从观察视频中重建动态三维人体表示是计算机视觉和图形学领域的前沿热点问题,是数字内容制作、远程虚拟会议、影视制作等应用的重要技术。传统的人体建模技术可以构建高精度的数字人体模型,但这些方法依赖于复杂的硬件设备,如深度相机、精密相机阵列,限制了这些工作的使用场景,并且提高了建模成本和用户门槛。近年来,神经辐射场展现了从观察图片中重建高质量三维场景的能力。但此类方法需要观测视图的输入,并且无法建模可驱动的动态人体模型。除此之外,此类方法的渲染速度较慢,无法满足实时应用的需求。
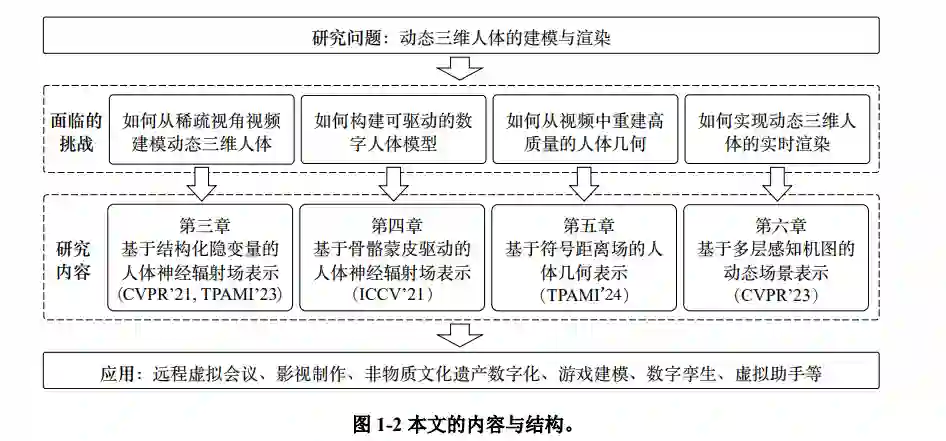
基于多视图几何理论与深度学习方法相结合的思想,本文提出了一系列面向结构化建模与渲染的隐式神经表示方法,致力于解决稀疏视角视频重建、可驱动人体模型、几何表面重建、实时渲染等可入人体建模领域的关键问题,实现了从稀疏视角视频中创建高质量的可驱动人体模型。本文主要的研究成果如下:
(1)针对从稀疏视角视频重建动态三维人体模型的问题,本文提出了一种基于结构化偏差变量的人体神经辐射场表示,可以有效地整合输入视频中不同时刻的观测信息。实验结果表明本方法可以从稀疏视角视频甚至单目视频中重建高质量的三维人体。
(2)针对可驱动的数字人体建模问题,本文提出了一种基于骨骼蒙皮驱动的人体神经辐射场表示,将动态人体建模为空间变形场和标准空间下的神经辐射场。本文在 Human3.6M 和 ZJU-MoCap 数据集上验证了该方法的有效性。
(3)针对从视频中重建高质量人体几何的问题,本文提出了一种基于符号距离场的动态人体几何表示,利用稀疏方程对几何优化过程施加正则化。在多个数据集上的实验结果表明,本方法在人体几何重建方面大幅度地超过了之前的方法。
(4)针对动态人体的实时渲染问题,本文提出了一种基于多层感知机的动态场景表示,通过一组少量多层感知机网络建模全动态场景,从而降低了网络的推理成本,提升了渲染速度。在 NHR 和 ZJU-MoCap 数据集上的实验结果表明,本方法在渲染速度方面远远超过了之前的方法,并且在渲染质量上表现出了最好的效果。
关键词:三维人体建模,隐式神经表示,神经渲染