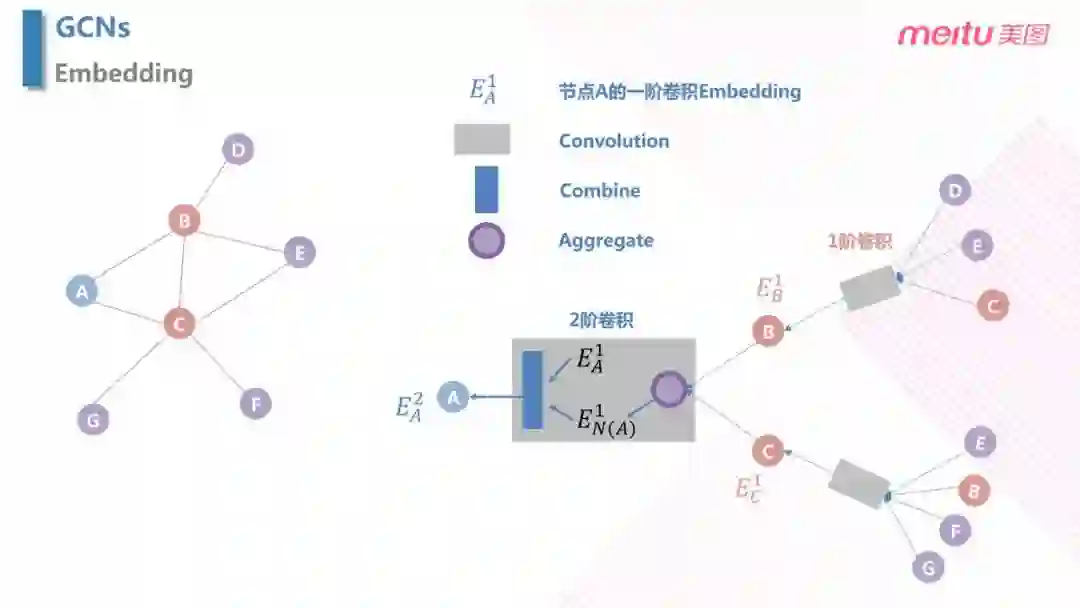
前面两种 Embedding 只对行为序列本身进行了建模,但是没有考虑节点本身的特征;另外,在之后的排序模型中,排序模型使用了 item 的自身属性进行排序。GCN 就是把用户行为和 item 本身的特征联合起来,既能用上图的拓扑结构,又可以把握属性特征,把信息融合起来做 Embedding。在上图中,假设我们要计算 A 的 Embedding,可以通过计算 A 的一阶近邻 BC 的信息聚合得到 Aggregate,而 BC 的信息可以由二阶近邻 DEC,EBFG 的信息计算卷积 ( Convolution ) 计算得到。

具体来说,延展的过程中,主要包括对于高阶信息的汇总 Aggregate,以及当前阶和邻阶节点上一阶的卷积之间信息的结合 Combine。其中,Combine 可以有很多操作,比如拼接,求和等。Aggregate 的过程中,需要注意的一点是采用了 Importance pooling,这里并不会对每个邻居节点都汇总,而是先计算一个Importance Factor ( 影响力因子 ),影响力因子小于阈值的不参与加权,最后根据权重去加权求和。
