.NET Core实践爬虫系统:自定义规则
(点击上方蓝字,可快速关注我们)
来源:从此启程
cnblogs.com/fancunwei/p/9588629.html
回顾
我们讲了利用HtmlAgilityPack,输入XPath路径,识别网页节点,获取我们需要的内容。评论中也得到了大家的一些支持与建议。
下面继续我们的爬虫系统实践之路。本篇文章不包含依赖注入/数据访问/UI界面等,只包含核心的爬虫相关知识,只能作为Demo使用,抛砖引玉,共同交流。
抽象规则
爬虫系统之所以重要,正是他能支持各种各样的数据。要支持识别数据,第一步就是要将规则剥离出来,支持用户自定义。
爬虫规则,实际上是跟商品有点类似,如动态属性,但也有它特殊的地方,如规则可以循环嵌套,递归,相互引用,链接可以无限下去抓取。更复杂的,就需要自然语言识别,语义分析等领域了。
我用PPT画了个演示图。用于演示支持分析文章,活动,天气等各种类型的规则。
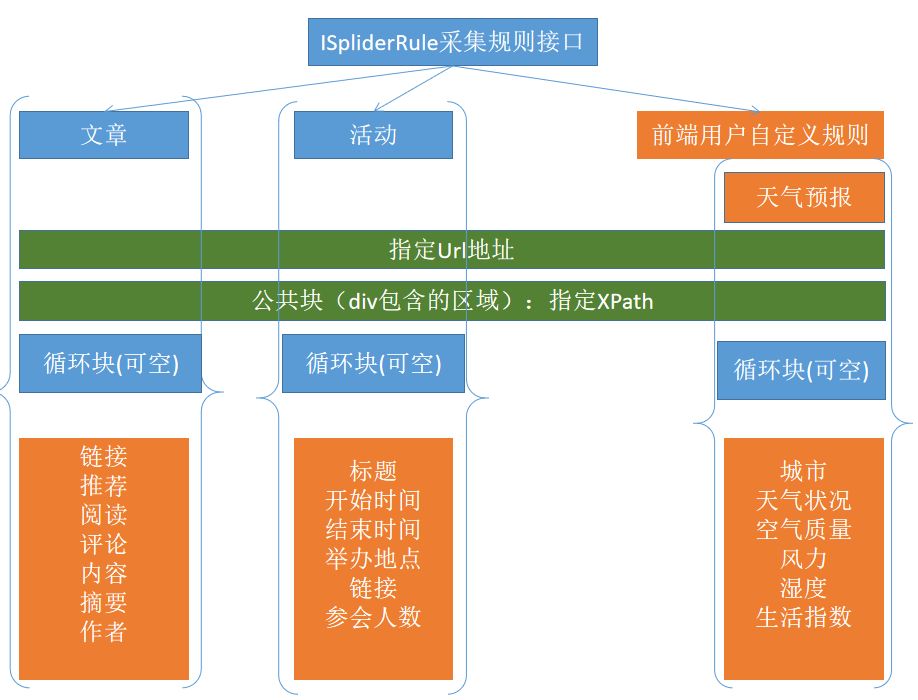
编码实现
先来定义个采集规则接口,根据规则获取单个或一批内容。
/// <summary>
/// 采集规则接口
/// </summary>
public interface IDataSplider
{
/// <summary>
/// 得到内容
/// </summary>
/// <param name="rule"></param>
/// <returns></returns>
List<SpliderContent> GetByRule(SpliderRule rule);
/// <summary>
/// 得到属性信息
/// </summary>
/// <param name="node"></param>
/// <param name="rule"></param>
/// <returns></returns>
List<Field> GetFields(HtmlNode node, SpliderRule rule);
}
必不可少的规则类,用来配置XPath根路径。
/// <summary>
/// 采集规则-能满足列表页/详情页。
/// </summary>
public class SpliderRule
{
public string Id { get; set; }
public string Url { get; set; }
/// <summary>
/// 网页块
/// </summary>
public string ContentXPath { get; set; }
/// <summary>
/// 支持列表式
/// </summary>
public string EachXPath { get; set; }
/// <summary>
///
/// </summary>
public List<RuleField> RuleFields { get; set; }
}
然后就是属性字段的自定义设置,这里根据内容特性,加入了正则支持。例如评论数是数字,可用正则筛选出数字。还有Attribute字段,用来获取node的Attribute信息。
/// <summary>
/// 自定义属性字段
/// </summary>
public class RuleField
{
public string Id { get; set; }
public string DisplayName { get; set; }
/// <summary>
/// 用于存储的别名
/// </summary>
public string FieldName { get; set; }
public string XPath { get; set; }
public string Attribute { get; set; }
/// <summary>
