AliExpress:在检索式问答系统中应用迁移学习 | PaperDaily #24

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @Zsank。本文工作为第一作者在阿里实习时所完成。
工业界问答系统存在着特定领域标签数据的严重不足的问题,并且对响应速度有着比较严格的要求。
针对第一个问题,作者使用了迁移学习框架,并在传统迁移学习框架上引入了一个半正定协方差矩阵来对领域内及领域间信息权重进行建模;针对第二个问题,作者放弃了精度更高但耗时很长的 LSTM-based 模型,采用了精度稍低但速度更快的 CNN 模型。
作者除了在线下对语义识别(Paraphrase Identification)任务和自然语言推断(Natural Language Inference)任务进行实验外,还发布到 AliExpress 上进行在线评测。
本文模型除了在准确率、精度等方面稍逊于 state-of-art LSTM-based 模型外,均好于其他的对比模型,并且响应时间快,能满足工业用需求。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:麦振生,中山大学数据科学与计算机学院硕士生,研究方向为自然语言处理和问答系统。
■ 论文 | Modelling Domain Relationships for Transfer Learning on Retrieval-based Question Answering Systems in E-commerce
■ 链接 | https://www.paperweekly.site/papers/1312
■ 作者 | Zsank
文章亮点
在传统迁移学习的框架上,引入了半正定协方差矩阵,对输出层的域内以及域间信息权重进行建模;
鉴于工业界对响应时间的追求,放弃了精度更高的 LSTM,而采用基于句子编码的 CNN 和基于句子交互的 CNN 混合;
引入对抗损失,增强 shared 层的抗噪能力。
模型介绍
1. 问答系统工作流程
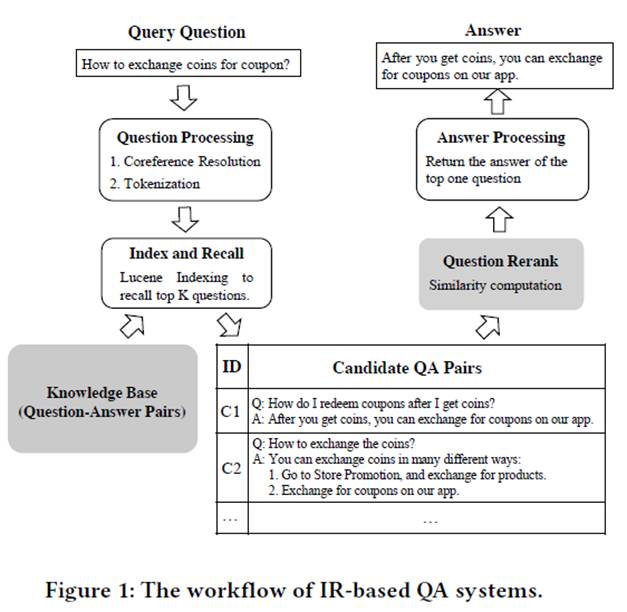
如图所示,用户提出 Query Question,进行预处理后,从 QA Pair 数据库中使用 Lucene 工具检索出 k 个最相关的 QA 对,然后对相关问题进行排序,返回最相关问题的回答。 使用到的技术有语义识别(Paraphrase Identification)和自然语言推理(Natural Language Inference)。
2. 传统迁移学习的不足
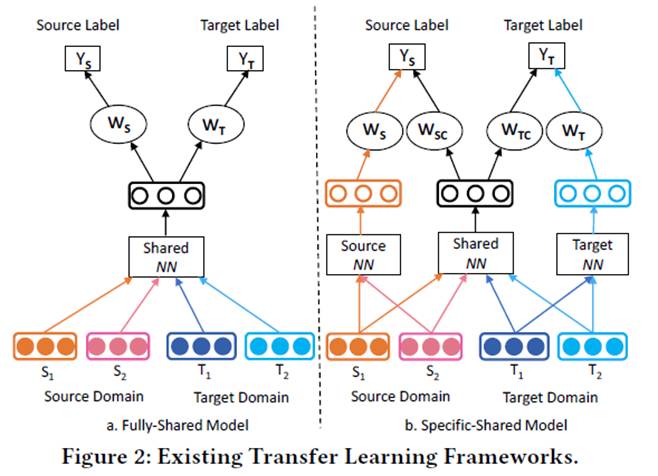
图中显示了两种现行的迁移学习框架。左图为全共享模型,作者认为它忽略了域内的特征信息;右图为 specifc-shared 模型,尽管考虑了域内以及域间的信息,但没有考虑它们之间的权重关系,即 Ws 与 Wsc 之间、Wt 与 Wtc 之间应该有关联。由此,引入了协方差矩阵 Ω 对这种关系进行建模。
3. 问题定义
给定两个句子:
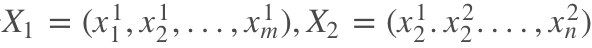
预测标签 y。
4. 模型图
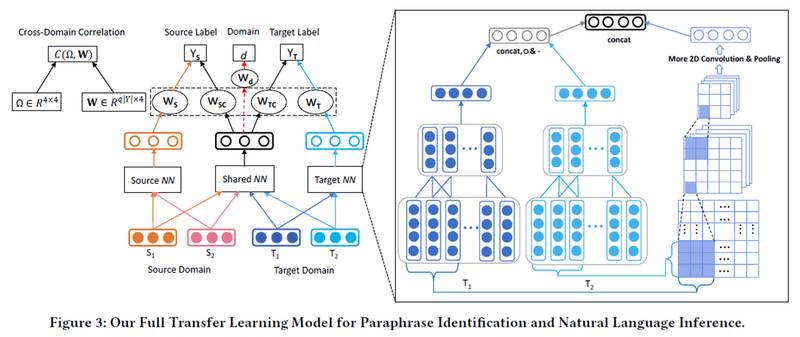
由中间部分即为 specific-shared 框架,在 sourceNN、sharedNN 以及 targetNN 中换成右边方框内所示的混合 CNN 模型(基于句子编码的、基于句子交互的)。
中间为了提高 sharedNN 层的抗噪能力,增加了一个分类器,由此引入对抗损失函数。
左上角部分即为权重以及半正定协方差矩阵的关系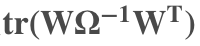
定义为 Wi 和 Wj 的关系,Wi、Wj 即为上面提到的 Ws、Wsc、Wt 与 Wtc。
文章的损失函数看起来很长,但其实就是两个交叉熵的和,加上其他所有参数的正则项。训练时作者使用了一个数学上的 trick:固定 Ω 后的损失函数是平滑函数,可以很方便地对所有参数求偏导。然后再固定其他参数更新 Ω。
实验结果
1. 基础模型比较
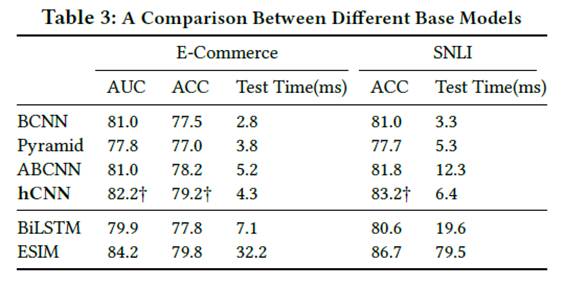
表格第二栏表示 CNN-based 模型,第三栏表示 LSTM-based 模型。 可见文中所采用的 hCNN 模型表现次好,但响应时间比第一好的 ESIM 快很多,所以综合表现最好。
2. 迁移学习框架比较
在 PI 任务上: 使用 Quora 数据集作为 source 数据集,爬取阿里线上的对话作为 target 数据集。数据统计如下表:

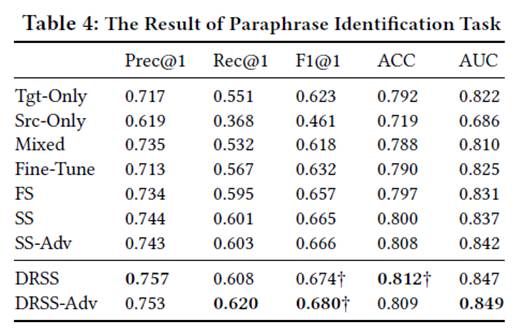
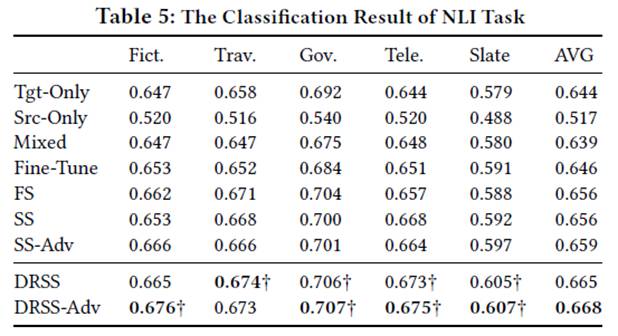
实验结果:(DRSS为本文采用的框架)
NLI 任务上: 使用 SNLI 数据集作为 source 数据集,其他五个数据集作为 target 数据集。
实验结果如下:(只用 ACC 进行评估)
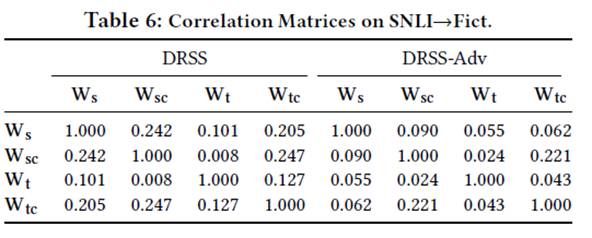
对协方差矩阵每个值取平方,作热图如下:

可以看到,Wsc 和 Wtc 正相关;Ws 和 Wsc 之间、Wt 和 Wtc 之间相关度很小。使用
数字化:
3. 在线评测

GBDT 为 AliExpress 现用的方法,文中模型精度相对 GBDT 提高较多,虽然损耗了一些时间,但每个问题响应 80 毫秒对于工业用 chatbot 来说,还是在可接受范围内。
文章评价
本人以前没有接触过迁移学习,但这篇文章对迁移学习的介绍很清晰,能给我个迁移学习大体的框架和思路。另外,引入协方差矩阵这个想法很有创意,实验证明也很有用,对域内域间信息有了直观的解释。并且本文的模型也基本达到了工业界对精度和速度之间平衡的要求。难得的一篇对学术和对工业都有贡献的文章。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!
我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot01)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文