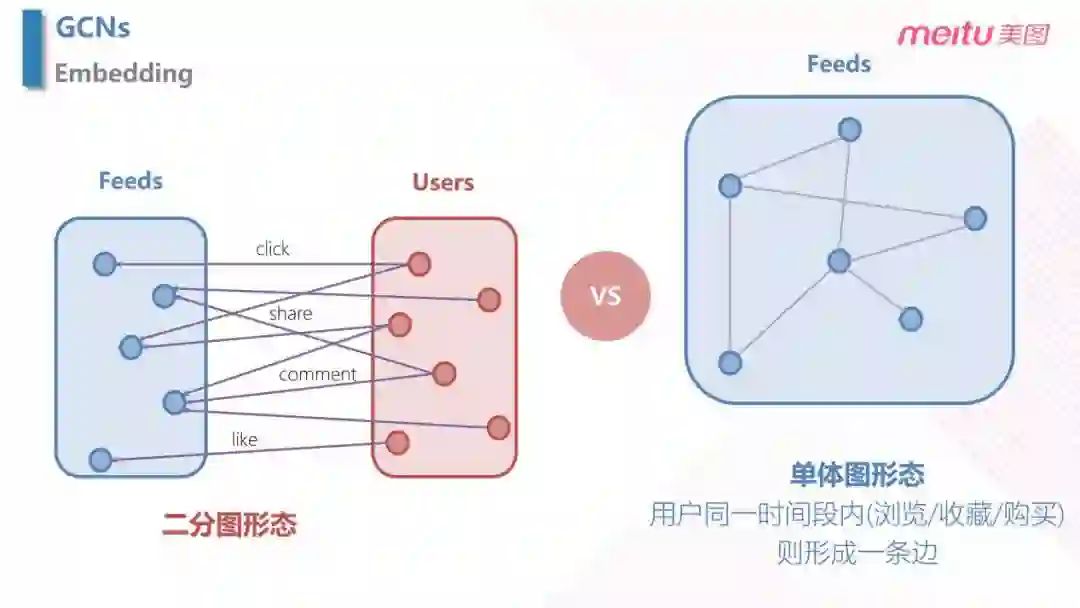
构件图的不同形态:
- 二分图形态:两种类型 ( Feeds,User ) 内部之间没有边,不同类型之间才有边;
- 单体图形态:根据用户同一时间段的行为,将 Feeds 之间关联起来。
到此为止,我们介绍了 Embedding 所尝试的方法。
3. 召回模型

召回主要采用了四个方面:全局召回 ( 热榜,热搜,热词 ),个性化召回 ( 根据用户的行为,兴趣进行召回 ),属性召回 ( 也就是画像召回,通过机型,性别,年龄等 ),最后是相关召回 ( 包括相似,关键词召回等 )。
3.1 个性化召回之 YoutubeNet
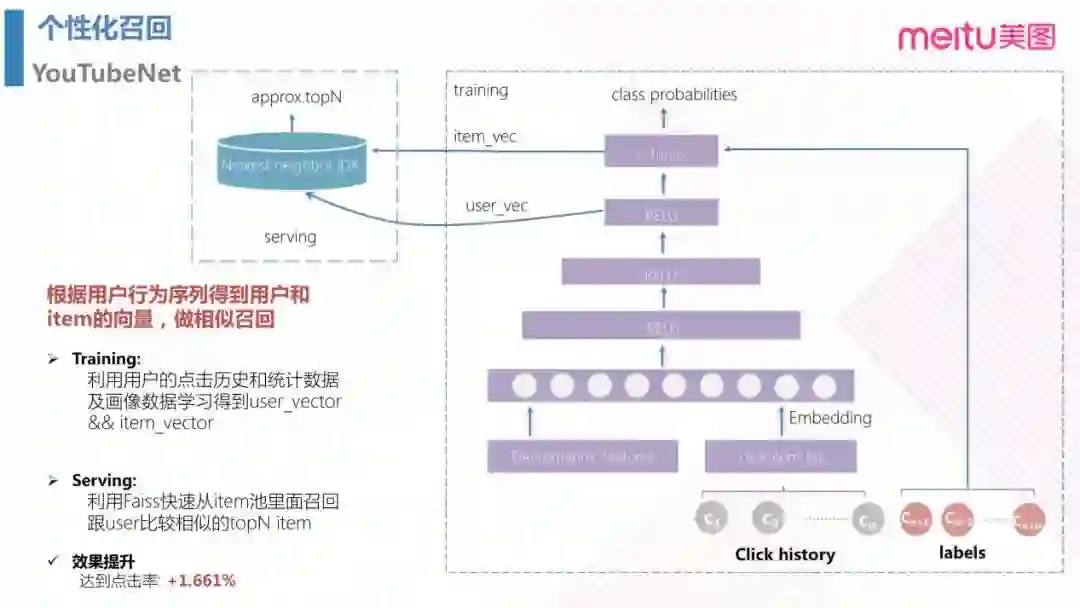
YoutubeNet 是近两年比较流行的算法,它既可以做召回,也可以做排序。通过输入用户的行为序列得到用户和 item 的向量,然后就可以通过向量相似程度,对每个 user 相似的 topN 个 item 进行个性化召回,实验中到达点击率提升了1.661%。
3.2 个性化召回之聚类召回