/// 针对获取的HTml正则过滤
/// </summary>
public string InnerHtmlRegex { get; set; }
/// <summary>
/// 针对获取的Text正则过滤
/// </summary>
public string InnerTextRegex { get; set; }
/// <summary>
/// 是否优先取InnerText
/// </summary>
public bool IsFirstInnerText { get; set; }
}
下面是根据文章爬虫规则的解析步骤,实现接口IDataSplider
/// <summary>
/// 支持列表和详情页
/// </summary>
public class ArticleSplider : IDataSplider
{
/// <summary>
/// 根据Rule
/// </summary>
/// <param name="rule"></param>
/// <returns></returns>
public List<SpliderContent> GetByRule(SpliderRule rule)
{
var url = rule.Url;
HtmlWeb web = new HtmlWeb();
//1.支持从web或本地path加载html
var htmlDoc = web.Load(url);
var contentnode = htmlDoc.DocumentNode.SelectSingleNode(rule.ContentXPath);
var list = new List<SpliderContent>();
//列表页
if (!string.IsNullOrWhiteSpace(rule.EachXPath))
{
var itemsNodes = contentnode.SelectNodes(rule.EachXPath);
foreach (var item in itemsNodes)
{
var fields = GetFields(item, rule);
list.Add(new SpliderContent()
{
Fields = fields,
SpliderRuleId = rule.Id
});
}
return list;
}
//详情页
var cfields = GetFields(contentnode, rule);
list.Add(new SpliderContent()
{
Fields = cfields,
SpliderRuleId = rule.Id
});
return list;
}
public List<Field> GetFields(HtmlNode item, SpliderRule rule)
{
var fields = new List<Field>();
foreach (var rulefield in rule.RuleFields)
{
var field = new Field() { DisplayName = rulefield.DisplayName, FieldName = "" };
var fieldnode = item.SelectSingleNode(rulefield.XPath);
if (fieldnode != null)
{
field.InnerHtml = fieldnode.InnerHtml;
field.InnerText = fieldnode.InnerText;
field.AfterRegexHtml = !string.IsNullOrWhiteSpace(rulefield.InnerHtmlRegex) ? Regex.Replace(fieldnode.InnerHtml, rulefield.InnerHtmlRegex, "") : fieldnode.InnerHtml;
