NLP多任务学习:一种层次增长的神经网络结构 | PaperDaily #16

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
由于神经网络强大的表达能力,在 NLP 领域研究者们开始研究基于神经网络的多任务学习。大多数方法通过网络参数共享来学习任务间的关联,提升各任务效果。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @robertdlut。这篇文章介绍了一个联合的多任务(joint many-task)模型,通过逐步加深层数来解决复杂任务。
与传统的并行多任务学习不一样的地方在于,该文是根据任务的层次关系构建层次(POS->CHUNK->DEP->Related->Entailment)的模型进行学习。每个任务有自己的目标函数,最后取得了不错的效果。该论文最后发表在了 EMNLP2017。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:罗凌,大连理工大学博士生,研究方向为深度学习,文本分类,实体识别和关系抽取。
■ 论文 | A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks
■ 链接 | https://www.paperweekly.site/papers/1049
■ 作者 | robertdlut
该论文一作来自于东京大学,是他在 Salesforce Research 实习时完成的工作,最后发表在 EMNLP2017。
1. 论文动机
在 NLP 领域,各个任务之间有着相互联系。研究者们通过多任务学习(Multiple-Task Learning)来促进任务间互相联系,提高各个任务的性能。目前现存的主流多任务框架多使用同样深度的模型,通过参数共享的方式并行地进行多任务学习,如下图。
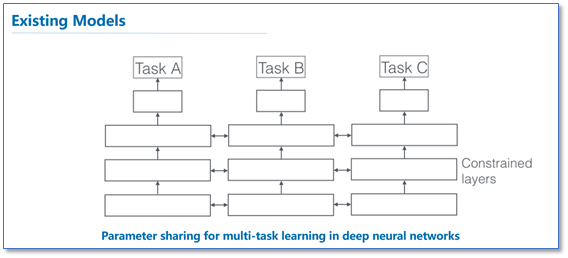
而在 NLP 领域中,各个任务间经常是有层级关系的,例如从词法分析到句法分析到上层的实际应用任务(例如具体任务:词性分析 POS->语块分析 CHUNK->依存句法分析 DEP->文本语义相关 Relatedness->文本蕴涵 Entailment)。
现存的多数多任务学习模型忽视了 NLP 任务之间的语言学层次关系,针对这一问题,该论文提出了一种层次增长的神经网络模型,考虑了任务间的语言学层次关系。
2. 论文方法
该论文模型的整体框架图如下所示,相比传统的并行多任务学习模型,该模型框架是依据语言学层次关系,将不同任务栈式的叠加,越层次的任务具有更深的网络结构。当前层次的任务会使用下一层次的任务输出。
在词和句法层级,每个任务分别是使用一个双向的 LSTM 进行建模。语义层级,根据前面层级任务学习到的表示,使用 softmax 函数进行分类。在训练阶段,每个任务都有自己相应的目标函数,使用所有任务训练数据,按照模型从底至顶的层次顺序,依次联合训练。
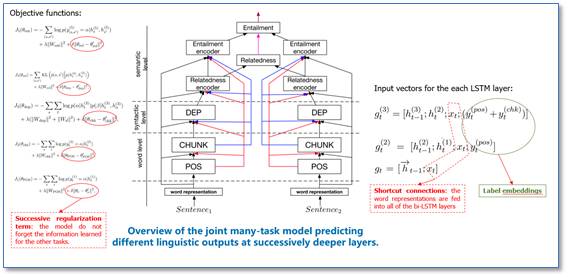
除此之外,在具体实现上,每层双向 LSTM 都用了词向量(Shortcut Connection)和前面任务的标签向量(Label Embedding)。在各个任务的目标函数里加入了级联正则化项(Successive Regularization)来使得模型不要忘记之前学习的信息。
3. 论文实验
各任务数据集:POS(WSJ),CHUNK(WSJ),DEP(WSJ),Relatedness(SICK),Entailment(SICK)。
多任务vs单任务(测试集上)
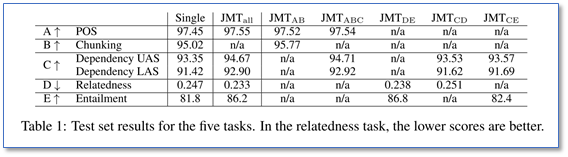
论文给出了多任务和单任务的实验结果(由于一些任务数据集存在重叠,所以没有结果 n/a),还有具体使用全部任务和任意任务的结果。可以看到相比单任务,多任务学习在所有任务上效果都得到了提升。
和主流方法进行比较(测试集上)
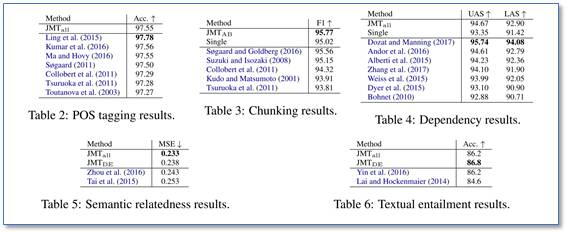
每个具体任务和目前主流方法(包含了并行的多任务学习方法)的比较,可以看到该论文每个任务的结果基本可以达到目前最优结果。
模型结构分析(在开发集上)
(1) shortcut 连接,输出标签向量和级联正则化项的效果
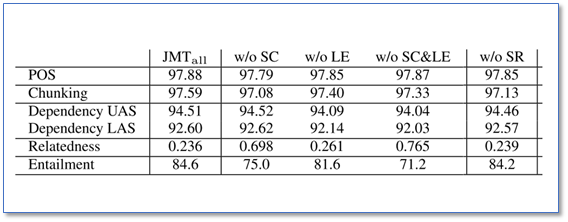
可以看到使用 shortcut 连接(Shortcut Connections, SR),输出标签向量(Label Embeddings, LE)和级联正则化(Successive Regularization, SR)能够提升任务的效果,特别是在高层的任务。
(2) 层次和平行结构的对比
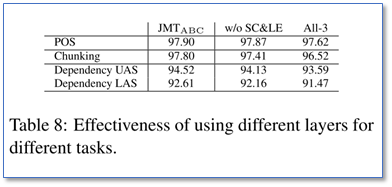
ALL-3 表示的是各个任务都用三层结构,只是输出不同,相当于平行多任务学习。可以看到该文层次的结构效果更好。
(3) 任务训练顺序的影响
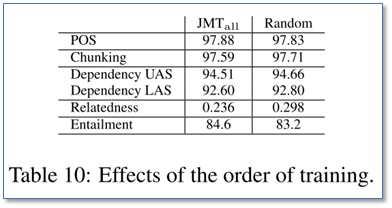
通过随机顺序和按照从底至顶的训练顺序结果进行比较,可以看出,从底层任务往高层任务顺序训练很重要,特别是对于高层任务。
4. 总结
该论文针对语言学层次结构,提出了层次结构的多任务学习框架。相比平行的多任务结构有更好的效果。这样的框架也可以扩展到更多高层任务应用上(例如关系抽取等)。
可以看到虽然框架思路简单,但是在实现要取得好的效果,我感觉很多论文中的细节需要注意(例如:Shortcut connections,Label Embeddings 和级联正则化项等)。论文的实验做得很详细,有些训练细节也在附加材料中给出,利于大家学习。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!
我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot01)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文