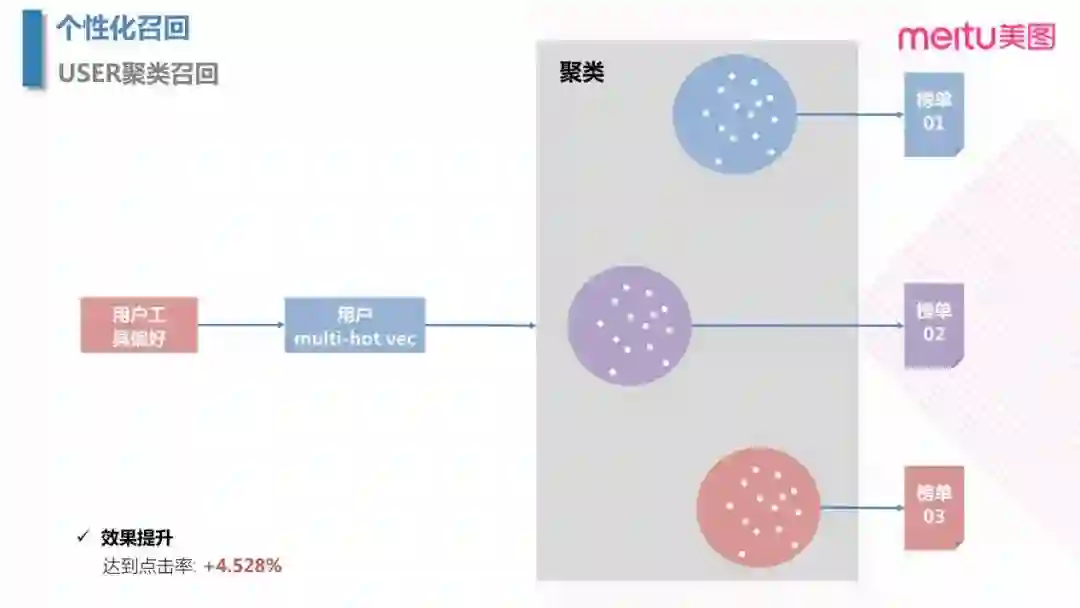
业务上,push 也包含一个任务是实现将"工具类用户"转化成"社交类用户",从而提高长期的 DAU。在聚类召回阶段,可以通过对于用户的工具偏好特征去构建 multi-hot 的向量,然后进行用户群聚类,对于每个特定的用户群召回对应的榜单。
3.3 相关召回之相似召回
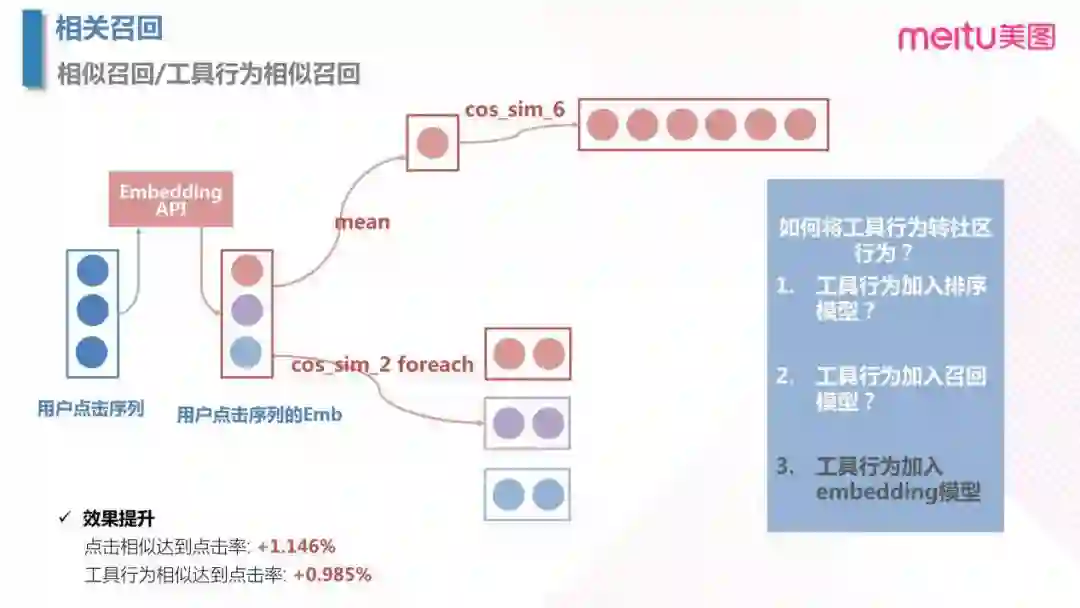
相关召回在美图秀秀中是输出用户近期的 item 点击流,获取了对应的 Embedding 之后,可以通过计算 Embedding 的均值然后找余弦距离最小的候选项;或者直接将每个候选项去找余弦距离最小的候选项,最后进行汇总。这里值得思考的一个问题是,何时利用好工具行为的特征,是在排序阶段,召回阶段,还是生成 Embedding 的阶段?经过实验,得到在 Embedding 阶段使用工具行为特征效果最好。
3.4 相关召回之聚类召回

聚类召回主要是为了实现多样性,避免同质化的内容。通过对 item 的 Embedding 进行聚类,相当于每个 item 多了一个分类标签。通过统计用户对于每个类别的行为记录次数,按照倒叙进行排列。