field.AfterRegexText = !string.IsNullOrWhiteSpace(rulefield.InnerTextRegex) ? Regex.Replace(fieldnode.InnerText, rulefield.InnerTextRegex, "") : fieldnode.InnerText;
//field.AfterRegexHtml = Regex.Replace(fieldnode.InnerHtml, rulefield.InnerHtmlRegex, "");
//field.AfterRegexText = Regex.Replace(fieldnode.InnerText, rulefield.InnerTextRegex, "");
if (!string.IsNullOrWhiteSpace(rulefield.Attribute))
{
field.Value = fieldnode.Attributes[rulefield.Attribute].Value;
}
else
{
field.Value = rulefield.IsFirstInnerText ? field.AfterRegexText : field.AfterRegexHtml;
}
}
fields.Add(field);
}
return fields;
}
}
还是以博客园为例,配置内容和属性的自定义规则
/// <summary>
///
/// </summary>
public void RunArticleRule()
{
var postitembodyXPath = "div[@class='post_item_body']//";
var postitembodyFootXPath = postitembodyXPath+ "div[@class='post_item_foot']//";
var rule = new SpliderRule()
{
ContentXPath = "//div[@id='post_list']",
EachXPath = "div[@class='post_item']",
Url = "https://www.cnblogs.com",
RuleFields = new List<RuleField>() {
new RuleField(){ DisplayName="推荐", XPath="*//span[@class='diggnum']", IsFirstInnerText=true },
new RuleField(){ DisplayName="标题",XPath=postitembodyXPath+"a[@class='titlelnk']", IsFirstInnerText=true },
new RuleField(){ DisplayName="URL",XPath=postitembodyXPath+"a[@class='titlelnk']",Attribute="href", IsFirstInnerText=true },
new RuleField(){ DisplayName="简要",XPath=postitembodyXPath+"p[@class='post_item_summary']", IsFirstInnerText=true },
new RuleField(){ DisplayName="作者",XPath=postitembodyFootXPath+"a[@class='lightblue']", IsFirstInnerText=true },
new RuleField(){ DisplayName="作者URL",XPath=postitembodyFootXPath+"a[@class='lightblue']",Attribute="href", IsFirstInnerText=true },