在召回阶段,按照排列好的顺序依次从每一个类别中抽取一个 item,如果所有类别都抽了一遍,召回的数量仍然不够多,可以继续再抽一轮,直到候选数目足够。这样就实现了召回源的多样性。
3.5 相关召回之文案相关召回
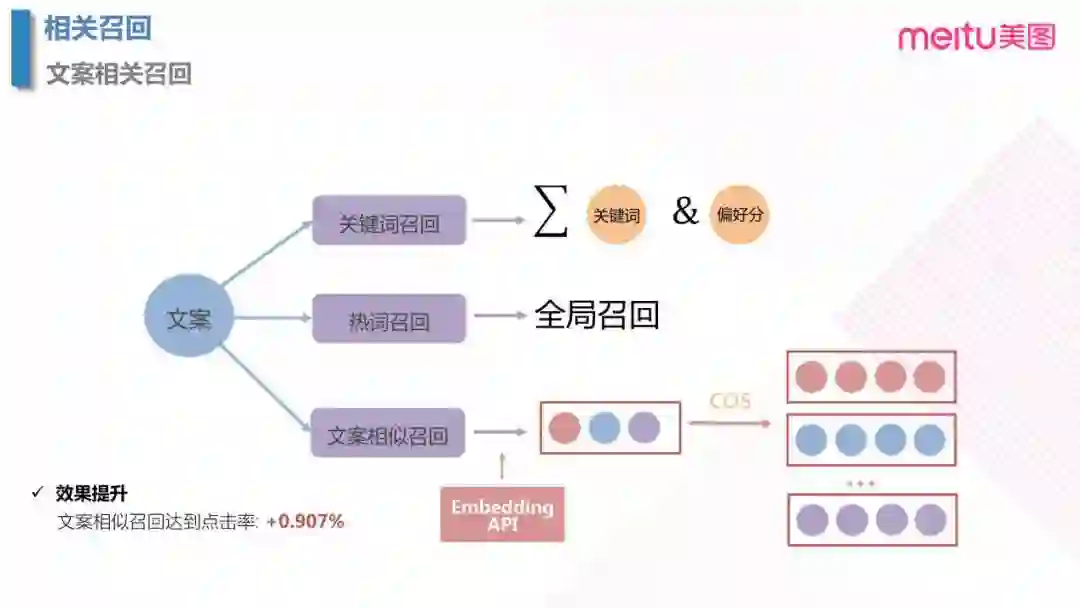
当选取候选 item 之后,发送 push 仍需要一条文字信息触达用户,这里简称文案。文案一般由编辑生成,会有很多候选项,所以也需要对文案进行建模召回。主要有以下三个方案:
- 关键词召回:通过对于历史的文案进行分词,得到每条文案的关键词,然后把用户对于文案的点击映射到对于关键词的点击,这样就能得到用户对于不同关键词的偏好。当我们新需要发送一条文案时,可以得到用户对于每条候选文案偏好度,召回偏好大的文案。
- 热词召回:通过计算全局哪些关键词最受欢迎,召回的过程中直接召回带有热门关键词的文案。
- 文案相似度召回:通过 NLP 的模型,比如 BERT,生成每一条对应的 Embedding,然后召回与用户点击过的文案余弦距离最小的文案。
以上,就是所有的召回部分。
4. 排序模型
4.1 LR 逻辑回归模型
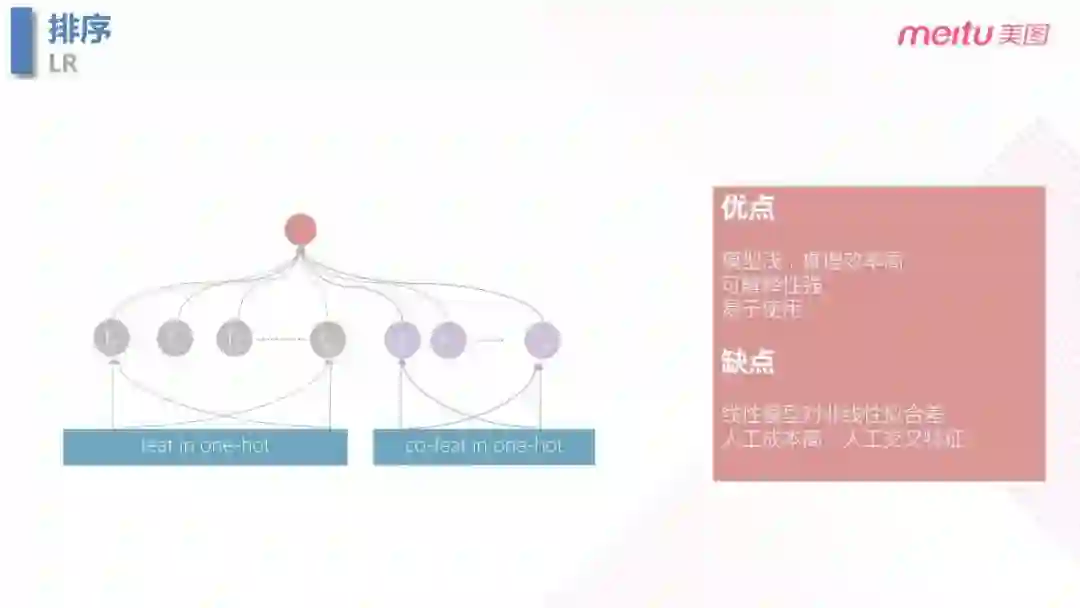
在排序模型的初始迭代阶段,使用了最简单的 LR 模型,LR 的模型优点是模型浅,计算简单,解释性强,易于使用。但是缺点也显而易见,LR 对于非线性特征拟合程度差;除此之外,交叉特征的生成依赖于大量尝试以及人工经验,所以尝试成本很高。
4.2 xNFM 模型
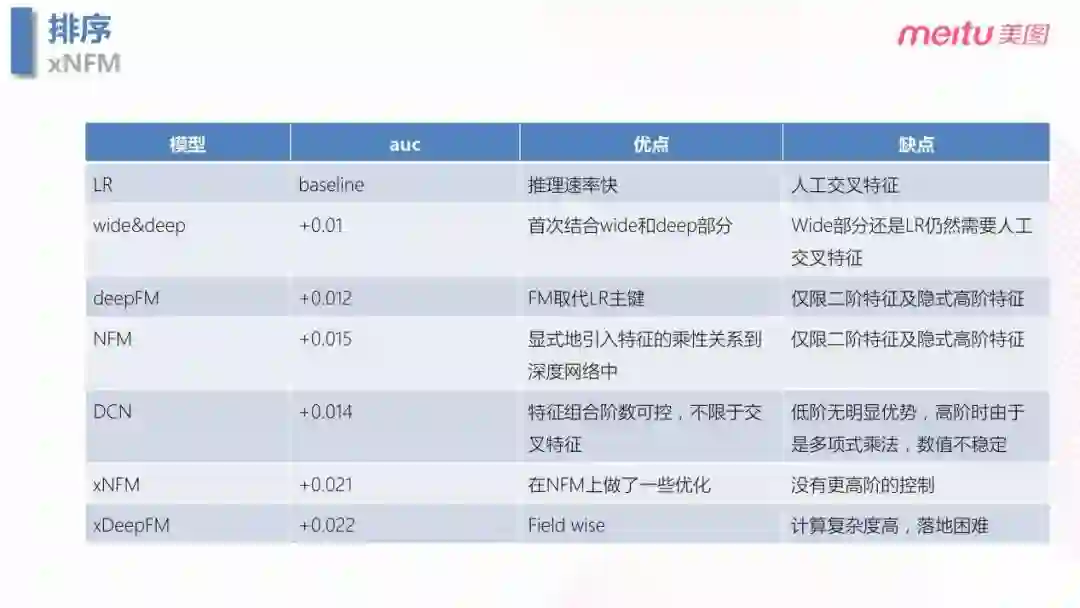
通过对于 LR,Wide&Deep,deepFM,NFM,DCN,xNFM,xDeepFM 模型的尝试与对比,最后选择的 xNFM 的模型。xNFM 优点是组合了一阶和二阶的特征的优点,性能上也可以达到工业落地的需求。
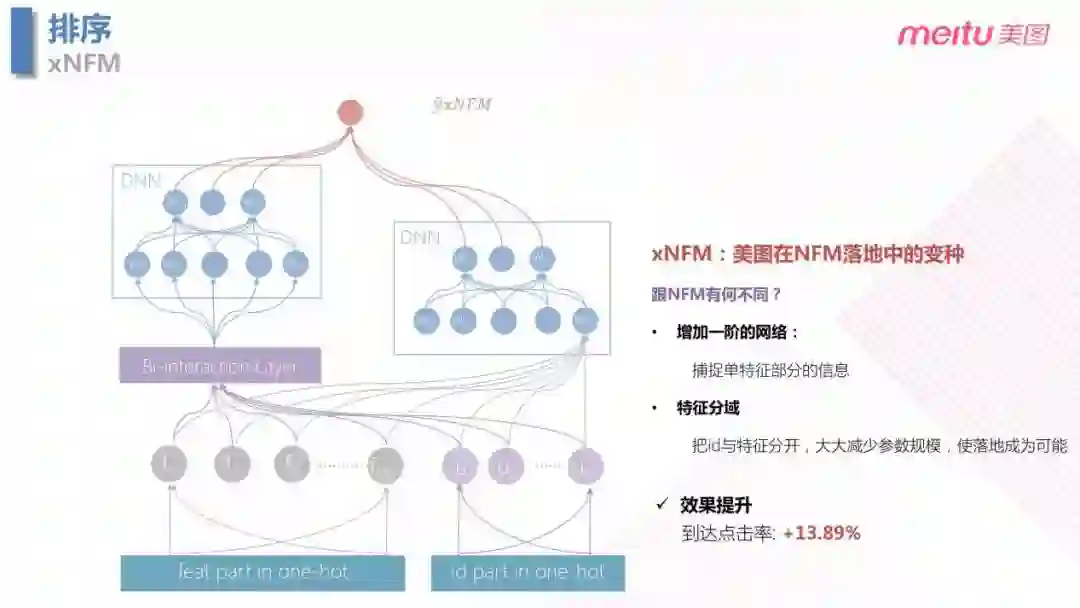
xNFM 不是业界主流的模型,而是在落地中对于 NFM 的变种。主要区别在于:
- 模型的输入端为了降低模型参数规模,把 id 类特征和非 id 类特征分别进行 Embedding,可以大大减少参数规模。
- 在上层网络,主要区别在于右侧。传统的 NFM 的弊端是只考虑了一个显性的二阶信息,而忽略了一阶信息 ( 单特征 ),所以我们增加了右边的网络用来捕捉单特征的信息。相比于 LR,提升效果明显,到达点击率提升13.89%。