new RuleField(){ DisplayName="讨论数", XPath="span[@class='article_comment']",IsFirstInnerText=true, InnerTextRegex=@"[^0-9]+" },
new RuleField(){ DisplayName="阅读数", XPath=postitembodyFootXPath+"span[@class='article_view']",IsFirstInnerText=true, InnerTextRegex=@"[^0-9]+" },
}
};
var splider = new ArticleSplider();
var list = splider.GetByRule(rule);
foreach (var item in list)
{
var msg = string.Empty;
item.Fields.ForEach(M =>
{
if (M.DisplayName != "简要" && !M.DisplayName.Contains("URL"))
{
msg += $"{M.DisplayName}:{M.Value}";
}
});
Console.WriteLine(msg);
}
}
运行效果
效果完美!
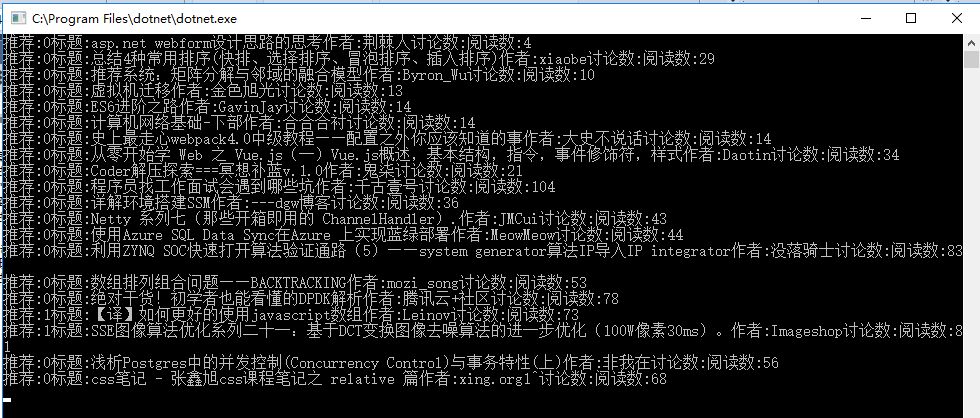
经过简单的重构,我们已经达到了上篇的效果。
常用规则模型和自定义规则模型
写到这里,我想到了一般UML图工具或Axsure原型等,都会内置各种常用组件,那么文章爬虫模型也是我们内置的一种常用组件了。
后续我们完全可以按照上面的套路支持其他模型。除了常用模型之外,在网页或客户端上,高级的爬虫工具会支持用户自定义配置,根据配置来获取内容。
上面的SpliderRule已经能支持大部分内容管理系统单页面抓取。但无法支持规则相互引用,然后根据抓取的内容引用配置规则继续抓取。(这里也许有什么专门的名词来描述:递归爬虫?)。
今天主要是在上篇文章的基础上重构而来,支持了规则配置。为了有点新意,就多提供两个配置例子吧。
例子1:文章详情
我们以上篇文章为例,获取文章详情。 主要结点是标题,内容。其他额外属性暂不处理。
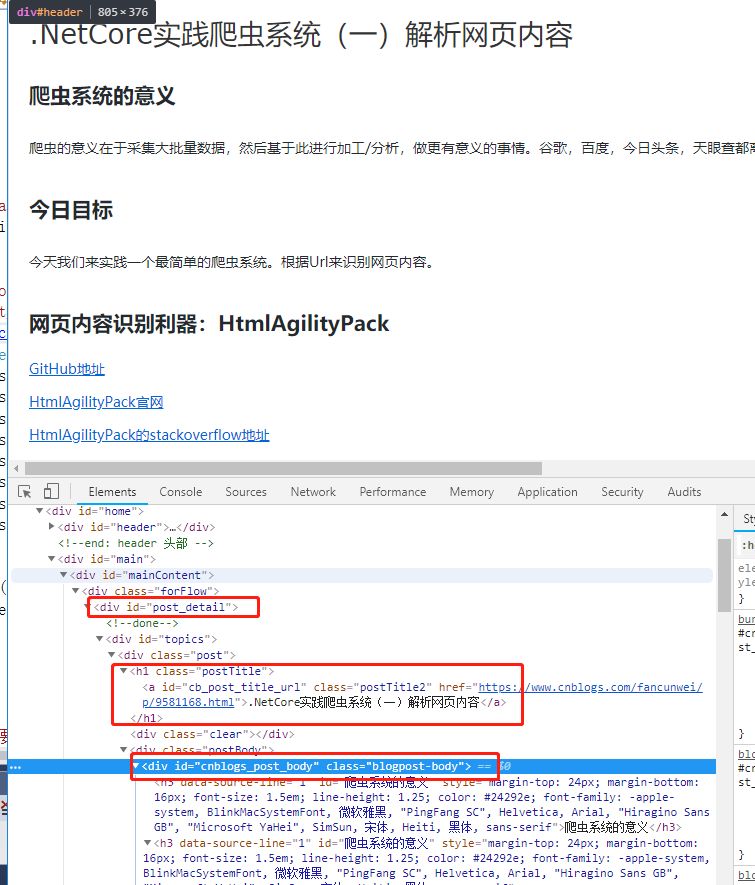
编码实现
/// <summary>
/// 详情
/// </summary>
public void RunArticleDetail() {
var rule = new SpliderRule()
{
ContentXPath = "//div[@id='post_detail']",
EachXPath = "",
Url = " https://www.cnblogs.com/fancunwei/p/9581168.html",
RuleFields = new List<RuleField>() {
new RuleField(){ DisplayName="标题",XPath="*//div[@class='post']//a[@id='cb_post_title_url']", IsFirstInnerText=true },
new RuleField(){ DisplayName="详情",XPath="*//div[@class='postBody']//div[@class='blogpost-body']",Attribute="", IsFirstInnerText=false }
}
};
var splider = new ArticleSplider();
var list = splider.GetByRule(rule);
foreach (var item in list)