4.3 双塔模型
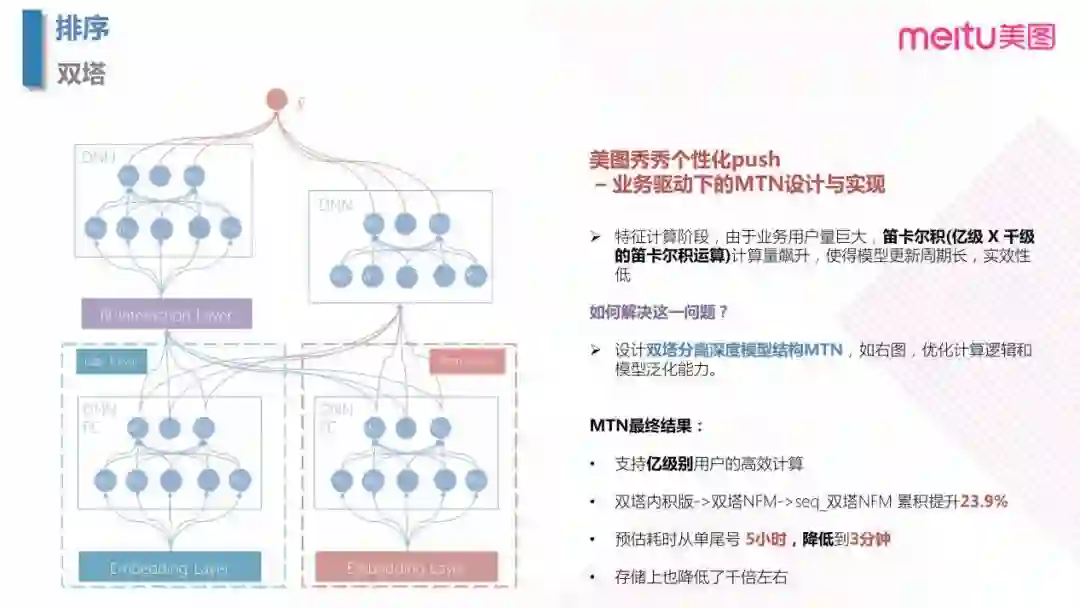
随着用户量的增加,计算量飙升,笛卡尔积之后会有千亿级别的计算量,使得模型更新周期变长,时效性降低。为了解决这个问题,我们提出了双塔的结构。双塔的结构特别在,当 user 和 item 分别构建一个 DNN 的全连接的网络。这样设计优化主要体现在工程性能方面,存储量大大降低,预测阶段耗时也降低,从而实现了支持亿级别的用户高效计算。从最初的双塔之后接入到内积,再到上图的双塔接入 NFM,到最后再加入点击序列的信息,三个版本的迭代最终点击率累计提升23.9%。
4.4 三塔模型
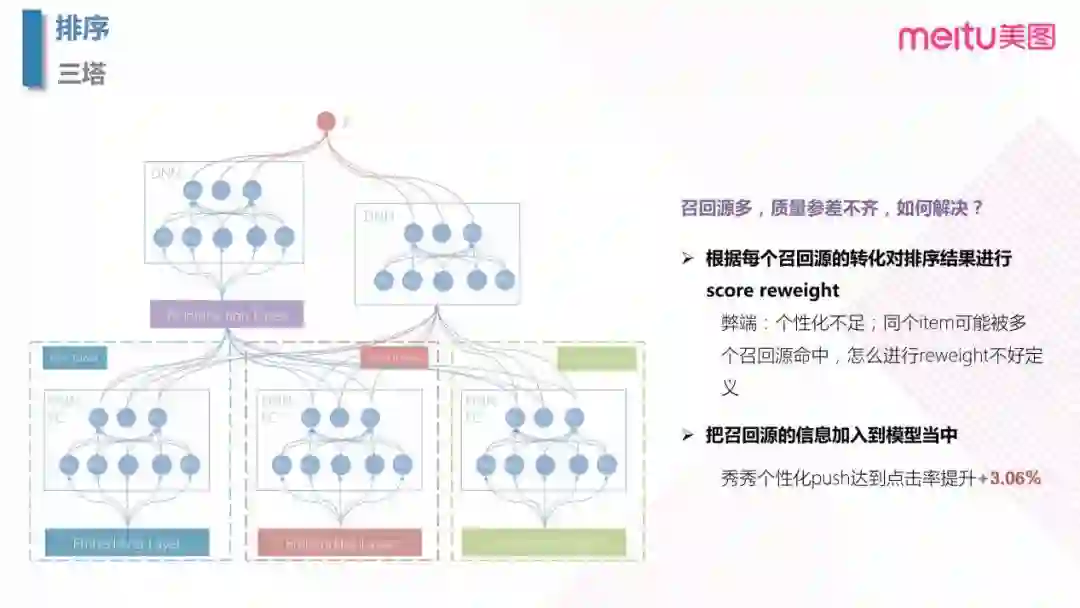
在之前也提到,我们有很多召回策略,但是召回源质量参差不齐,所以就需要解决对于召回源的选取。
- 最初的想法是根据每个召回源的转化对排序结果进行 socre reweight,但是弊端也很明显,因为召回源直接并不互斥,同个 item 会被多个召回源命中,所以 reweight 的规则也难以定义。