{
var msg = string.Empty;
item.Fields.ForEach(M =>
{
Console.WriteLine($"{M.DisplayName}:{M.Value}");
});
Console.WriteLine(msg);
}
}
运行效果
效果同样完美!
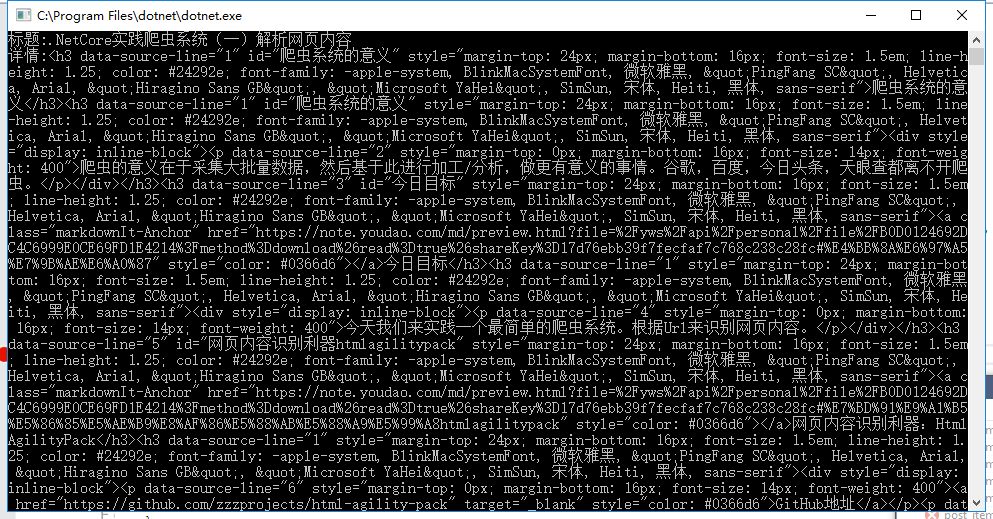
例子2:天气预报
天气预报的例子,我们就以上海8-15天预报为例。
分析结构
点击链接,我们发现 今天/7天/8-15天/40天分别是不同的路由页面,那就简单了,我们只考虑当前页面就行。
还有个问题,那个晴天雨天的图片,是按样式显示的。我们虽然能抓到html,但样式还未考虑,,HtmlAgilityPack应该有个从WebBrowser获取网页的,似乎能支持样式。本篇文章先跳过这个问题,以后再细究。
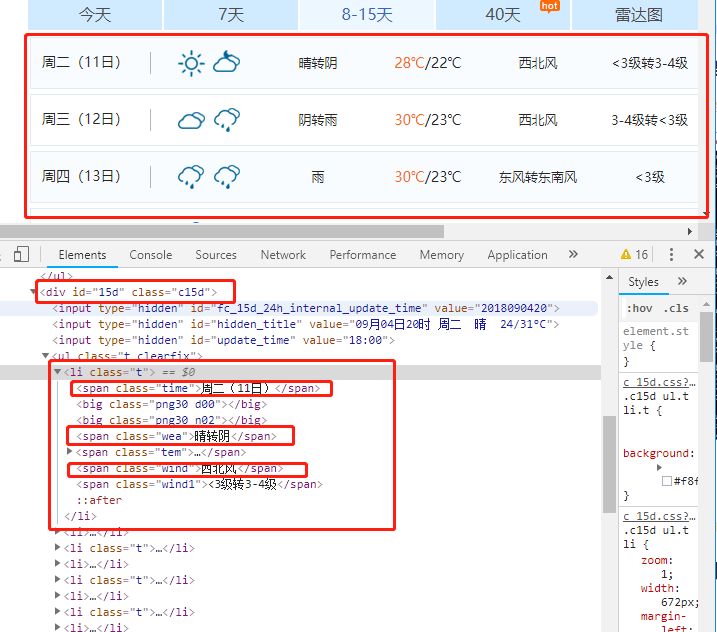
配置规则
根据网页结构,配置对应规则。
public void RunWeather()
{
var rule = new SpliderRule()
{
ContentXPath = "//div[@id='15d']",
EachXPath = "*//li",
Url = "http://www.weather.com.cn/weather15d/101020100.shtml",
RuleFields = new List<RuleField>() {
new RuleField(){ DisplayName="日期",XPath="span[@class='time']", IsFirstInnerText=true },
new RuleField(){ DisplayName="天气",XPath="span[@class='wea']",Attribute="", IsFirstInnerText=false },
new RuleField(){ DisplayName="区间",XPath="span[@class='tem']",Attribute="", IsFirstInnerText=false },
new RuleField(){ DisplayName="风向",XPath="span[@class='wind']",Attribute="", IsFirstInnerText=false },
new RuleField(){ DisplayName="风力",XPath="span[@class='wind1']",Attribute="", IsFirstInnerText=false },
}
};
var splider = new ArticleSplider();
var list = splider.GetByRule(rule);
foreach (var item in list)
{
var msg = string.Empty;
item.Fields.ForEach(M =>
{
msg += $"{M.DisplayName}:{M.Value} ";
});
Console.WriteLine(msg);
}
}
运行效果
效果再次完美!
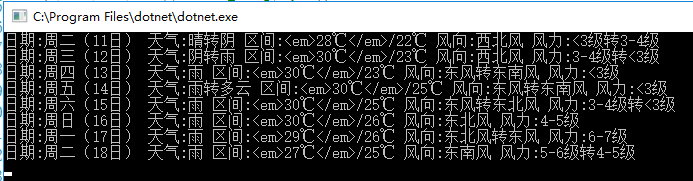
源码
代码已提交到GitHub:https://github.com/fancunwei/CsharpFanDemo
总结探讨
综上所述,我们实现单页面的自定义规则,但也遗留了一个小问题。天气预报晴天阴天效果图,原文是用样式展示的。
针对这种不规则问题,如果代码定制当然很容易,但如果做成通用,有什么好办法呢?请提出你的建议!
下篇文章,继续探讨多页面/递归爬虫自定义规则的实现。
看完本文有收获?请转发分享给更多人
关注「DotNet」,提升.Net技能