- 之后,为了个性化,直接把召回源信息加入到模型中。这里为什么不把召回源直接加入到 item 的特征中,而是单独的构造了一个塔呢?主要工程上的考虑,如果把召回源的信息加到 item 塔中,必须等 item 塔计算完成之后才能进行生产预测,会造成串行化,增加了延时。
增加了召回源信息之后,到达点击率提高了3.06%。
4.5 Field_wise 三塔模型
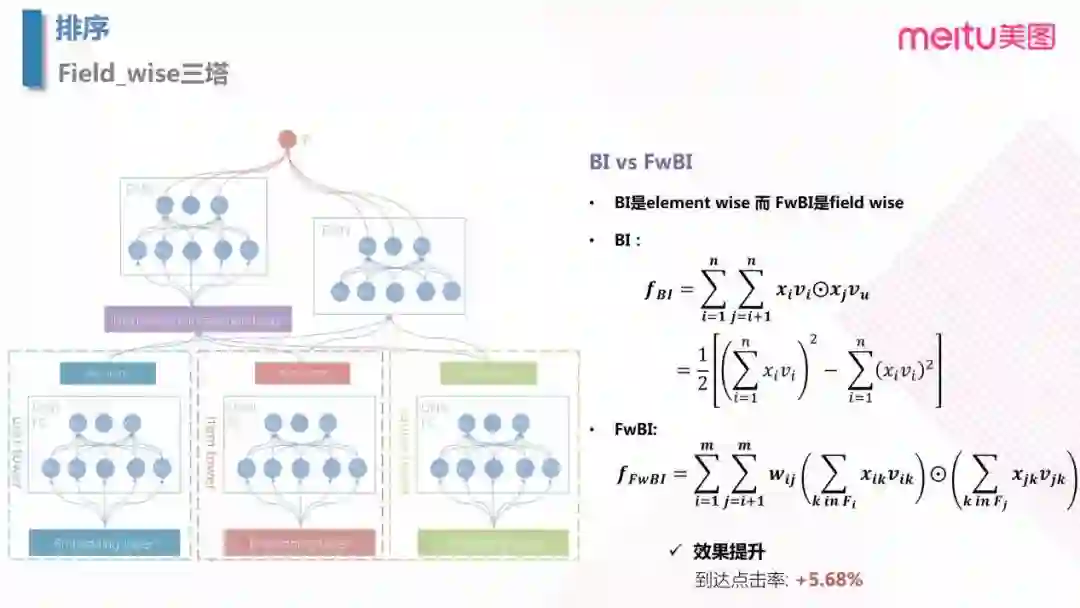
最后一版就是对于 NFM 模型的改进,在 NFM 左边的 Bi-Interaction Layer 中,BI 是 Bi-linear 的缩写,这一层其实是一个pooling层操作,它把很多个向量转换成一个向量,形式化如下:
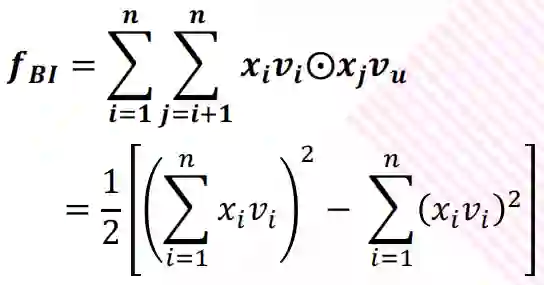
输入是整个的嵌入向量,xi,xj 是特征取值,vi,vu是特征对应的嵌入向量。中间的操作表示对应位置相乘。所以原始的嵌入向量任意两个都进行组合,对应位置相乘结果得到一个新向量;然后把这些新向量相加,就得到了 Bi-Interaction 的输出。这个输出只有一个向量。这里参考 FM 到 FFM 的改进过程,引入 Field 的概念。由于 BI 层不同的类别特征所表达是权重不相同,而 BI 层捕捉不到这个信息,所以可以对于每个向量相乘前可以加上权重。但是,这样会导致参数过多,而同属于一个 field 的变量权重应该相近,所以对于 BI 层进行同类别的权重 wi,j 共享而会使用相同参数的点积来计算:
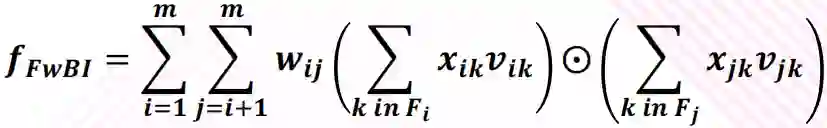
从而得到了 Fieldwise 三塔模型。模型上线后最终得到了到达点击率5.68%的提升。
5. 文章小节
到此为止,我们分别介绍了 Embedding,召回,排序三部分。Embedding 作为底层的服务辅助召回和排序,总共涵盖了 word2vec,airbnb listing embedding,GCNs 等几种不同策略;在召回部分,从不同场景与目标介绍了不同的召回策略;排序部分主要是模型由 LR 到 Field_wise 三塔模型的迭代过程,重点是如何解决特征生产阶段中耗时的笛卡尔积运算,使得一些更具规模的模型得以在线上业务投入生产。
今天的分享就到这里,谢谢大家。


分享嘉宾


——END——






